L2MAC: Large Language Model Automatic Computer for Extensive Code Generation
2310.02003
2
0
Abstract
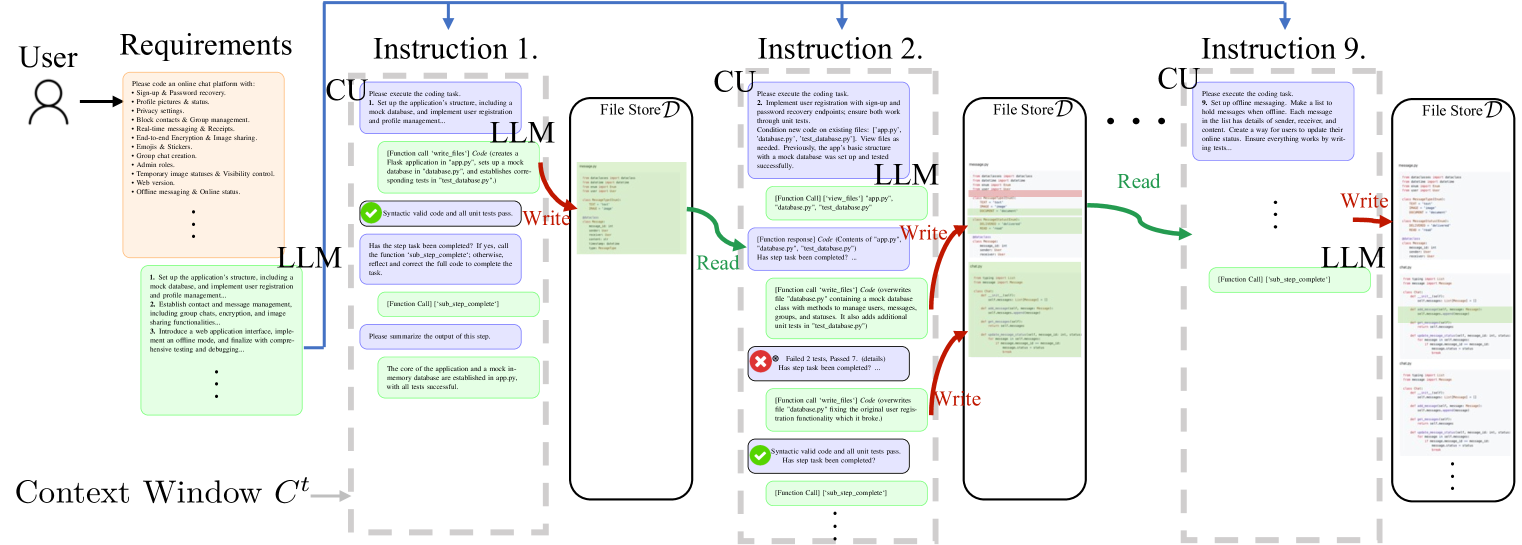
Transformer-based large language models (LLMs) are constrained by the fixed context window of the underlying transformer architecture, hindering their ability to produce long and coherent outputs. Memory-augmented LLMs are a promising solution, but current approaches cannot handle long output generation tasks since they (1) only focus on reading memory and reduce its evolution to the concatenation of new memories or (2) use very specialized memories that cannot adapt to other domains. This paper presents L2MAC, the first practical LLM-based general-purpose stored-program automatic computer (von Neumann architecture) framework, an LLM-based multi-agent system, for long and consistent output generation. Its memory has two components: the instruction registry, which is populated with a prompt program to solve the user-given task, and a file store, which will contain the final and intermediate outputs. Each instruction in turn is executed by a separate LLM agent, whose context is managed by a control unit capable of precise memory reading and writing to ensure effective interaction with the file store. These components enable L2MAC to generate extensive outputs, bypassing the constraints of the finite context window while producing outputs that fulfill a complex user-specified task. We empirically demonstrate that L2MAC achieves state-of-the-art performance in generating large codebases for system design tasks, significantly outperforming other coding methods in implementing the detailed user-specified task; we show that L2MAC works for general-purpose extensive text-based tasks, such as writing an entire book; and we provide valuable insights into L2MAC's performance improvement over existing methods.
Create account to get full access
Overview
- Introduces a new framework called L2MAC (Large Language Model Automatic Computer) for generating unbounded computer code using large language models.
- Aims to address the limitations of existing code generation approaches by leveraging the power of large language models.
- Proposes a novel architecture and techniques to enable large language models to generate code without being constrained by input/output size.
Plain English Explanation
The paper presents a new framework called L2MAC: Large Language Model Automatic Computer for Unbounded Code Generation, which aims to use large language models to generate computer code without being limited by the size of the input or output.
Existing approaches for code generation often struggle when the required code is too long or complex to fit within the input/output constraints of the language model. L2MAC addresses this by introducing a novel architecture and techniques that allow large language models to generate code without these size limitations.
The key idea is to break down the code generation process into smaller, manageable steps, and then use the language model to generate each step in sequence. This enables the model to produce high-quality, unbounded code that can solve complex programming tasks. The researchers also explore ways to make the language model more aware of the programming context and constraints, further improving the quality and coherence of the generated code.
Overall, L2MAC represents a significant advancement in the field of code generation, leveraging the power of large language models to tackle programming challenges that were previously out of reach for existing techniques.
Technical Explanation
The L2MAC framework introduces a novel architecture and techniques to enable large language models to generate unbounded computer code.
The key components of the L2MAC framework include:
- Code Decomposition: The input code is broken down into a sequence of smaller, manageable steps that can be generated independently by the language model.
- Code Generation: A large language model is used to generate each step of the code sequence, with specialized prompts and techniques to ensure the coherence and correctness of the generated code.
- Code Recomposition: The generated code steps are then assembled back into the final, unbounded code output.
The researchers also explore ways to make the language model more aware of the programming context, such as incorporating information about the code structure, variable names, and programming constraints. This helps the model generate code that is more aligned with the given programming task and requirements.
Experiments demonstrate that L2MAC can generate high-quality, unbounded code for a variety of programming tasks, outperforming existing code generation approaches in terms of both code quality and the ability to handle large, complex coding problems.
Critical Analysis
The L2MAC framework represents a significant advancement in the field of code generation, but it also has some potential limitations and areas for further research:
-
Generalization Across Domains: While the paper demonstrates the effectiveness of L2MAC on a range of programming tasks, it's unclear how well the framework would generalize to entirely new domains or programming languages. Further research is needed to assess the broader applicability of the approach.
-
Handling of Edge Cases and Error Handling: The paper does not extensively discuss how L2MAC handles edge cases, error conditions, or other programming challenges that may arise in real-world scenarios. Addressing these issues could be an important area for future work.
-
Interpretability and Explainability: As with many large language model-based systems, the inner workings of L2MAC may be difficult to interpret and explain, which could be a concern for certain applications or use cases. Exploring ways to improve the interpretability of the framework could be beneficial.
-
Computational Efficiency: Generating unbounded code using a large language model may have significant computational requirements, which could limit the practical deployment of L2MAC in some settings. Investigating ways to improve the efficiency of the framework would be valuable.
Overall, the L2MAC framework represents an exciting and promising development in the field of code generation, with the potential to enable new applications and use cases. However, further research and refinement will be needed to address the identified limitations and fully realize the potential of this approach.
Conclusion
The L2MAC framework introduces a novel approach to code generation that leverages the power of large language models to produce high-quality, unbounded computer code. By breaking down the code generation process into smaller, manageable steps and incorporating specialized techniques, L2MAC overcomes the limitations of existing code generation methods.
The research presented in this paper represents a significant advancement in the field, with the potential to enable new applications and use cases that were previously out of reach for traditional code generation approaches. While the framework has some areas for further refinement and exploration, the core ideas and techniques introduced by L2MAC provide a promising foundation for future work in this rapidly evolving domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A review on the use of large language models as virtual tutors
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Mar'ia del Carmen Somoza-L'opez
0
0
Transformer architectures contribute to managing long-term dependencies for Natural Language Processing, representing one of the most recent changes in the field. These architectures are the basis of the innovative, cutting-edge Large Language Models (LLMs) that have produced a huge buzz in several fields and industrial sectors, among the ones education stands out. Accordingly, these generative Artificial Intelligence-based solutions have directed the change in techniques and the evolution in educational methods and contents, along with network infrastructure, towards high-quality learning. Given the popularity of LLMs, this review seeks to provide a comprehensive overview of those solutions designed specifically to generate and evaluate educational materials and which involve students and teachers in their design or experimental plan. To the best of our knowledge, this is the first review of educational applications (e.g., student assessment) of LLMs. As expected, the most common role of these systems is as virtual tutors for automatic question generation. Moreover, the most popular models are GTP-3 and BERT. However, due to the continuous launch of new generative models, new works are expected to be published shortly.
5/21/2024
💬
Aspects of human memory and Large Language Models
Romuald A. Janik
0
0
Large Language Models (LLMs) are huge artificial neural networks which primarily serve to generate text, but also provide a very sophisticated probabilistic model of language use. Since generating a semantically consistent text requires a form of effective memory, we investigate the memory properties of LLMs and find surprising similarities with key characteristics of human memory. We argue that the human-like memory properties of the Large Language Model do not follow automatically from the LLM architecture but are rather learned from the statistics of the training textual data. These results strongly suggest that the biological features of human memory leave an imprint on the way that we structure our textual narratives.
4/9/2024

AutoTutor meets Large Language Models: A Language Model Tutor with Rich Pedagogy and Guardrails
Sankalan Pal Chowdhury, Vil'em Zouhar, Mrinmaya Sachan
0
0
Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow.
4/26/2024

LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
Zhuoling Li, Xiaogang Xu, Zhenhua Xu, SerNam Lim, Hengshuang Zhao
0
0
Due to the need to interact with the real world, embodied agents are required to possess comprehensive prior knowledge, long-horizon planning capability, and a swift response speed. Despite recent large language model (LLM) based agents achieving promising performance, they still exhibit several limitations. For instance, the output of LLMs is a descriptive sentence, which is ambiguous when determining specific actions. To address these limitations, we introduce the large auto-regressive model (LARM). LARM leverages both text and multi-view images as input and predicts subsequent actions in an auto-regressive manner. To train LARM, we develop a novel data format named auto-regressive node transmission structure and assemble a corresponding dataset. Adopting a two-phase training regimen, LARM successfully harvests enchanted equipment in Minecraft, which demands significantly more complex decision-making chains than the highest achievements of prior best methods. Besides, the speed of LARM is 6.8x faster.
5/28/2024