Competence-Based Analysis of Language Models

0
💬
Sign in to get full access
Overview
- Researchers are interested in understanding the linguistic representations that large language models (LLMs) learn during pretraining.
- Unexpected behaviors in LLMs can arise when prompts are varied or the data distribution shifts.
- To better understand these models and their behaviors, the researchers introduce a framework called CALM (Competence-based Analysis of Language Models).
Plain English Explanation
The research paper discusses a framework called CALM (Competence-based Analysis of Language Models) that aims to help us better understand large language models. Large language models are AI systems that have been trained on vast amounts of text data, allowing them to generate human-like text. However, these models can sometimes behave in unexpected ways, especially when the input prompts are changed or the data they are tested on is different from what they were trained on.
The CALM framework is designed to investigate how well these language models understand different linguistic properties, such as the meaning of words or the structure of sentences. By probing the models' internal representations and measuring how they respond to interventions on these linguistic properties, researchers can gain insights into the models' competence and potentially predict their behavior in different tasks.
Technical Explanation
The researchers introduce CALM, a framework for analyzing the linguistic representations and competence of large language models (LLMs). CALM uses causal probing to intervene on the internal representations of LLMs and measure their alignment with a given ground-truth causal model of a specific task.
The key aspects of CALM include:
- Causal Probing: The researchers develop a new approach for performing causal probing interventions using gradient-based adversarial attacks. This allows them to target a broader range of linguistic properties and representations compared to previous techniques.
- Competence-based Analysis: CALM is designed to investigate LLM competence in the context of specific tasks by measuring the models' alignment with a ground-truth causal model of the task under different linguistic interventions.
The researchers demonstrate the use of CALM through a case study, analyzing and comparing LLM competence across various lexical inference tasks. Their findings show that CALM can be used to explain and predict the behaviors of language models in these tasks.
Critical Analysis
The researchers acknowledge that while their CALM framework provides a novel approach for analyzing the linguistic representations and competence of LLMs, it has certain limitations. For example, the causal probing interventions may not capture all aspects of the models' internal representations, and the ground-truth causal models used in the analysis may not fully capture the complexity of the tasks.
Additionally, the researchers note that their case study focused on a limited set of lexical inference tasks, and further research is needed to understand how CALM performs across a broader range of linguistic and cognitive tasks. There is also the potential for distribution shift issues, where the models' performance may degrade when tested on data that differs significantly from their training distribution.
Overall, the CALM framework represents an important step in the ongoing efforts to better understand the linguistic representations and competence of large language models. However, continued research and refinement of the approach will be necessary to fully address the complexities and challenges inherent in these highly capable but often opaque AI systems.
Conclusion
This research paper introduces the CALM (Competence-based Analysis of Language Models) framework, which aims to help researchers better understand the linguistic representations and competence of large language models. By using causal probing interventions to investigate the models' internal representations, CALM can provide insights into how these models handle different linguistic properties and tasks.
The researchers demonstrate the use of CALM through a case study analyzing LLM performance on lexical inference tasks, showing that the framework can be used to explain and predict model behaviors. While CALM represents an important step forward, the researchers acknowledge that there are still limitations and areas for further research, such as expanding the analysis to a broader range of tasks and addressing potential distribution shift issues.
Overall, the CALM framework offers a valuable tool for researchers and developers working to understand and improve the linguistic capabilities of large language models, which have become increasingly important in a wide range of AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Competence-Based Analysis of Language Models
Adam Davies, Jize Jiang, ChengXiang Zhai
Despite the recent successes of large, pretrained neural language models (LLMs), comparatively little is known about the representations of linguistic structure they learn during pretraining, which can lead to unexpected behaviors in response to prompt variation or distribution shift. To better understand these models and behaviors, we introduce a general model analysis framework to study LLMs with respect to their representation and use of human-interpretable linguistic properties. Our framework, CALM (Competence-based Analysis of Language Models), is designed to investigate LLM competence in the context of specific tasks by intervening on models' internal representations of different linguistic properties using causal probing, and measuring models' alignment under these interventions with a given ground-truth causal model of the task. We also develop a new approach for performing causal probing interventions using gradient-based adversarial attacks, which can target a broader range of properties and representations than prior techniques. Finally, we carry out a case study of CALM using these interventions to analyze and compare LLM competence across a variety of lexical inference tasks, showing that CALM can be used to explain and predict behaviors across these tasks.
Read more8/22/2024
0
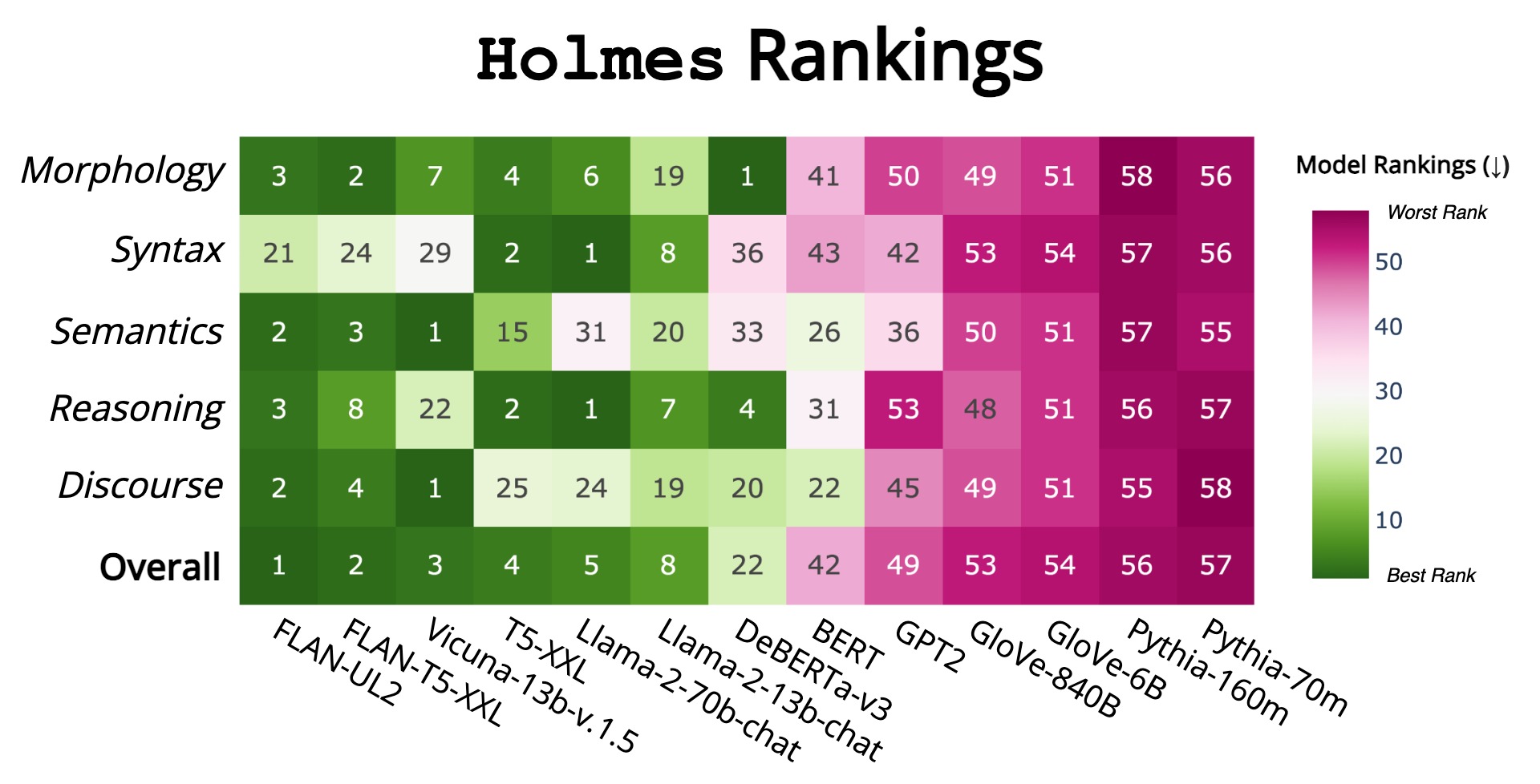
Holmes: Benchmark the Linguistic Competence of Language Models
Andreas Waldis, Yotam Perlitz, Leshem Choshen, Yufang Hou, Iryna Gurevych
We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
Read more5/24/2024
💬
0
Causal Evaluation of Language Models
Sirui Chen, Bo Peng, Meiqi Chen, Ruiqi Wang, Mengying Xu, Xingyu Zeng, Rui Zhao, Shengjie Zhao, Yu Qiao, Chaochao Lu
Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
Read more5/2/2024

0
From Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
Ali Malik, Stephen Mayhew, Chris Piech, Klinton Bicknell
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
Read more6/6/2024