PhonologyBench: Evaluating Phonological Skills of Large Language Models

0

Sign in to get full access
Overview
- This paper introduces PhonologyBench, a benchmark for evaluating the phonological skills of large language models (LLMs).
- Phonology is the study of the sound patterns and sound changes in a language. Assessing an LLM's phonological capabilities is crucial for understanding its potential for applications like speech recognition and generation.
- The PhonologyBench includes a diverse set of tasks that test various phonological skills, such as syllabification, stress assignment, and phoneme-to-grapheme conversion.
Plain English Explanation
The paper presents a new benchmark called PhonologyBench that is designed to test the phonological skills of large language models (LLMs). Phonology is the study of the sounds in a language and how they work together. Assessing an LLM's phonological abilities is important for applications like speech recognition and generation.
The PhonologyBench includes a variety of tasks that evaluate different phonological skills. For example, one task might ask the LLM to break a word into its syllables, while another task could involve assigning stress to the correct syllable in a word. The benchmark covers a wide range of phonological phenomena to get a comprehensive understanding of an LLM's capabilities in this domain.
Technical Explanation
The paper introduces PhonologyBench, a new benchmark for evaluating the phonological skills of large language models (LLMs). Phonology is the study of the sound patterns and sound changes within a language, and assessing an LLM's phonological capabilities is crucial for understanding its potential for applications such as speech recognition and generation.
The PhonologyBench comprises a diverse set of tasks that test various phonological skills, including syllabification, stress assignment, and phoneme-to-grapheme conversion. The tasks are designed to cover a wide range of phonological phenomena, allowing for a comprehensive evaluation of an LLM's performance in this domain.
The paper also presents the results of evaluating several popular LLMs, such as GPT-3 and BERT, on the PhonologyBench. The findings reveal the strengths and weaknesses of these models in different phonological skills, providing insights into the current state of LLM phonological capabilities and directions for future improvement.
Critical Analysis
The paper presents a comprehensive and well-designed benchmark for evaluating the phonological skills of large language models. However, it is important to note that the benchmark focuses on evaluating the models' performance on specific phonological tasks, and does not necessarily reflect their overall linguistic capabilities or their ability to handle real-world language use.
Additionally, the paper acknowledges that the current version of the PhonologyBench is limited to English, and the authors plan to expand it to other languages in the future. This limitation may impact the generalizability of the benchmark and its findings, as phonological patterns can vary significantly across different languages.
Furthermore, the paper does not delve into the potential biases or limitations of the training data used for the evaluated LLMs, which could also influence their performance on the PhonologyBench tasks. Exploring these factors in more depth could provide valuable insights into the practical applications and limitations of these models in real-world scenarios.
Conclusion
The PhonologyBench introduced in this paper is a valuable tool for assessing the phonological skills of large language models. By testing a wide range of phonological abilities, the benchmark provides a nuanced understanding of an LLM's capabilities in this crucial linguistic domain. The findings from the evaluation of popular LLMs offer insights that can inform the development of more robust and versatile models, with potential applications in areas such as speech recognition, generation, and understanding.
As the authors expand the benchmark to other languages, it will become an increasingly valuable resource for the broader research community, enabling more comprehensive comparisons and driving progress in the field of large language model development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PhonologyBench: Evaluating Phonological Skills of Large Language Models
Ashima Suvarna, Harshita Khandelwal, Nanyun Peng
Phonology, the study of speech's structure and pronunciation rules, is a critical yet often overlooked component in Large Language Model (LLM) research. LLMs are widely used in various downstream applications that leverage phonology such as educational tools and poetry generation. Moreover, LLMs can potentially learn imperfect associations between orthographic and phonological forms from the training data. Thus, it is imperative to benchmark the phonological skills of LLMs. To this end, we present PhonologyBench, a novel benchmark consisting of three diagnostic tasks designed to explicitly test the phonological skills of LLMs in English: grapheme-to-phoneme conversion, syllable counting, and rhyme word generation. Despite having no access to speech data, LLMs showcased notable performance on the PhonologyBench tasks. However, we observe a significant gap of 17% and 45% on Rhyme Word Generation and Syllable counting, respectively, when compared to humans. Our findings underscore the importance of studying LLM performance on phonological tasks that inadvertently impact real-world applications. Furthermore, we encourage researchers to choose LLMs that perform well on the phonological task that is closely related to the downstream application since we find that no single model consistently outperforms the others on all the tasks.
Read more4/8/2024
0
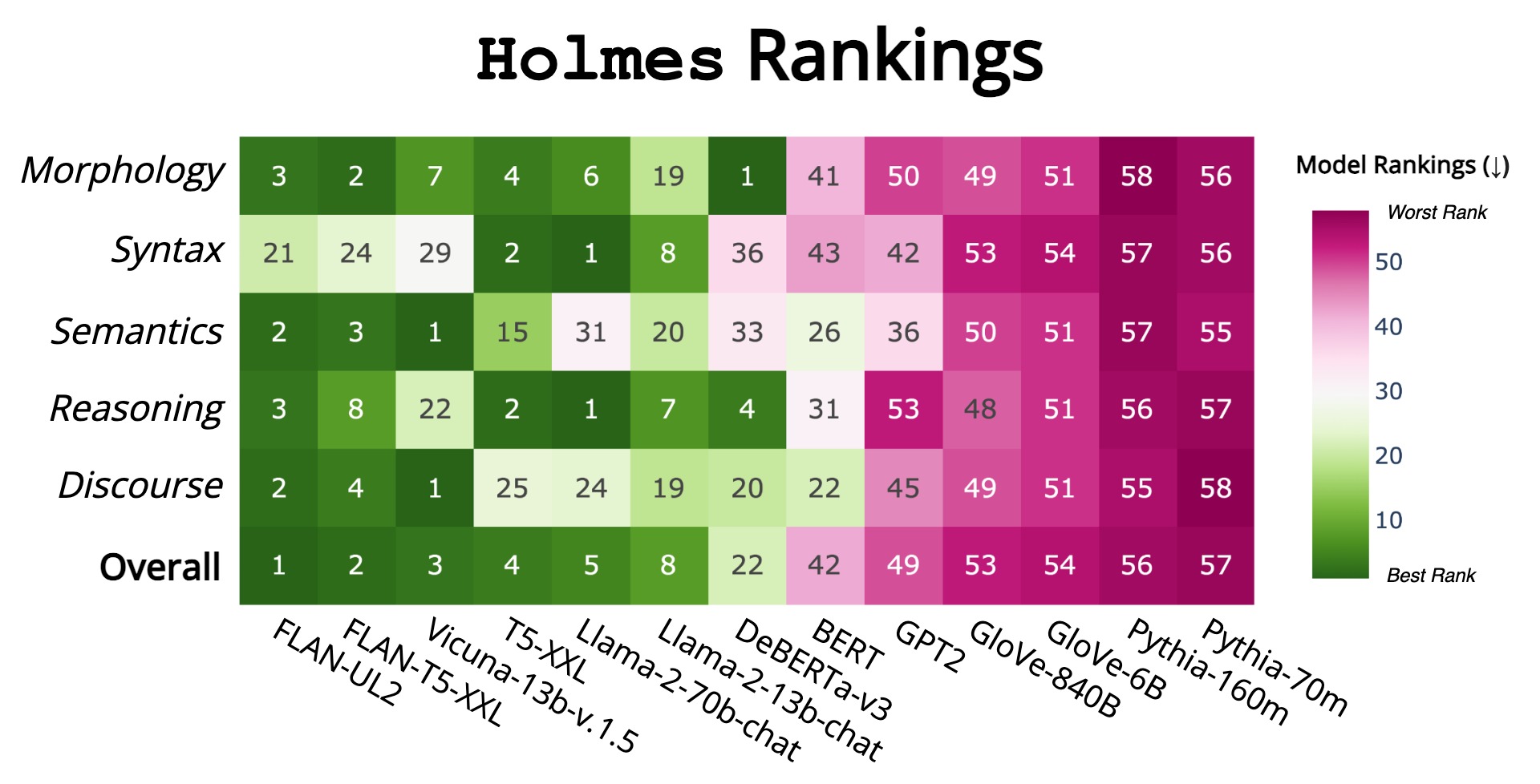
Holmes: Benchmark the Linguistic Competence of Language Models
Andreas Waldis, Yotam Perlitz, Leshem Choshen, Yufang Hou, Iryna Gurevych
We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
Read more5/24/2024

0
New!LLM-Powered Grapheme-to-Phoneme Conversion: Benchmark and Case Study
Mahta Fetrat Qharabagh, Zahra Dehghanian, Hamid R. Rabiee
Grapheme-to-phoneme (G2P) conversion is critical in speech processing, particularly for applications like speech synthesis. G2P systems must possess linguistic understanding and contextual awareness of languages with polyphone words and context-dependent phonemes. Large language models (LLMs) have recently demonstrated significant potential in various language tasks, suggesting that their phonetic knowledge could be leveraged for G2P. In this paper, we evaluate the performance of LLMs in G2P conversion and introduce prompting and post-processing methods that enhance LLM outputs without additional training or labeled data. We also present a benchmarking dataset designed to assess G2P performance on sentence-level phonetic challenges of the Persian language. Our results show that by applying the proposed methods, LLMs can outperform traditional G2P tools, even in an underrepresented language like Persian, highlighting the potential of developing LLM-aided G2P systems.
Read more9/16/2024

0
Beyond Metrics: A Critical Analysis of the Variability in Large Language Model Evaluation Frameworks
Marco AF Pimentel, Cl'ement Christophe, Tathagata Raha, Prateek Munjal, Praveen K Kanithi, Shadab Khan
As large language models (LLMs) continue to evolve, the need for robust and standardized evaluation benchmarks becomes paramount. Evaluating the performance of these models is a complex challenge that requires careful consideration of various linguistic tasks, model architectures, and benchmarking methodologies. In recent years, various frameworks have emerged as noteworthy contributions to the field, offering comprehensive evaluation tests and benchmarks for assessing the capabilities of LLMs across diverse domains. This paper provides an exploration and critical analysis of some of these evaluation methodologies, shedding light on their strengths, limitations, and impact on advancing the state-of-the-art in natural language processing.
Read more8/1/2024