How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models

0

Sign in to get full access
Overview
- This paper evaluates the performance of large language models (LLMs) on Cantonese, a Chinese language spoken in Hong Kong and some surrounding regions.
- The researchers develop a small-scale Cantonese neural network and benchmark it against several LLMs to understand the current state of Cantonese NLP capabilities.
- The results provide insights into the strengths and limitations of LLMs for processing Cantonese text, which can inform future model development and applications.
Plain English Explanation
The paper looks at how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - perform on Cantonese, a Chinese language spoken in Hong Kong and nearby areas. The researchers built a smaller, specialized Cantonese neural network and compared its abilities to several popular LLMs.
This gives us a sense of the current state of Cantonese natural language processing (NLP) - how good these AI systems are at tasks like understanding Cantonese text, answering questions, or translating between Cantonese and other languages. The findings can guide future development of Cantonese-capable AI models and applications.
Technical Explanation
The researchers first developed a small-scale Cantonese neural network as a baseline to compare against the LLMs. They then evaluated the Cantonese capabilities of several LLMs, including GPT-3, ERNIE, and PanGu-Alpha, on a variety of NLP tasks such as text classification, question answering, and machine translation.
The results showed that the LLMs generally performed well on simpler Cantonese tasks like text classification, but struggled more on more complex tasks like question answering and translation. The smaller, specialized Cantonese network outperformed the LLMs on several benchmarks, indicating there is still room for improvement in adapting these powerful language models to handle Cantonese effectively.
Critical Analysis
The paper provides a thorough and systematic evaluation of LLM Cantonese capabilities, which is valuable given the relative lack of research in this area. However, the authors acknowledge that their Cantonese dataset and benchmark tasks may not fully capture the nuances and complexities of real-world Cantonese language use.
Additionally, the LLMs tested were not specifically trained or fine-tuned on Cantonese data, so the results may not reflect the models' full potential if they were given more Cantonese-focused training. Further research is needed to explore techniques for better adapting LLMs to Cantonese and other under-resourced languages.
Conclusion
This study provides important insights into the current state of Cantonese NLP capabilities using large language models. While the LLMs showed promise on simpler Cantonese tasks, they still struggle compared to a specialized Cantonese network, highlighting the need for continued research and development to advance Cantonese language AI. The findings can inform future efforts to build more robust and capable Cantonese NLP systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models
Jiyue Jiang, Liheng Chen, Pengan Chen, Sheng Wang, Qinghang Bao, Lingpeng Kong, Yu Li, Chuan Wu
The rapid evolution of large language models (LLMs) has transformed the competitive landscape in natural language processing (NLP), particularly for English and other data-rich languages. However, underrepresented languages like Cantonese, spoken by over 85 million people, face significant development gaps, which is particularly concerning given the economic significance of the Guangdong-Hong Kong-Macau Greater Bay Area, and in substantial Cantonese-speaking populations in places like Singapore and North America. Despite its wide use, Cantonese has scant representation in NLP research, especially compared to other languages from similarly developed regions. To bridge these gaps, we outline current Cantonese NLP methods and introduce new benchmarks designed to evaluate LLM performance in factual generation, mathematical logic, complex reasoning, and general knowledge in Cantonese, which aim to advance open-source Cantonese LLM technology. We also propose future research directions and recommended models to enhance Cantonese LLM development.
Read more8/30/2024
↗️
0
Unveiling the Competitive Dynamics: A Comparative Evaluation of American and Chinese LLMs
Zhenhui Jiang, Jiaxin Li, Yang Liu
The strategic significance of Large Language Models (LLMs) in economic expansion, innovation, societal development, and national security has been increasingly recognized since the advent of ChatGPT. This study provides a comprehensive comparative evaluation of American and Chinese LLMs in both English and Chinese contexts. We proposed a comprehensive evaluation framework that encompasses natural language proficiency, disciplinary expertise, and safety and responsibility, and systematically assessed 16 prominent models from the US and China under various operational tasks and scenarios. Our key findings show that GPT 4-Turbo is at the forefront in English contexts, whereas Ernie-Bot 4 stands out in Chinese contexts. The study also highlights disparities in LLM performance across languages and tasks, stressing the necessity for linguistically and culturally nuanced model development. The complementary strengths of American and Chinese LLMs point to the value of Sino-US collaboration in advancing LLM technology. The research presents the current LLM competition landscape and offers valuable insights for policymakers and businesses regarding strategic LLM investments and development. Future work will expand on this framework to include emerging LLM multimodal capabilities and business application assessments.
Read more5/22/2024
0
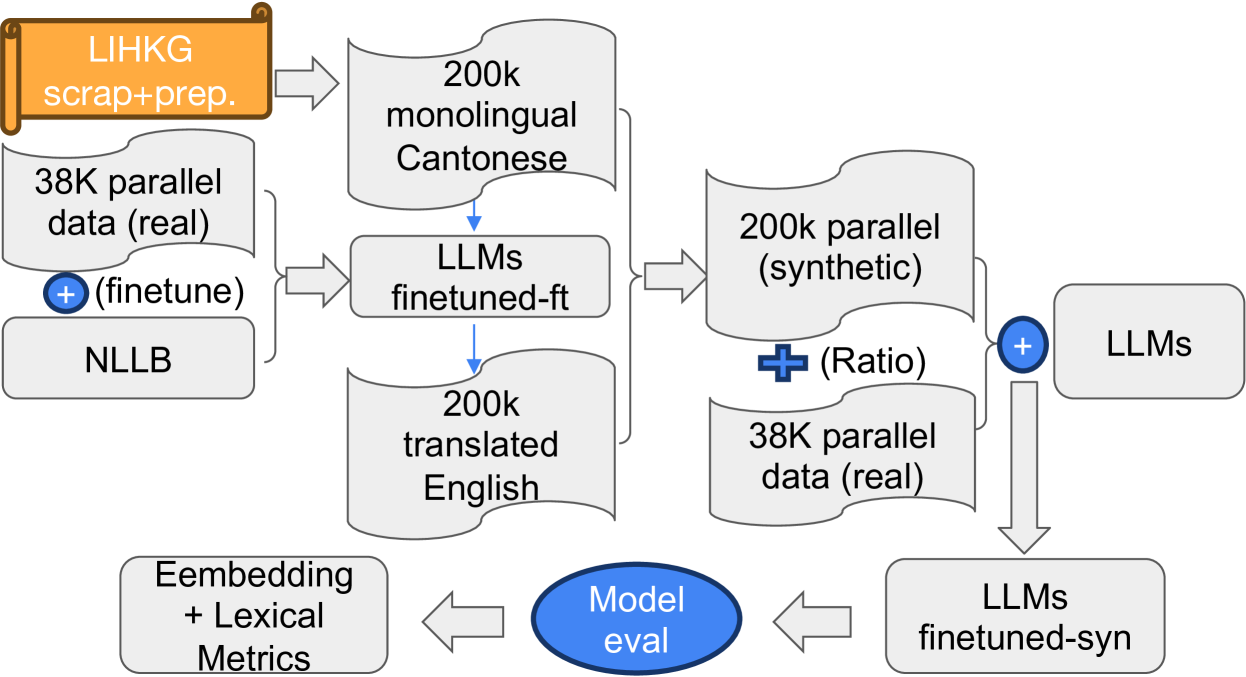
CantonMT: Cantonese to English NMT Platform with Fine-Tuned Models Using Synthetic Back-Translation Data
Kung Yin Hong, Lifeng Han, Riza Batista-Navarro, Goran Nenadic
Neural Machine Translation (NMT) for low-resource languages is still a challenging task in front of NLP researchers. In this work, we deploy a standard data augmentation methodology by back-translation to a new language translation direction Cantonese-to-English. We present the models we fine-tuned using the limited amount of real data and the synthetic data we generated using back-translation including OpusMT, NLLB, and mBART. We carried out automatic evaluation using a range of different metrics including lexical-based and embedding-based. Furthermore. we create a user-friendly interface for the models we included in thistextsc{ CantonMT} research project and make it available to facilitate Cantonese-to-English MT research. Researchers can add more models into this platform via our open-sourcetextsc{ CantonMT} toolkit url{https://github.com/kenrickkung/CantoneseTranslation}.
Read more6/11/2024

0
FoundaBench: Evaluating Chinese Fundamental Knowledge Capabilities of Large Language Models
Wei Li, Ren Ma, Jiang Wu, Chenya Gu, Jiahui Peng, Jinyang Len, Songyang Zhang, Hang Yan, Dahua Lin, Conghui He
In the burgeoning field of large language models (LLMs), the assessment of fundamental knowledge remains a critical challenge, particularly for models tailored to Chinese language and culture. This paper introduces FoundaBench, a pioneering benchmark designed to rigorously evaluate the fundamental knowledge capabilities of Chinese LLMs. FoundaBench encompasses a diverse array of 3354 multiple-choice questions across common sense and K-12 educational subjects, meticulously curated to reflect the breadth and depth of everyday and academic knowledge. We present an extensive evaluation of 12 state-of-the-art LLMs using FoundaBench, employing both traditional assessment methods and our CircularEval protocol to mitigate potential biases in model responses. Our results highlight the superior performance of models pre-trained on Chinese corpora, and reveal a significant disparity between models' reasoning and memory recall capabilities. The insights gleaned from FoundaBench evaluations set a new standard for understanding the fundamental knowledge of LLMs, providing a robust framework for future advancements in the field.
Read more4/30/2024