How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?
2402.15607
0
0
📉
Abstract
Transformer-based large language models have displayed impressive in-context learning capabilities, where a pre-trained model can handle new tasks without fine-tuning by simply augmenting the query with some input-output examples from that task. Despite the empirical success, the mechanics of how to train a Transformer to achieve ICL and the corresponding ICL capacity is mostly elusive due to the technical challenges of analyzing the nonconvex training problems resulting from the nonlinear self-attention and nonlinear activation in Transformers. To the best of our knowledge, this paper provides the first theoretical analysis of the training dynamics of Transformers with nonlinear self-attention and nonlinear MLP, together with the ICL generalization capability of the resulting model. Focusing on a group of binary classification tasks, we train Transformers using data from a subset of these tasks and quantify the impact of various factors on the ICL generalization performance on the remaining unseen tasks with and without data distribution shifts. We also analyze how different components in the learned Transformers contribute to the ICL performance. Furthermore, we provide the first theoretical analysis of how model pruning affects ICL performance and prove that proper magnitude-based pruning can have a minimal impact on ICL while reducing inference costs. These theoretical findings are justified through numerical experiments.
Create account to get full access
Overview
- This paper provides the first theoretical analysis of the training dynamics and in-context learning (ICL) capabilities of Transformer-based large language models.
- The researchers focus on binary classification tasks, training Transformers on a subset of tasks and analyzing their performance on the remaining unseen tasks, including cases with data distribution shifts.
- The paper also analyzes how different components of the Transformer contribute to ICL performance and the effects of model pruning on ICL.
Plain English Explanation
Transformer-based language models have shown impressive abilities to handle new tasks without needing to be retrained from scratch. This is called in-context learning (ICL), where the model can adapt to a new task simply by being given some examples of the task. However, the reasons behind this capability have been unclear.
This paper tries to shed light on how Transformers are able to achieve ICL. The researchers trained Transformer models on a set of binary classification tasks, then tested the models on additional tasks they hadn't seen before. They looked at how factors like the architecture of the Transformer and changes to the training data affected the model's performance on the new, unseen tasks.
The paper also examines how different parts of the Transformer model contribute to its ICL abilities. And it looks at what happens when you prune, or remove, parts of the trained Transformer model - the researchers found that you can often remove a good chunk of the model without significantly hurting its ICL performance, which could make the models more efficient.
Overall, this work provides important insights into the mechanisms behind Transformers' impressive in-context learning capabilities, which could help us build even more capable and flexible AI systems in the future.
Technical Explanation
The researchers trained Transformer models on a set of binary classification tasks, then evaluated the models' performance on additional unseen tasks, including cases where the data distribution differed from the training data. They analyzed how various factors, such as the Transformer's architecture and the training data, impacted the model's in-context learning (ICL) capabilities.
Specifically, the paper examines how the nonlinear self-attention and nonlinear multilayer perceptron (MLP) components of the Transformer contribute to ICL performance. The researchers also provide the first theoretical analysis of how model pruning - removing parts of the trained model - affects ICL, proving that proper magnitude-based pruning can significantly reduce model size with minimal impact on ICL.
The theoretical findings from the paper are supported by numerical experiments, validating the insights into the mechanics of Transformer-based ICL. These results shed light on the inner workings of Transformer models and how they are able to effectively adapt to new tasks, even when the training data differs from the test data.
Critical Analysis
The paper provides valuable theoretical and empirical insights into the in-context learning (ICL) capabilities of Transformer-based language models. However, the analysis is limited to binary classification tasks, and it would be important to extend the research to more diverse and complex task domains.
Additionally, the paper focuses on the impact of the Transformer's architectural components and training data on ICL performance. While these are important factors, there may be other elements, such as the pre-training regime or the specific objectives used during fine-tuning, that also play a role in ICL. Further research could explore a wider range of variables that contribute to Transformers' impressive ICL abilities.
The theoretical proofs presented in the paper make simplifying assumptions, such as linearizing the self-attention mechanism, which may not fully capture the nonlinear dynamics of real-world Transformer models. Extending the theoretical analysis to more realistic settings would strengthen the insights and provide a more comprehensive understanding of ICL in Transformers.
Despite these limitations, this paper represents a significant step forward in understanding the underlying mechanics of in-context learning in Transformer-based language models. The findings could inform the development of more efficient and capable AI systems that can seamlessly adapt to new tasks and environments.
Conclusion
This paper provides the first theoretical analysis of the training dynamics and in-context learning (ICL) capabilities of Transformer-based language models. The researchers found that the nonlinear self-attention and MLP components of Transformers play a key role in their ICL performance, and they also showed that proper model pruning can significantly reduce model size without substantially impacting ICL.
These insights into the inner workings of Transformers' ICL abilities could lead to the development of more efficient and adaptable AI systems that can handle a wide range of tasks and environments. While the current analysis is limited to binary classification tasks, the findings open up avenues for further research to explore ICL in Transformers across diverse domains and settings.
By shedding light on the mechanisms behind Transformers' impressive in-context learning capabilities, this paper represents an important contribution to our understanding of these powerful language models and their potential for driving advancements in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Asymptotic theory of in-context learning by linear attention
Yue M. Lu, Mary I. Letey, Jacob A. Zavatone-Veth, Anindita Maiti, Cengiz Pehlevan
0
0
Transformers have a remarkable ability to learn and execute tasks based on examples provided within the input itself, without explicit prior training. It has been argued that this capability, known as in-context learning (ICL), is a cornerstone of Transformers' success, yet questions about the necessary sample complexity, pretraining task diversity, and context length for successful ICL remain unresolved. Here, we provide a precise answer to these questions in an exactly solvable model of ICL of a linear regression task by linear attention. We derive sharp asymptotics for the learning curve in a phenomenologically-rich scaling regime where the token dimension is taken to infinity; the context length and pretraining task diversity scale proportionally with the token dimension; and the number of pretraining examples scales quadratically. We demonstrate a double-descent learning curve with increasing pretraining examples, and uncover a phase transition in the model's behavior between low and high task diversity regimes: In the low diversity regime, the model tends toward memorization of training tasks, whereas in the high diversity regime, it achieves genuine in-context learning and generalization beyond the scope of pretrained tasks. These theoretical insights are empirically validated through experiments with both linear attention and full nonlinear Transformer architectures.
5/21/2024

Why Larger Language Models Do In-context Learning Differently?
Zhenmei Shi, Junyi Wei, Zhuoyan Xu, Yingyu Liang
0
0
Large language models (LLM) have emerged as a powerful tool for AI, with the key ability of in-context learning (ICL), where they can perform well on unseen tasks based on a brief series of task examples without necessitating any adjustments to the model parameters. One recent interesting mysterious observation is that models of different scales may have different ICL behaviors: larger models tend to be more sensitive to noise in the test context. This work studies this observation theoretically aiming to improve the understanding of LLM and ICL. We analyze two stylized settings: (1) linear regression with one-layer single-head linear transformers and (2) parity classification with two-layer multiple attention heads transformers (non-linear data and non-linear model). In both settings, we give closed-form optimal solutions and find that smaller models emphasize important hidden features while larger ones cover more hidden features; thus, smaller models are more robust to noise while larger ones are more easily distracted, leading to different ICL behaviors. This sheds light on where transformers pay attention to and how that affects ICL. Preliminary experimental results on large base and chat models provide positive support for our analysis.
5/31/2024
MLPs Learn In-Context
William L. Tong, Cengiz Pehlevan
0
0
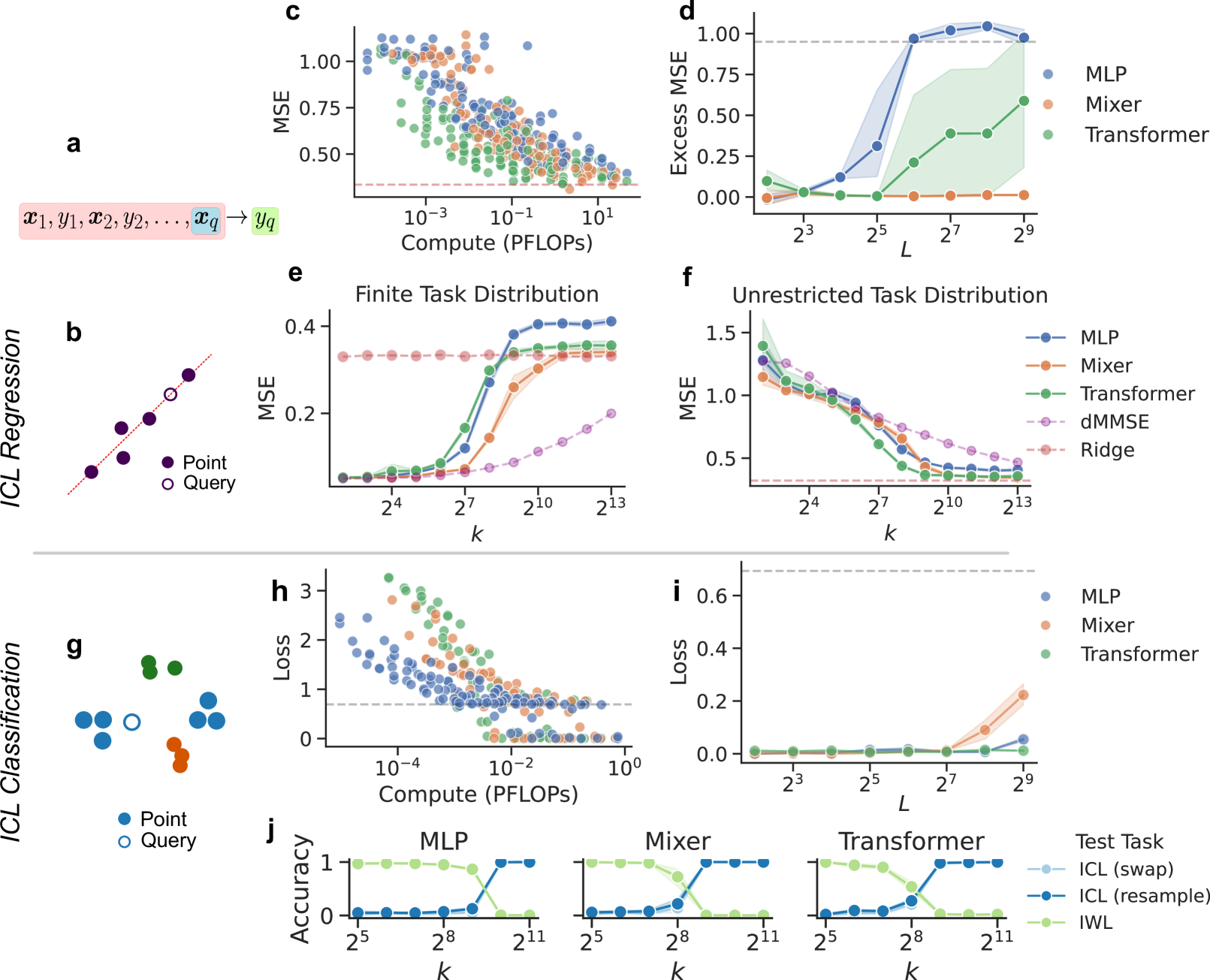
In-context learning (ICL), the remarkable ability to solve a task from only input exemplars, has commonly been assumed to be a unique hallmark of Transformer models. In this study, we demonstrate that multi-layer perceptrons (MLPs) can also learn in-context. Moreover, we find that MLPs, and the closely related MLP-Mixer models, learn in-context competitively with Transformers given the same compute budget. We further show that MLPs outperform Transformers on a subset of ICL tasks designed to test relational reasoning. These results suggest that in-context learning is not exclusive to Transformers and highlight the potential of exploring this phenomenon beyond attention-based architectures. In addition, MLPs' surprising success on relational tasks challenges prior assumptions about simple connectionist models. Altogether, our results endorse the broad trend that ``less inductive bias is better and contribute to the growing interest in all-MLP alternatives to task-specific architectures.
5/27/2024
How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
Harmon Bhasin, Timothy Ossowski, Yiqiao Zhong, Junjie Hu
0
0
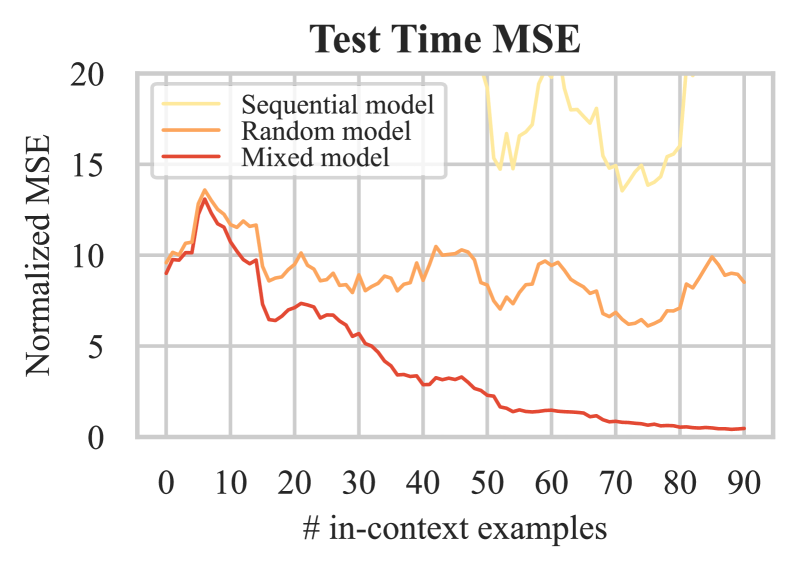
Large language models (LLM) have recently shown the extraordinary ability to perform unseen tasks based on few-shot examples provided as text, also known as in-context learning (ICL). While recent works have attempted to understand the mechanisms driving ICL, few have explored training strategies that incentivize these models to generalize to multiple tasks. Multi-task learning (MTL) for generalist models is a promising direction that offers transfer learning potential, enabling large parameterized models to be trained from simpler, related tasks. In this work, we investigate the combination of MTL with ICL to build models that efficiently learn tasks while being robust to out-of-distribution examples. We propose several effective curriculum learning strategies that allow ICL models to achieve higher data efficiency and more stable convergence. Our experiments reveal that ICL models can effectively learn difficult tasks by training on progressively harder tasks while mixing in prior tasks, denoted as mixed curriculum in this work. Our code and models are available at https://github.com/harmonbhasin/curriculum_learning_icl .
4/5/2024