Holmes: Benchmark the Linguistic Competence of Language Models

0
Sign in to get full access
Overview
- This paper introduces Holmes, a benchmark for evaluating the linguistic competence of large language models (LLMs).
- The benchmark includes a diverse set of tasks that assess different aspects of language understanding, such as phonological skills, deductive reasoning, and language grounding.
- The authors conduct a comprehensive evaluation of several state-of-the-art LLMs using the Holmes benchmark and provide insights into their linguistic capabilities and limitations.
Plain English Explanation
The paper presents a new tool called Holmes that allows researchers to thoroughly test the language skills of large AI models. These models, known as large language models (LLMs), have become very advanced at understanding and generating human language. However, their true linguistic capabilities are still not fully understood.
The Holmes benchmark includes a variety of tasks that assess different aspects of language, such as the ability to understand sounds and word structures (phonological skills), draw logical conclusions (deductive reasoning), and connect language to real-world meaning (language grounding). By testing LLMs on this diverse set of language skills, the researchers can get a more comprehensive picture of their strengths and weaknesses.
The authors use Holmes to evaluate several state-of-the-art LLMs, such as GPT-3 and BERT. The results provide valuable insights into the linguistic competence of these models and identify areas where they still struggle compared to humans. This information can help guide the development of even more capable and well-rounded language AI systems in the future.
Technical Explanation
The paper introduces the Holmes benchmark, a comprehensive suite of language understanding tasks designed to assess the linguistic competence of large language models (LLMs). The benchmark includes a diverse set of tests, such as phonological skill evaluation, deductive reasoning, and language grounding, that probe different aspects of language understanding.
The authors conduct a large-scale evaluation of several prominent LLMs, including GPT-3, BERT, and others, using the Holmes benchmark. They analyze the models' performance across the various tasks and provide insights into their linguistic capabilities and limitations. The results highlight areas where these LLMs excel, such as lexical and syntactic understanding, as well as areas where they struggle, such as phonological awareness and deductive reasoning.
The paper also discusses the potential of using the Holmes benchmark as a tool to advance research into more capable and well-rounded language AI systems. The authors suggest that the benchmark's comprehensive approach can help identify specific weaknesses in current LLMs and guide the development of more robust and linguistically competent models in the future.
Critical Analysis
The Holmes benchmark presents a valuable contribution to the field of language AI research by providing a comprehensive and well-designed set of tasks for evaluating the linguistic competence of LLMs. The authors have carefully curated the benchmark to cover a diverse range of language skills, which is essential for gaining a holistic understanding of these models' capabilities.
One potential limitation of the study is the use of a relatively small set of LLMs for the evaluation. While the authors have included some of the most prominent models, such as GPT-3 and BERT, a broader evaluation across a wider range of LLMs could provide even more insights into the state of the art in language AI. Additionally, the paper does not delve into the potential biases or fairness issues that may arise from the use of these models, which is an important consideration for real-world applications.
Another area for further research could be the robustness of the Holmes benchmark to distributional assumptions. As language AI systems continue to evolve, it will be crucial to ensure that the benchmark remains a reliable and unbiased tool for evaluating their linguistic competence, even in the face of changes in language use and distribution.
Conclusion
The Holmes benchmark introduced in this paper represents a significant step forward in the evaluation of language AI systems. By assessing a wide range of linguistic skills, the benchmark provides a more comprehensive and nuanced understanding of the capabilities and limitations of large language models. The authors' comprehensive evaluation of several state-of-the-art LLMs using the Holmes benchmark offers valuable insights that can guide the development of even more capable and well-rounded language AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Holmes: Benchmark the Linguistic Competence of Language Models
Andreas Waldis, Yotam Perlitz, Leshem Choshen, Yufang Hou, Iryna Gurevych
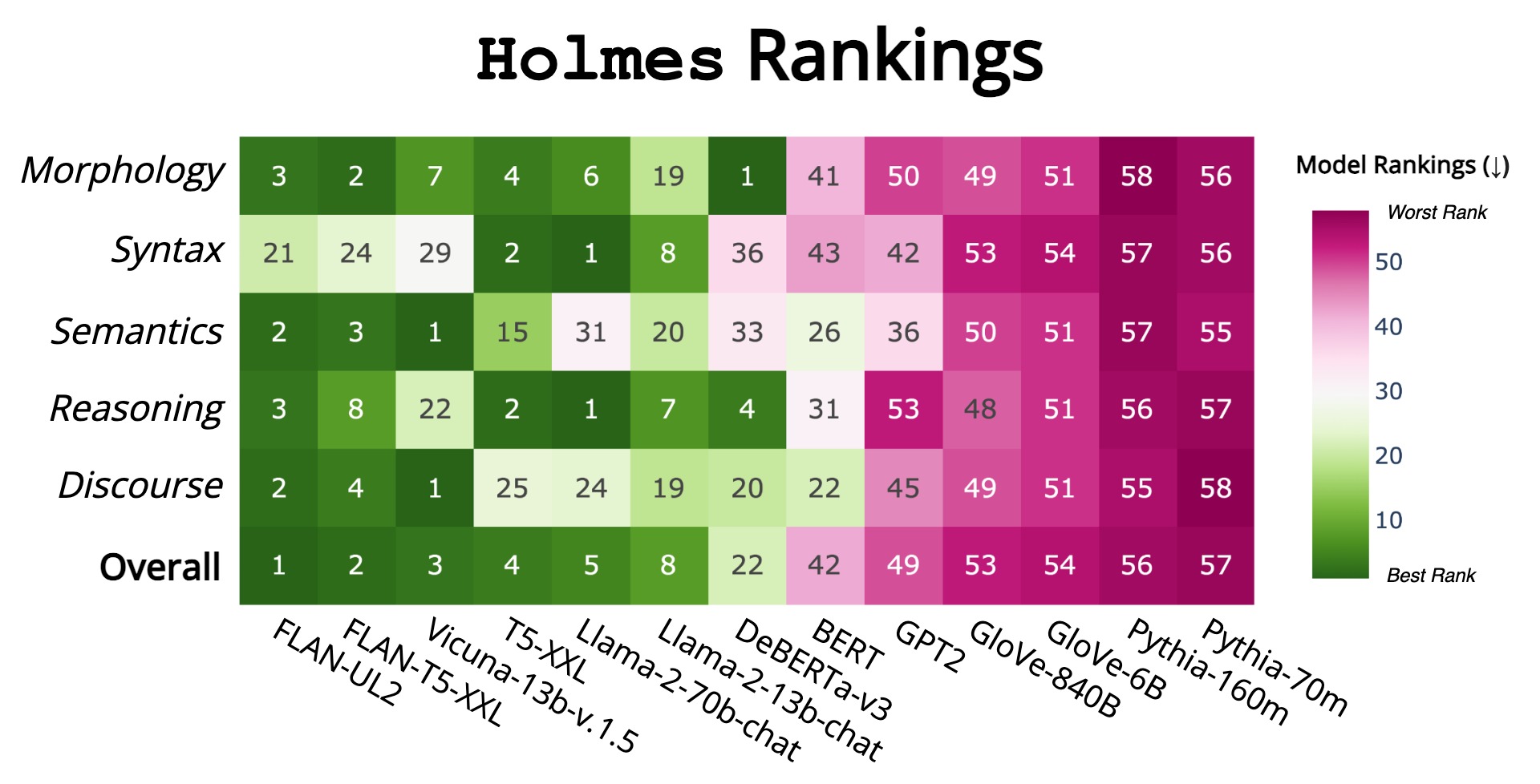
We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
Read more5/24/2024
💬
0
Competence-Based Analysis of Language Models
Adam Davies, Jize Jiang, ChengXiang Zhai
Despite the recent successes of large, pretrained neural language models (LLMs), comparatively little is known about the representations of linguistic structure they learn during pretraining, which can lead to unexpected behaviors in response to prompt variation or distribution shift. To better understand these models and behaviors, we introduce a general model analysis framework to study LLMs with respect to their representation and use of human-interpretable linguistic properties. Our framework, CALM (Competence-based Analysis of Language Models), is designed to investigate LLM competence in the context of specific tasks by intervening on models' internal representations of different linguistic properties using causal probing, and measuring models' alignment under these interventions with a given ground-truth causal model of the task. We also develop a new approach for performing causal probing interventions using gradient-based adversarial attacks, which can target a broader range of properties and representations than prior techniques. Finally, we carry out a case study of CALM using these interventions to analyze and compare LLM competence across a variety of lexical inference tasks, showing that CALM can be used to explain and predict behaviors across these tasks.
Read more8/22/2024

0
PhonologyBench: Evaluating Phonological Skills of Large Language Models
Ashima Suvarna, Harshita Khandelwal, Nanyun Peng
Phonology, the study of speech's structure and pronunciation rules, is a critical yet often overlooked component in Large Language Model (LLM) research. LLMs are widely used in various downstream applications that leverage phonology such as educational tools and poetry generation. Moreover, LLMs can potentially learn imperfect associations between orthographic and phonological forms from the training data. Thus, it is imperative to benchmark the phonological skills of LLMs. To this end, we present PhonologyBench, a novel benchmark consisting of three diagnostic tasks designed to explicitly test the phonological skills of LLMs in English: grapheme-to-phoneme conversion, syllable counting, and rhyme word generation. Despite having no access to speech data, LLMs showcased notable performance on the PhonologyBench tasks. However, we observe a significant gap of 17% and 45% on Rhyme Word Generation and Syllable counting, respectively, when compared to humans. Our findings underscore the importance of studying LLM performance on phonological tasks that inadvertently impact real-world applications. Furthermore, we encourage researchers to choose LLMs that perform well on the phonological task that is closely related to the downstream application since we find that no single model consistently outperforms the others on all the tasks.
Read more4/8/2024
💬
0
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
Read more4/16/2024