HMT-UNet: A hybird Mamba-Transformer Vision UNet for Medical Image Segmentation

0

Sign in to get full access
Overview
- The paper proposes a new deep learning model called HMT-UNet for medical image segmentation.
- HMT-UNet combines a Mamba architecture and a Vision Transformer within a U-Net framework.
- The model aims to leverage the strengths of both Mamba and Transformer approaches for improved medical image segmentation performance.
Plain English Explanation
The paper introduces a new deep learning model called HMT-UNet that is designed for medical image segmentation tasks. Medical image segmentation is the process of automatically identifying and outlining different structures or regions of interest within medical images, such as MRI or CT scans.
HMT-UNet combines two key machine learning concepts - the Mamba architecture and the Vision Transformer - within a U-Net framework. The Mamba architecture is known for its ability to effectively capture multi-scale spatial relationships in images, while the Vision Transformer excels at extracting rich contextual information.
By combining these two approaches, the researchers behind HMT-UNet aim to create a model that can leverage the strengths of both Mamba and Transformer techniques to achieve improved performance on medical image segmentation tasks. This could lead to more accurate and reliable automated analysis of medical scans, which could in turn support faster and more informed clinical decision-making.
Technical Explanation
The core of the HMT-UNet model is a U-Net architecture, which is a widely used deep learning model for segmentation tasks. U-Net consists of an encoder (downsampling) path and a decoder (upsampling) path, connected by skip connections to preserve spatial information.
To enhance the U-Net backbone, the researchers incorporate a Mamba module and a Vision Transformer module. The Mamba module uses a series of rotational convolutions to capture multi-scale spatial relationships, while the Vision Transformer module leverages self-attention mechanisms to extract rich contextual information from the image features.
The output of the Mamba and Transformer modules are then combined and fed into the decoder of the U-Net, allowing the model to benefit from both the spatial understanding of the Mamba module and the contextual awareness of the Transformer module.
The researchers evaluate the performance of HMT-UNet on several medical image segmentation benchmarks, including brain tumor, cardiac, and prostate segmentation tasks. They compare the results to other state-of-the-art models and demonstrate that HMT-UNet achieves superior segmentation accuracy across these diverse medical imaging domains.
Critical Analysis
The paper provides a thorough technical description of the HMT-UNet model and presents compelling experimental results that validate its effectiveness for medical image segmentation. However, the authors do acknowledge some limitations of their approach:
- The computational complexity of the model is higher than some simpler U-Net-based architectures, which could limit its practical deployment in resource-constrained clinical settings.
- The researchers only evaluate HMT-UNet on a limited set of medical imaging tasks, so further testing on a wider range of applications would be beneficial to fully assess the model's generalization capabilities.
- The paper does not delve into the interpretability or explainability of the HMT-UNet model, which could be an important consideration for building trust in the model's predictions within the medical community.
Despite these caveats, the core innovations introduced in HMT-UNet, namely the integration of Mamba and Transformer modules within a U-Net framework, demonstrate the potential for hybrid architectures to push the boundaries of medical image segmentation performance. Continued research in this direction could lead to further advancements in automated medical image analysis.
Conclusion
The HMT-UNet model proposed in this paper represents a promising new approach to medical image segmentation, combining the strengths of Mamba and Transformer techniques within a well-established U-Net architecture. The experimental results show that this hybrid model can outperform other state-of-the-art segmentation methods, suggesting it could have significant practical applications in clinical settings.
While the model does have some limitations in terms of computational complexity and the need for further testing across diverse medical imaging domains, the core ideas behind HMT-UNet highlight the value of exploring innovative architectural designs that can leverage multiple complementary machine learning concepts. As the field of medical image analysis continues to evolve, research efforts like this one will play a crucial role in driving progress and delivering more accurate and reliable automated tools to support clinicians in their decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HMT-UNet: A hybird Mamba-Transformer Vision UNet for Medical Image Segmentation
Mingya Zhang, Zhihao Chen, Yiyuan Ge, Xianping Tao
In the field of medical image segmentation, models based on both CNN and Transformer have been thoroughly investigated. However, CNNs have limited modeling capabilities for long-range dependencies, making it challenging to exploit the semantic information within images fully. On the other hand, the quadratic computational complexity poses a challenge for Transformers. State Space Models (SSMs), such as Mamba, have been recognized as a promising method. They not only demonstrate superior performance in modeling long-range interactions, but also preserve a linear computational complexity. The hybrid mechanism of SSM (State Space Model) and Transformer, after meticulous design, can enhance its capability for efficient modeling of visual features. Extensive experiments have demonstrated that integrating the self-attention mechanism into the hybrid part behind the layers of Mamba's architecture can greatly improve the modeling capacity to capture long-range spatial dependencies. In this paper, leveraging the hybrid mechanism of SSM, we propose a U-shape architecture model for medical image segmentation, named Hybird Transformer vision Mamba UNet (HTM-UNet). We conduct comprehensive experiments on the ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir, CVC-ColonDB, ETIS-Larib PolypDB public datasets and ZD-LCI-GIM private dataset. The results indicate that HTM-UNet exhibits competitive performance in medical image segmentation tasks. Our code is available at https://github.com/simzhangbest/HMT-Unet.
Read more9/10/2024

0
Rotate to Scan: UNet-like Mamba with Triplet SSM Module for Medical Image Segmentation
Hao Tang, Lianglun Cheng, Guoheng Huang, Zhengguang Tan, Junhao Lu, Kaihong Wu
Image segmentation holds a vital position in the realms of diagnosis and treatment within the medical domain. Traditional convolutional neural networks (CNNs) and Transformer models have made significant advancements in this realm, but they still encounter challenges because of limited receptive field or high computing complexity. Recently, State Space Models (SSMs), particularly Mamba and its variants, have demonstrated notable performance in the field of vision. However, their feature extraction methods may not be sufficiently effective and retain some redundant structures, leaving room for parameter reduction. Motivated by previous spatial and channel attention methods, we propose Triplet Mamba-UNet. The method leverages residual VSS Blocks to extract intensive contextual features, while Triplet SSM is employed to fuse features across spatial and channel dimensions. We conducted experiments on ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir-SEG, CVC-ColonDB, and Kvasir-Instrument datasets, demonstrating the superior segmentation performance of our proposed TM-UNet. Additionally, compared to the previous VM-UNet, our model achieves a one-third reduction in parameters.
Read more5/6/2024

0
MSVM-UNet: Multi-Scale Vision Mamba UNet for Medical Image Segmentation
Chaowei Chen, Li Yu, Shiquan Min, Shunfang Wang
State Space Models (SSMs), especially Mamba, have shown great promise in medical image segmentation due to their ability to model long-range dependencies with linear computational complexity. However, accurate medical image segmentation requires the effective learning of both multi-scale detailed feature representations and global contextual dependencies. Although existing works have attempted to address this issue by integrating CNNs and SSMs to leverage their respective strengths, they have not designed specialized modules to effectively capture multi-scale feature representations, nor have they adequately addressed the directional sensitivity problem when applying Mamba to 2D image data. To overcome these limitations, we propose a Multi-Scale Vision Mamba UNet model for medical image segmentation, termed MSVM-UNet. Specifically, by introducing multi-scale convolutions in the VSS blocks, we can more effectively capture and aggregate multi-scale feature representations from the hierarchical features of the VMamba encoder and better handle 2D visual data. Additionally, the large kernel patch expanding (LKPE) layers achieve more efficient upsampling of feature maps by simultaneously integrating spatial and channel information. Extensive experiments on the Synapse and ACDC datasets demonstrate that our approach is more effective than some state-of-the-art methods in capturing and aggregating multi-scale feature representations and modeling long-range dependencies between pixels.
Read more8/27/2024
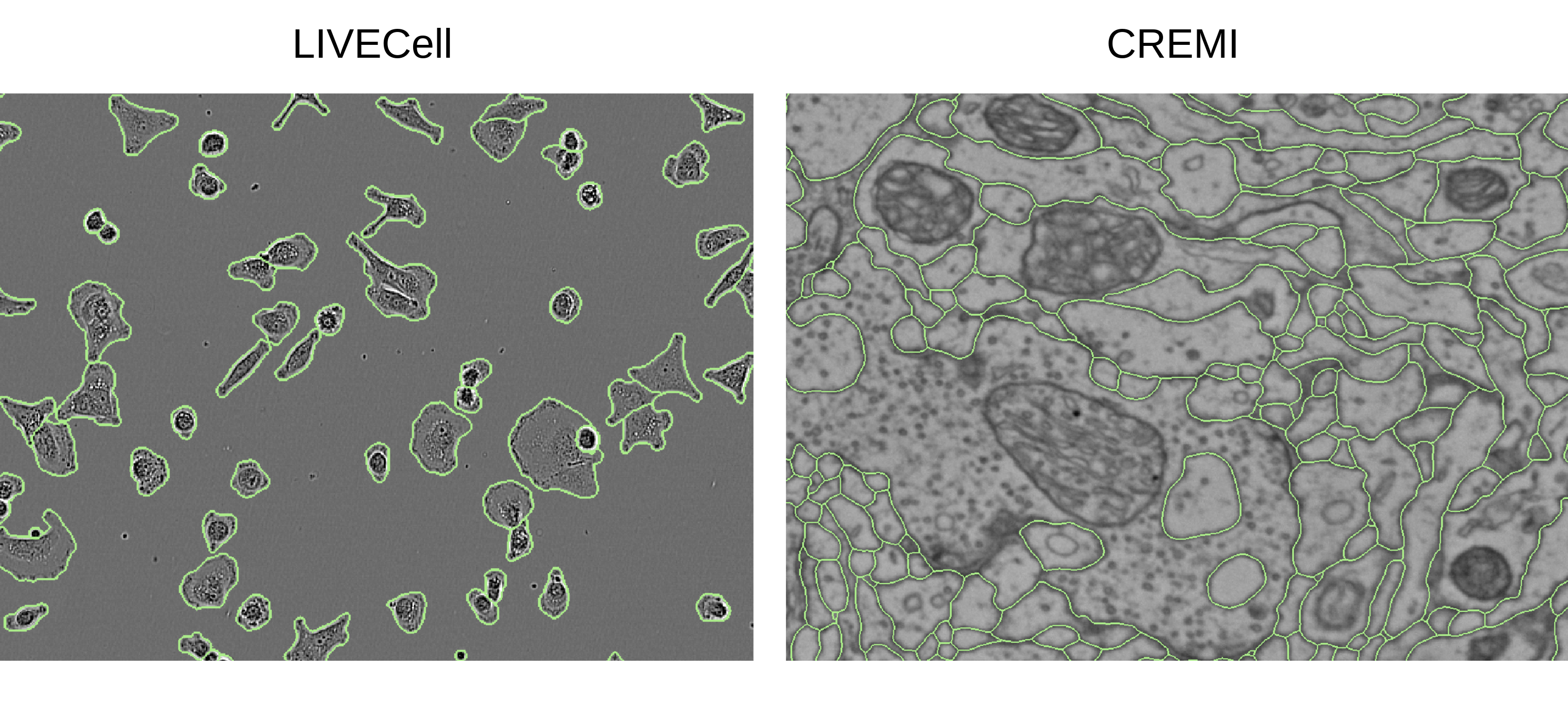
0
ViM-UNet: Vision Mamba for Biomedical Segmentation
Anwai Archit, Constantin Pape
CNNs, most notably the UNet, are the default architecture for biomedical segmentation. Transformer-based approaches, such as UNETR, have been proposed to replace them, benefiting from a global field of view, but suffering from larger runtimes and higher parameter counts. The recent Vision Mamba architecture offers a compelling alternative to transformers, also providing a global field of view, but at higher efficiency. Here, we introduce ViM-UNet, a novel segmentation architecture based on it and compare it to UNet and UNETR for two challenging microscopy instance segmentation tasks. We find that it performs similarly or better than UNet, depending on the task, and outperforms UNETR while being more efficient. Our code is open source and documented at https://github.com/constantinpape/torch-em/blob/main/vimunet.md.
Read more5/16/2024