HOIMotion: Forecasting Human Motion During Human-Object Interactions Using Egocentric 3D Object Bounding Boxes

0

Sign in to get full access
Overview
- This paper introduces "HOIMotion", a model for forecasting human motion during interactions with objects using egocentric 3D object bounding boxes.
- The model aims to predict future human body pose and motion given the current state and 3D object interactions.
- The authors collect a new dataset of egocentric videos of human-object interactions and use it to train and evaluate their model.
Plain English Explanation
The paper presents a new approach to predicting how people will move and interact with objects in the future, based on observing their current movements and the 3D positions of nearby objects. The key idea is to use the 3D locations and shapes of objects that someone is interacting with as additional information to improve motion forecasting.
For example, if you see someone reaching for a mug on a table, the model can use the 3D position and shape of the mug to better anticipate how the person's hand and arm will move to pick it up. Link to Multimodal Sense-Informed Prediction of 3D Human Motions This could be useful for applications like anticipating human actions in robotics or virtual reality experiences.
The authors collect a new dataset of video footage showing people interacting with objects from a first-person perspective. They then train their "HOIMotion" model on this data to learn how to forecast future human motion based on the current 3D object interactions. Link to Expressive Forecasting of 3D Whole-Body Human Motions
Technical Explanation
The key technical innovation of the HOIMotion model is its use of 3D object bounding boxes extracted from egocentric video as an additional input to improve human motion forecasting. Link to EMAG: Ego-Motion Aware Generalizable 2D Hand
The model takes in the current 3D skeletal pose of a person, their egocentric video frame, and the 3D bounding boxes of objects they are interacting with. It then uses a series of neural network modules to predict the person's future body pose and motion over several timesteps.
The authors collect a new dataset called "HOI3D" which contains over 1 million frames of egocentric video showing people interacting with a variety of everyday objects. They use this data to train and evaluate the HOIMotion model, demonstrating improved motion forecasting performance compared to prior methods that do not use 3D object information. Link to EgoCHOIR: Capturing 3D Human-Object Interaction Regions
Critical Analysis
One potential limitation of the HOIMotion approach is its reliance on accurate 3D object detection and tracking, which can be challenging in real-world scenarios with clutter and occlusions. The paper does not explore the impact of errors in the 3D object inputs on the motion forecasting performance.
Additionally, the dataset used for training and evaluation, while large, may not capture the full diversity of human-object interactions that could occur in the real world. Further research would be needed to test the generalization of the model to novel scenarios. Link to EventEgo3D: 3D Human Motion Capture from Egocentric
Overall, the HOIMotion model represents an interesting and promising approach to incorporating 3D object context into human motion forecasting. With further refinements and more comprehensive evaluation, it could have valuable applications in areas like robotics, AR/VR, and video understanding.
Conclusion
The HOIMotion paper presents a novel method for forecasting human motion during interactions with objects, using egocentric 3D object bounding boxes as an additional source of information. The authors demonstrate improved motion prediction performance on a large egocentric dataset, suggesting that incorporating 3D object context can be a valuable approach for this task.
While the model has some limitations, such as reliance on accurate 3D object detection, the core idea of leveraging object-centric information to enhance motion forecasting is an important step forward. Further research in this direction could lead to more robust and versatile human motion prediction capabilities, with valuable applications in fields like robotics, virtual reality, and video analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HOIMotion: Forecasting Human Motion During Human-Object Interactions Using Egocentric 3D Object Bounding Boxes
Zhiming Hu, Zheming Yin, Daniel Haeufle, Syn Schmitt, Andreas Bulling
We present HOIMotion - a novel approach for human motion forecasting during human-object interactions that integrates information about past body poses and egocentric 3D object bounding boxes. Human motion forecasting is important in many augmented reality applications but most existing methods have only used past body poses to predict future motion. HOIMotion first uses an encoder-residual graph convolutional network (GCN) and multi-layer perceptrons to extract features from body poses and egocentric 3D object bounding boxes, respectively. Our method then fuses pose and object features into a novel pose-object graph and uses a residual-decoder GCN to forecast future body motion. We extensively evaluate our method on the Aria digital twin (ADT) and MoGaze datasets and show that HOIMotion consistently outperforms state-of-the-art methods by a large margin of up to 8.7% on ADT and 7.2% on MoGaze in terms of mean per joint position error. Complementing these evaluations, we report a human study (N=20) that shows that the improvements achieved by our method result in forecasted poses being perceived as both more precise and more realistic than those of existing methods. Taken together, these results reveal the significant information content available in egocentric 3D object bounding boxes for human motion forecasting and the effectiveness of our method in exploiting this information.
Read more7/4/2024

0
GazeMotion: Gaze-guided Human Motion Forecasting
Zhiming Hu, Syn Schmitt, Daniel Haeufle, Andreas Bulling
We present GazeMotion, a novel method for human motion forecasting that combines information on past human poses with human eye gaze. Inspired by evidence from behavioural sciences showing that human eye and body movements are closely coordinated, GazeMotion first predicts future eye gaze from past gaze, then fuses predicted future gaze and past poses into a gaze-pose graph, and finally uses a residual graph convolutional network to forecast body motion. We extensively evaluate our method on the MoGaze, ADT, and GIMO benchmark datasets and show that it outperforms state-of-the-art methods by up to 7.4% improvement in mean per joint position error. Using head direction as a proxy to gaze, our method still achieves an average improvement of 5.5%. We finally report an online user study showing that our method also outperforms prior methods in terms of perceived realism. These results show the significant information content available in eye gaze for human motion forecasting as well as the effectiveness of our method in exploiting this information.
Read more7/12/2024
🔮
0
Multimodal Sense-Informed Prediction of 3D Human Motions
Zhenyu Lou, Qiongjie Cui, Haofan Wang, Xu Tang, Hong Zhou
Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
Read more5/7/2024
0
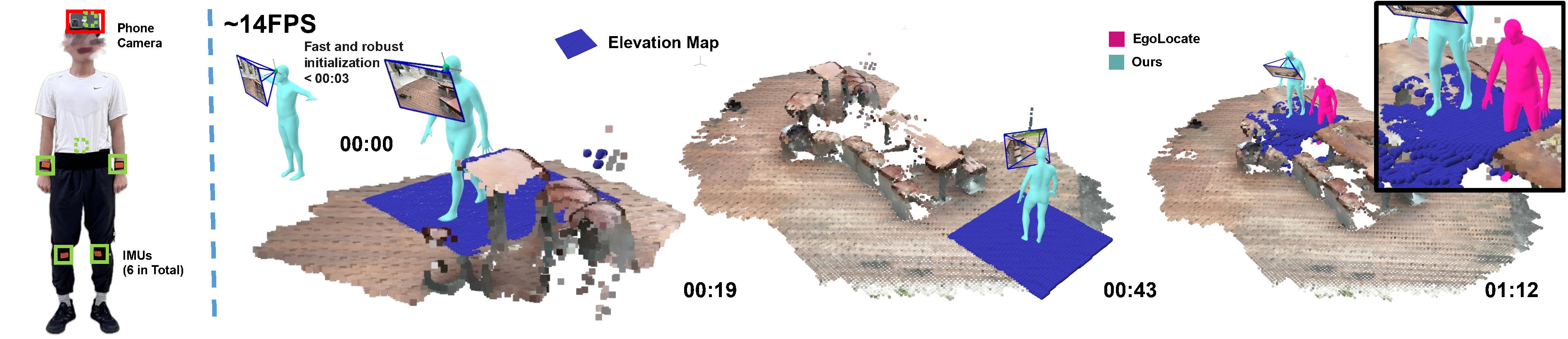
EgoHDM: An Online Egocentric-Inertial Human Motion Capture, Localization, and Dense Mapping System
Bonan Liu, Handi Yin, Manuel Kaufmann, Jinhao He, Sammy Christen, Jie Song, Pan Hui
We present EgoHDM, an online egocentric-inertial human motion capture (mocap), localization, and dense mapping system. Our system uses 6 inertial measurement units (IMUs) and a commodity head-mounted RGB camera. EgoHDM is the first human mocap system that offers dense scene mapping in near real-time. Further, it is fast and robust to initialize and fully closes the loop between physically plausible map-aware global human motion estimation and mocap-aware 3D scene reconstruction. Our key idea is integrating camera localization and mapping information with inertial human motion capture bidirectionally in our system. To achieve this, we design a tightly coupled mocap-aware dense bundle adjustment and physics-based body pose correction module leveraging a local body-centric elevation map. The latter introduces a novel terrain-aware contact PD controller, which enables characters to physically contact the given local elevation map thereby reducing human floating or penetration. We demonstrate the performance of our system on established synthetic and real-world benchmarks. The results show that our method reduces human localization, camera pose, and mapping accuracy error by 41%, 71%, 46%, respectively, compared to the state of the art. Our qualitative evaluations on newly captured data further demonstrate that EgoHDM can cover challenging scenarios in non-flat terrain including stepping over stairs and outdoor scenes in the wild.
Read more9/6/2024