Semi-Mamba-UNet: Pixel-Level Contrastive and Pixel-Level Cross-Supervised Visual Mamba-based UNet for Semi-Supervised Medical Image Segmentation

0
🖼️
Sign in to get full access
Overview
- Medical image segmentation is crucial for diagnostics, treatment planning, and healthcare.
- Deep learning techniques, such as Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), have shown promise in this field.
- However, these models face challenges in efficiently processing long-range dependencies in medical images, often requiring substantial computational resources.
- The limited availability of expert annotations and the high cost of obtaining them also pose significant obstacles to achieving precise segmentation.
Plain English Explanation
Medical image segmentation is the process of dividing medical images, such as those from X-rays or MRI scans, into different regions or segments. This is essential for diagnosing diseases, planning treatments, and improving healthcare.
Deep learning models, like CNNs and ViTs, have shown promise in this area. CNNs are good at capturing local image features, while ViTs can model long-range dependencies through self-attention mechanisms. However, both models still struggle to efficiently process the long-range relationships in medical images, which often requires a lot of computing power.
Another challenge is the limited availability and high cost of expert-annotated medical images, which are needed to train accurate segmentation models. This makes it difficult to achieve precise and reliable segmentation results.
Technical Explanation
To address these challenges, the researchers proposed a new model called Semi-Mamba-UNet. This model integrates a Mamba-based U-shaped encoder-decoder architecture with a conventional CNN-based UNet in a semi-supervised learning (SSL) framework.
The key innovation is that the two networks generate pseudo-labels and cross-supervise each other at the pixel level simultaneously, drawing inspiration from consistency regularization techniques. This allows the model to leverage both the strengths of the CNN and the Mamba-based architecture to improve segmentation performance, especially on unlabeled data.
Additionally, the researchers introduced a self-supervised pixel-level contrastive learning strategy that employs a pair of projectors to further enhance the feature learning capabilities of the model.
Critical Analysis
The researchers thoroughly evaluated Semi-Mamba-UNet on two publicly available segmentation datasets and compared it to seven other SSL frameworks with either CNN- or ViT-based UNet as the backbone. The results highlight the superior performance of the proposed method, demonstrating its effectiveness in addressing the challenges of medical image segmentation.
However, the paper does not discuss any potential limitations or areas for further research. It would be valuable to understand the specific scenarios or types of medical images where Semi-Mamba-UNet may perform better or worse compared to other approaches, as well as any practical considerations for deploying the model in real-world healthcare settings.
Conclusion
The Semi-Mamba-UNet model represents a promising advancement in the field of medical image segmentation. By integrating the strengths of CNNs and Mamba-based architectures within a semi-supervised learning framework, the researchers have developed a more efficient and effective solution to address the challenges of limited annotations and long-range dependencies in medical images. The publicly available source code and datasets provide opportunities for further research and development in this critical area of healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Semi-Mamba-UNet: Pixel-Level Contrastive and Pixel-Level Cross-Supervised Visual Mamba-based UNet for Semi-Supervised Medical Image Segmentation
Chao Ma, Ziyang Wang
Medical image segmentation is essential in diagnostics, treatment planning, and healthcare, with deep learning offering promising advancements. Notably, the convolutional neural network (CNN) excels in capturing local image features, whereas the Vision Transformer (ViT) adeptly models long-range dependencies through multi-head self-attention mechanisms. Despite their strengths, both the CNN and ViT face challenges in efficiently processing long-range dependencies in medical images, often requiring substantial computational resources. This issue, combined with the high cost and limited availability of expert annotations, poses significant obstacles to achieving precise segmentation. To address these challenges, this study introduces Semi-Mamba-UNet, which integrates a purely visual Mamba-based U-shaped encoder-decoder architecture with a conventional CNN-based UNet into a semi-supervised learning (SSL) framework. This innovative SSL approach leverages both networks to generate pseudo-labels and cross-supervise one another at the pixel level simultaneously, drawing inspiration from consistency regularisation techniques. Furthermore, we introduce a self-supervised pixel-level contrastive learning strategy that employs a pair of projectors to enhance the feature learning capabilities further, especially on unlabelled data. Semi-Mamba-UNet was comprehensively evaluated on two publicly available segmentation dataset and compared with seven other SSL frameworks with both CNN- or ViT-based UNet as the backbone network, highlighting the superior performance of the proposed method. The source code of Semi-Mamba-Unet, all baseline SSL frameworks, the CNN- and ViT-based networks, and the two corresponding datasets are made publicly accessible.
Read more7/30/2024

0
HMT-UNet: A hybird Mamba-Transformer Vision UNet for Medical Image Segmentation
Mingya Zhang, Zhihao Chen, Yiyuan Ge, Xianping Tao
In the field of medical image segmentation, models based on both CNN and Transformer have been thoroughly investigated. However, CNNs have limited modeling capabilities for long-range dependencies, making it challenging to exploit the semantic information within images fully. On the other hand, the quadratic computational complexity poses a challenge for Transformers. State Space Models (SSMs), such as Mamba, have been recognized as a promising method. They not only demonstrate superior performance in modeling long-range interactions, but also preserve a linear computational complexity. The hybrid mechanism of SSM (State Space Model) and Transformer, after meticulous design, can enhance its capability for efficient modeling of visual features. Extensive experiments have demonstrated that integrating the self-attention mechanism into the hybrid part behind the layers of Mamba's architecture can greatly improve the modeling capacity to capture long-range spatial dependencies. In this paper, leveraging the hybrid mechanism of SSM, we propose a U-shape architecture model for medical image segmentation, named Hybird Transformer vision Mamba UNet (HTM-UNet). We conduct comprehensive experiments on the ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir, CVC-ColonDB, ETIS-Larib PolypDB public datasets and ZD-LCI-GIM private dataset. The results indicate that HTM-UNet exhibits competitive performance in medical image segmentation tasks. Our code is available at https://github.com/simzhangbest/HMT-Unet.
Read more9/10/2024

0
MSVM-UNet: Multi-Scale Vision Mamba UNet for Medical Image Segmentation
Chaowei Chen, Li Yu, Shiquan Min, Shunfang Wang
State Space Models (SSMs), especially Mamba, have shown great promise in medical image segmentation due to their ability to model long-range dependencies with linear computational complexity. However, accurate medical image segmentation requires the effective learning of both multi-scale detailed feature representations and global contextual dependencies. Although existing works have attempted to address this issue by integrating CNNs and SSMs to leverage their respective strengths, they have not designed specialized modules to effectively capture multi-scale feature representations, nor have they adequately addressed the directional sensitivity problem when applying Mamba to 2D image data. To overcome these limitations, we propose a Multi-Scale Vision Mamba UNet model for medical image segmentation, termed MSVM-UNet. Specifically, by introducing multi-scale convolutions in the VSS blocks, we can more effectively capture and aggregate multi-scale feature representations from the hierarchical features of the VMamba encoder and better handle 2D visual data. Additionally, the large kernel patch expanding (LKPE) layers achieve more efficient upsampling of feature maps by simultaneously integrating spatial and channel information. Extensive experiments on the Synapse and ACDC datasets demonstrate that our approach is more effective than some state-of-the-art methods in capturing and aggregating multi-scale feature representations and modeling long-range dependencies between pixels.
Read more8/27/2024
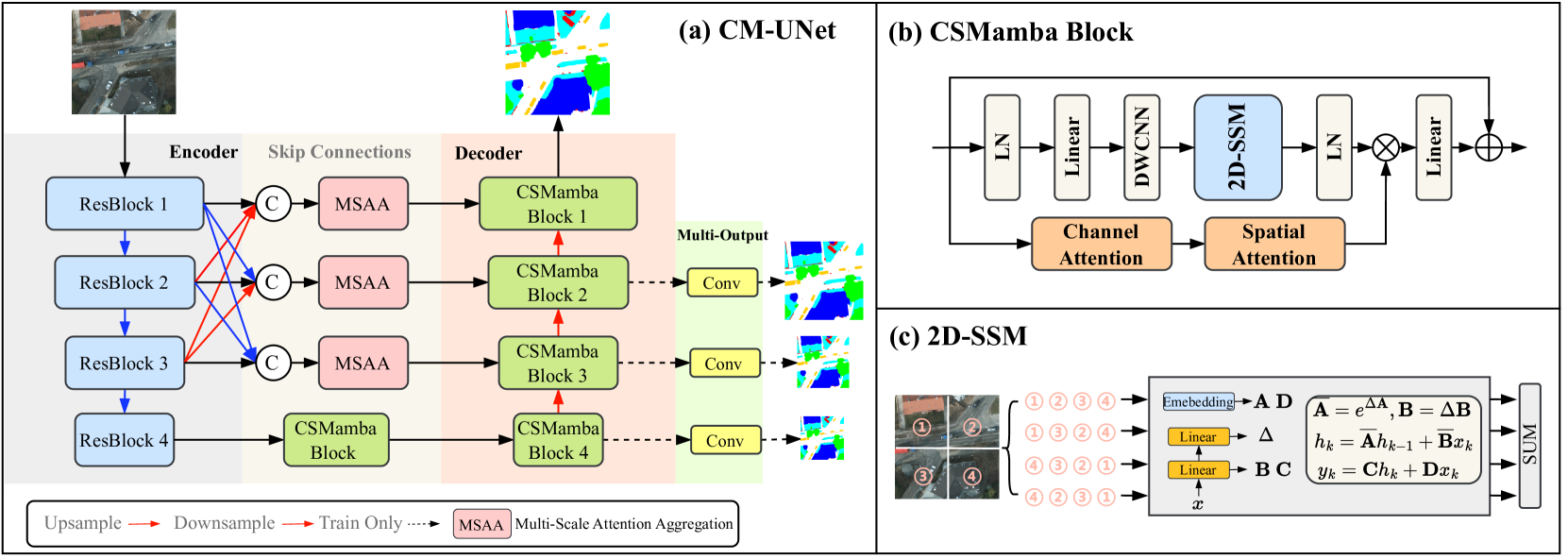
0
CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
Mushui Liu, Jun Dan, Ziqian Lu, Yunlong Yu, Yingming Li, Xi Li
Due to the large-scale image size and object variations, current CNN-based and Transformer-based approaches for remote sensing image semantic segmentation are suboptimal for capturing the long-range dependency or limited to the complex computational complexity. In this paper, we propose CM-UNet, comprising a CNN-based encoder for extracting local image features and a Mamba-based decoder for aggregating and integrating global information, facilitating efficient semantic segmentation of remote sensing images. Specifically, a CSMamba block is introduced to build the core segmentation decoder, which employs channel and spatial attention as the gate activation condition of the vanilla Mamba to enhance the feature interaction and global-local information fusion. Moreover, to further refine the output features from the CNN encoder, a Multi-Scale Attention Aggregation (MSAA) module is employed to merge the different scale features. By integrating the CSMamba block and MSAA module, CM-UNet effectively captures the long-range dependencies and multi-scale global contextual information of large-scale remote-sensing images. Experimental results obtained on three benchmarks indicate that the proposed CM-UNet outperforms existing methods in various performance metrics. The codes are available at https://github.com/XiaoBuL/CM-UNet.
Read more5/20/2024