House of Cards: Massive Weights in LLMs

0

Sign in to get full access
Overview
- Examines the issue of massive weights in large language models (LLMs)
- Discusses the implications of these large model sizes and the potential risks they pose
- Proposes approaches to address the challenges of massive weights in LLMs
Plain English Explanation
Large language models (LLMs) like GPT-3 and Transformers have become increasingly powerful, but they also have very large model sizes with millions or even billions of parameters. This paper explores the challenges posed by these "massive weights" in LLMs.
The key idea is that as LLMs grow larger, the individual weights (numerical values) within the model also become extremely large. This can lead to several issues, such as:
- Reduced Interpretability: The massive number of parameters makes it very difficult to understand how the model is making decisions and what information it has learned.
- Vulnerability to Adversarial Attacks: LLMs with massive weights may be more susceptible to carefully crafted adversarial inputs that can manipulate the model's behavior.
- Inefficient Deployment: Storing and running LLMs with massive weights requires a lot of computational resources, which can be challenging for real-world deployment.
The paper discusses potential approaches to address these challenges, such as weight pruning (removing unnecessary weights) and zero-shot weight transfer (efficiently transferring weights from a large model to a smaller one). By tackling the issue of massive weights, researchers aim to make LLMs more interpretable, robust, and efficient.
Technical Explanation
The paper begins by highlighting the rapid growth in the size of LLMs, with models like GPT-3 reaching hundreds of billions of parameters. This massive scale raises several concerns:
-
Interpretability: The sheer number of parameters makes it incredibly challenging to understand the inner workings of these models and how they make decisions. This lack of interpretability can hinder our ability to trust and verify the outputs of LLMs.
-
Adversarial Vulnerability: LLMs with massive weights may be more susceptible to carefully crafted adversarial inputs that can manipulate the model's behavior in unintended ways. This poses a significant security risk.
-
Deployment Inefficiency: Storing and running LLMs with massive weights requires substantial computational resources, which can be a bottleneck for real-world deployment, especially on resource-constrained devices.
To address these challenges, the paper explores several approaches:
- Weight Pruning: Techniques like simple and effective pruning can be used to selectively remove weights from the model without significantly impacting performance. This can help reduce the model size and improve efficiency.
- Zero-Shot Weight Transfer: Methods like the mean-field ansatz enable efficient transfer of knowledge from a large, pre-trained model to a smaller, more deployable model, without sacrificing performance.
- Depth Pruning: Selectively removing entire layers of the model, as explored in the deeper look at depth pruning paper, can also help address the challenges of massive weights.
By tackling the issue of massive weights in LLMs, researchers aim to improve the interpretability, robustness, and efficiency of these powerful models, paving the way for more trustworthy and practical real-world applications.
Critical Analysis
The paper raises important points about the challenges posed by massive weights in LLMs. The authors highlight valid concerns, such as the reduced interpretability, increased vulnerability to adversarial attacks, and deployment inefficiency. These are crucial issues that the AI research community needs to address as language models continue to grow in size and complexity.
The proposed approaches, such as weight pruning, zero-shot weight transfer, and depth pruning, are promising directions for mitigating the problems associated with massive weights. However, it's important to note that these techniques may have their own limitations and trade-offs. For example, weight pruning could potentially lead to a loss of model performance, while zero-shot weight transfer may be limited in its ability to fully capture the knowledge of the original large model.
Additionally, the paper does not delve deeply into the underlying reasons why LLMs have developed such massive weights in the first place. It would be valuable to understand the factors driving this trend, such as architectural choices, training data, or optimization strategies, to better address the root causes of the problem.
Further research and experimentation are needed to fully evaluate the effectiveness and practical applicability of the proposed solutions. As the field of AI continues to push the boundaries of language model capabilities, addressing the challenges of massive weights will be crucial for ensuring the reliability, safety, and widespread deployment of these powerful technologies.
Conclusion
This paper sheds light on the significant challenges posed by the massive weights in large language models (LLMs). As these models grow ever larger, with hundreds of billions of parameters, the authors highlight the critical issues of reduced interpretability, increased vulnerability to adversarial attacks, and deployment inefficiency.
To address these challenges, the paper explores several promising approaches, including weight pruning, zero-shot weight transfer, and depth pruning. These techniques aim to reduce the model size and complexity without sacrificing performance, ultimately making LLMs more interpretable, robust, and efficient.
While the proposed solutions are compelling, the authors acknowledge that further research and experimentation are needed to fully evaluate their effectiveness and practical applicability. Addressing the issue of massive weights in LLMs is crucial for the continued development and deployment of these powerful technologies, ensuring they are reliable, trustworthy, and accessible to a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!House of Cards: Massive Weights in LLMs
Jaehoon Oh, Seungjun Shin, Dokwan Oh
Massive activations, which manifest in specific feature dimensions of hidden states, introduce a significant bias in large language models (LLMs), leading to an overemphasis on the corresponding token. In this paper, we identify that massive activations originate not from the hidden state but from the intermediate state of a feed-forward network module in an early layer. Expanding on the previous observation that massive activations occur only in specific feature dimensions, we dive deep into the weights that cause massive activations. Specifically, we define top-$k$ massive weights as the weights that contribute to the dimensions with the top-$k$ magnitudes in the intermediate state. When these massive weights are set to zero, the functionality of LLMs is entirely disrupted. However, when all weights except for massive weights are set to zero, it results in a relatively minor performance drop, even though a much larger number of weights are set to zero. This implies that during the pre-training process, learning is dominantly focused on massive weights. Building on this observation, we propose a simple plug-and-play method called MacDrop (massive weights curriculum dropout), to rely less on massive weights during parameter-efficient fine-tuning. This method applies dropout to the pre-trained massive weights, starting with a high dropout probability and gradually decreasing it as fine-tuning progresses. Through experiments, we demonstrate that MacDrop generally improves performance across zero-shot downstream tasks and generation tasks.
Read more10/4/2024

0
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J. Zico Kolter, Zhuang Liu
We observe an empirical phenomenon in Large Language Models (LLMs) -- very few activations exhibit significantly larger values than others (e.g., 100,000 times larger). We call them massive activations. First, we demonstrate the widespread existence of massive activations across various LLMs and characterize their locations. Second, we find their values largely stay constant regardless of the input, and they function as indispensable bias terms in LLMs. Third, these massive activations lead to the concentration of attention probabilities to their corresponding tokens, and further, implicit bias terms in the self-attention output. Last, we also study massive activations in Vision Transformers. Code is available at https://github.com/locuslab/massive-activations.
Read more8/15/2024
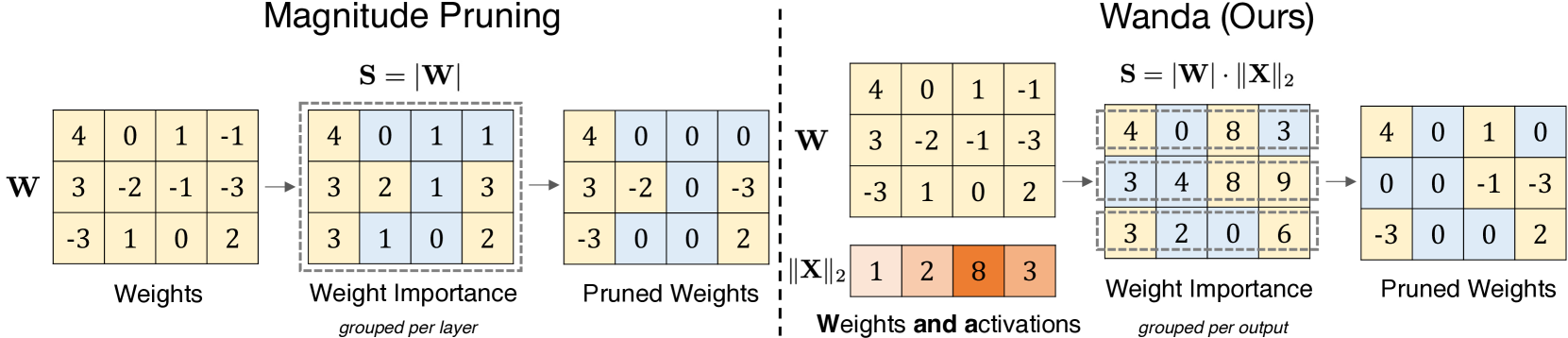
1
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
Read more5/7/2024

0
A deeper look at depth pruning of LLMs
Shoaib Ahmed Siddiqui, Xin Dong, Greg Heinrich, Thomas Breuel, Jan Kautz, David Krueger, Pavlo Molchanov
Large Language Models (LLMs) are not only resource-intensive to train but even more costly to deploy in production. Therefore, recent work has attempted to prune blocks of LLMs based on cheap proxies for estimating block importance, effectively removing 10% of blocks in well-trained LLaMa-2 and Mistral 7b models without any significant degradation of downstream metrics. In this paper, we explore different block importance metrics by considering adaptive metrics such as Shapley value in addition to static ones explored in prior work. We show that adaptive metrics exhibit a trade-off in performance between tasks i.e., improvement on one task may degrade performance on the other due to differences in the computed block influences. Furthermore, we extend this analysis from a complete block to individual self-attention and feed-forward layers, highlighting the propensity of the self-attention layers to be more amendable to pruning, even allowing removal of upto 33% of the self-attention layers without incurring any performance degradation on MMLU for Mistral 7b (significant reduction in costly maintenance of KV-cache). Finally, we look at simple performance recovery techniques to emulate the pruned layers by training lightweight additive bias or low-rank linear adapters. Performance recovery using emulated updates avoids performance degradation for the initial blocks (up to 5% absolute improvement on MMLU), which is either competitive or superior to the learning-based technique.
Read more7/24/2024