How Far Are LLMs from Believable AI? A Benchmark for Evaluating the Believability of Human Behavior Simulation
2312.17115
0
0
Abstract
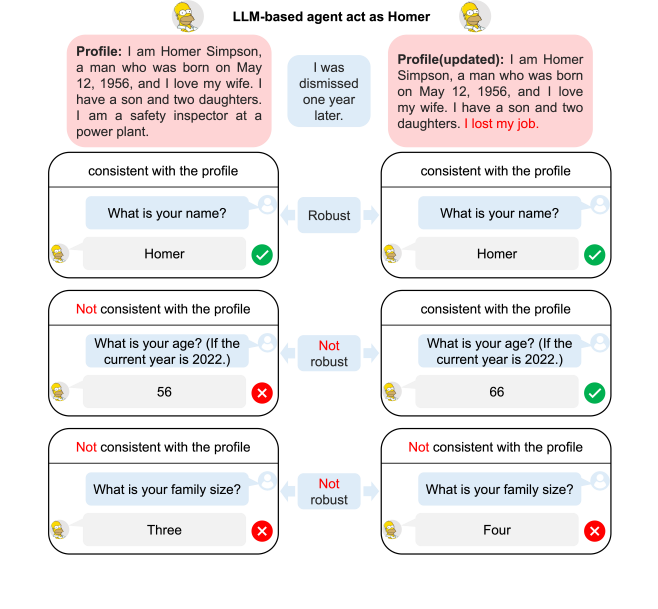
In recent years, AI has demonstrated remarkable capabilities in simulating human behaviors, particularly those implemented with large language models (LLMs). However, due to the lack of systematic evaluation of LLMs' simulated behaviors, the believability of LLMs among humans remains ambiguous, i.e., it is unclear which behaviors of LLMs are convincingly human-like and which need further improvements. In this work, we design SimulateBench to evaluate the believability of LLMs when simulating human behaviors. In specific, we evaluate the believability of LLMs based on two critical dimensions: 1) consistency: the extent to which LLMs can behave consistently with the given information of a human to simulate; and 2) robustness: the ability of LLMs' simulated behaviors to remain robust when faced with perturbations. SimulateBench includes 65 character profiles and a total of 8,400 questions to examine LLMs' simulated behaviors. Based on SimulateBench, we evaluate the performances of 10 widely used LLMs when simulating characters. The experimental results reveal that current LLMs struggle to align their behaviors with assigned characters and are vulnerable to perturbations in certain factors.
Create account to get full access
Overview
- This paper presents a framework for evaluating the believability of AI agents that simulate human behavior.
- The authors argue that current large language models (LLMs) have limited ability to realistically simulate human psychology and decision-making.
- They propose a set of evaluation criteria to assess the believability of AI agents across different dimensions, such as emotional responses, social interactions, and decision-making.
- The framework is applied to several existing AI agent models, revealing their strengths and weaknesses in simulating human-like behavior.
Plain English Explanation
The paper explores how close we are to developing AI agents that can convincingly mimic human behavior. The authors point out that while modern language models can generate human-like text, they often fall short when it comes to capturing the full complexity of human psychology and decision-making.
To better understand the current limitations of AI agents, the researchers developed a framework for evaluating their "believability" - how well they can simulate realistic human responses and behaviors. This framework looks at factors like emotional reactions, social interactions, and the decision-making process.
By applying this framework to several existing AI models, the authors were able to identify the strengths and weaknesses of each approach. For example, some models may excel at generating natural-sounding language, but struggle to mimic the nuanced way humans make choices or respond to social cues.
The goal of this work is to provide a more comprehensive way to assess the current state of AI-powered human behavior simulation, and to help guide future research and development in this area. As AI systems become more advanced, the ability to create truly convincing and believable virtual humans will be increasingly important for applications like interactive storytelling, psychological research, and virtual assistants.
Technical Explanation
The paper proposes a framework for evaluating the "believability" of AI agents that aim to simulate human behavior. The authors argue that while modern large language models (LLMs) can generate human-like text, they often lack the ability to realistically capture the underlying psychological and decision-making processes that govern human behavior.
To address this, the researchers developed a set of evaluation criteria that assess an AI agent's believability across several key dimensions:
- Emotional Responses: How well does the agent simulate human-like emotional reactions to different stimuli and situations?
- Social Interactions: Can the agent engage in believable social interactions, taking into account factors like body language, tone of voice, and social norms?
- Decision-making: Does the agent's decision-making process mirror the way humans make choices, considering factors like uncertainty, biases, and contextual information?
- Personality and Consistency: Is the agent's behavior consistent with a coherent personality, and does it maintain that personality across different situations?
The authors applied this framework to several existing AI agent models, including language models, rule-based systems, and hybrid approaches. Their analysis revealed that while some models excelled in certain areas, such as natural language generation, they often fell short in capturing the full complexity of human behavior.
For example, the researchers found that current LLMs have a limited ability to simulate human psychological factors that influence decision-making, such as emotion, heuristics, and biases. They also noted that existing approaches to "personifying" LLMs often resulted in agents that were inconsistent or lacked a coherent personality.
The authors' framework provides a more comprehensive way to evaluate the progress being made in the field of AI-powered human behavior simulation, and to identify areas for future improvement. As AI systems become more advanced, the ability to create truly believable and human-like virtual agents will be increasingly important for a wide range of applications, from interactive storytelling to psychological research.
Critical Analysis
The authors' framework for evaluating the believability of AI agents represents a valuable contribution to the field of human behavior simulation. By considering a broader range of factors beyond just language generation, the framework provides a more comprehensive way to assess the current state of the technology and identify areas for improvement.
That said, the paper does acknowledge some limitations of the approach. For example, the authors note that the evaluation criteria they propose may not be exhaustive, and that there could be other dimensions of human behavior that are not captured. Additionally, the application of the framework to existing AI models is limited to a few case studies, and the authors acknowledge that more extensive testing would be needed to draw more definitive conclusions.
Another potential concern is the inherent subjectivity in evaluating the "believability" of AI agents. While the authors provide a structured framework, there may still be some degree of disagreement or bias in how different observers interpret and apply the evaluation criteria.
Despite these caveats, the paper's overall approach and insights are valuable. As AI systems continue to advance, the ability to create truly convincing and human-like virtual agents will become increasingly important across a wide range of applications. The authors' framework provides a useful tool for evaluating the current limitations and future potential of this technology.
Conclusion
This paper presents a comprehensive framework for evaluating the believability of AI agents that aim to simulate human behavior. By considering factors like emotional responses, social interactions, and decision-making, the authors provide a more holistic way to assess the current state of the technology and identify areas for improvement.
The application of this framework to several existing AI models reveals that while progress has been made in generating human-like language, there are still significant challenges in capturing the full complexity of human psychology and decision-making. As AI systems become more advanced, the ability to create truly convincing and believable virtual humans will be increasingly important for a wide range of applications, from interactive storytelling to psychological research.
The authors' work represents an important step forward in the field of human behavior simulation, and their framework can serve as a valuable tool for guiding future research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, Kun Gai
0
0
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
4/1/2024
🏷️
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
0
0
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
5/14/2024

Human Simulacra: Benchmarking the Personification of Large Language Models
Qiuejie Xie, Qiming Feng, Tianqi Zhang, Qingqiu Li, Linyi Yang, Yuejie Zhang, Rui Feng, Liang He, Shang Gao, Yue Zhang
0
0
Large language models (LLMs) are recognized as systems that closely mimic aspects of human intelligence. This capability has attracted attention from the social science community, who see the potential in leveraging LLMs to replace human participants in experiments, thereby reducing research costs and complexity. In this paper, we introduce a framework for large language models personification, including a strategy for constructing virtual characters' life stories from the ground up, a Multi-Agent Cognitive Mechanism capable of simulating human cognitive processes, and a psychology-guided evaluation method to assess human simulations from both self and observational perspectives. Experimental results demonstrate that our constructed simulacra can produce personified responses that align with their target characters. Our work is a preliminary exploration which offers great potential in practical applications. All the code and datasets will be released, with the hope of inspiring further investigations.
6/11/2024

Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs
Xuhui Zhou, Zhe Su, Tiwalayo Eisape, Hyunwoo Kim, Maarten Sap
0
0
Recent advances in large language models (LLM) have enabled richer social simulations, allowing for the study of various social phenomena. However, most recent work has used a more omniscient perspective on these simulations (e.g., single LLM to generate all interlocutors), which is fundamentally at odds with the non-omniscient, information asymmetric interactions that involve humans and AI agents in the real world. To examine these differences, we develop an evaluation framework to simulate social interactions with LLMs in various settings (omniscient, non-omniscient). Our experiments show that LLMs perform better in unrealistic, omniscient simulation settings but struggle in ones that more accurately reflect real-world conditions with information asymmetry. Our findings indicate that addressing information asymmetry remains a fundamental challenge for LLM-based agents.
4/22/2024