CantonMT: Cantonese to English NMT Platform with Fine-Tuned Models Using Synthetic Back-Translation Data

0
Sign in to get full access
Overview
- This paper presents CantonMT, a Cantonese to English neural machine translation (NMT) platform that uses fine-tuned models and synthetic back-translation data.
- The researchers investigate the impact of model switching mechanisms on translation quality and examine the effectiveness of using back-translated data to improve NMT performance.
- The paper also provides insights into the robustness of massively multilingual NMT models and explores techniques for improving language models trained on translated data.
Plain English Explanation
The paper describes a new platform called CantonMT that can translate text from Cantonese (a Chinese dialect) to English. The researchers developed this platform by taking a pre-existing machine translation model and "fine-tuning" it, which means they further trained the model using additional Cantonese-English translation data.
One key aspect of their approach is the use of "back-translation." This involves automatically translating English text into Cantonese, and then using that Cantonese text along with the original English to further train the translation model. The researchers found that this back-translation data helped improve the performance of the CantonMT platform.
The paper also explores how the choice of "model switching" - the way the model decides which parts of its knowledge to use for a given translation - can impact the quality of the translations. Additionally, the researchers investigate the overall robustness and reliability of multilingual machine translation models, and techniques for improving language models that are trained on translated text data.
Technical Explanation
The researchers developed the CantonMT platform, which uses fine-tuned neural machine translation (NMT) models to translate text from Cantonese to English. They investigated the impact of different model switching mechanisms on translation quality, and evaluated the effectiveness of using synthetic back-translation data to improve NMT performance.
The paper also presents an empirical study on the robustness of massively multilingual NMT models, as well as techniques for improving language models trained on translated data. Additionally, the researchers explored methods for guiding large language models to perform effective post-editing for machine translation.
The findings from this work have implications for the development of robust and high-performing machine translation systems, particularly for language pairs where parallel training data is scarce, such as Cantonese and English.
Critical Analysis
The paper provides a comprehensive investigation of the CantonMT platform and the various techniques used to improve its performance. The researchers acknowledge the limitations of their work, such as the relatively small size of the parallel Cantonese-English dataset used for fine-tuning the models.
One potential concern is the reliance on synthetic back-translation data, which could introduce biases or other issues into the training process. The researchers mention the need for further research to fully understand the impact of this approach.
Additionally, the study of model switching mechanisms and robustness of multilingual NMT models is an important area of inquiry, but the paper does not delve deeply into the theoretical or practical implications of these findings. More discussion on the broader significance and potential applications of these insights would be valuable.
Overall, the paper makes a valuable contribution to the field of machine translation, particularly for low-resource language pairs like Cantonese and English. The researchers have identified several promising directions for future research to build upon this work.
Conclusion
The CantonMT platform presented in this paper demonstrates the potential of using fine-tuned NMT models and synthetic back-translation data to improve the translation of Cantonese to English. The researchers' investigations into model switching mechanisms, the robustness of multilingual NMT models, and techniques for improving language models trained on translated data provide valuable insights for the development of more effective and reliable machine translation systems.
While the paper highlights several limitations and areas for further research, the overall findings have important implications for expanding access to high-quality translation services, particularly for language pairs with limited parallel data. As machine translation technology continues to evolve, studies like this one will play a crucial role in advancing the field and unlocking new possibilities for cross-cultural communication and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CantonMT: Cantonese to English NMT Platform with Fine-Tuned Models Using Synthetic Back-Translation Data
Kung Yin Hong, Lifeng Han, Riza Batista-Navarro, Goran Nenadic
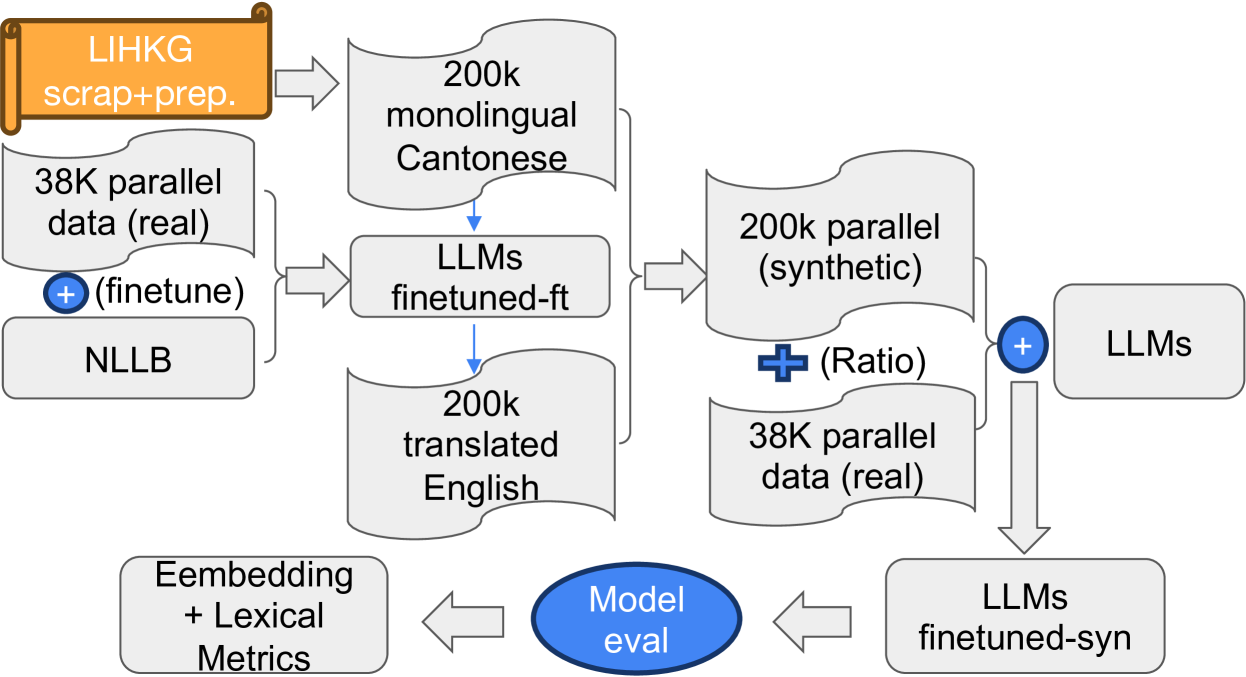
Neural Machine Translation (NMT) for low-resource languages is still a challenging task in front of NLP researchers. In this work, we deploy a standard data augmentation methodology by back-translation to a new language translation direction Cantonese-to-English. We present the models we fine-tuned using the limited amount of real data and the synthetic data we generated using back-translation including OpusMT, NLLB, and mBART. We carried out automatic evaluation using a range of different metrics including lexical-based and embedding-based. Furthermore. we create a user-friendly interface for the models we included in thistextsc{ CantonMT} research project and make it available to facilitate Cantonese-to-English MT research. Researchers can add more models into this platform via our open-sourcetextsc{ CantonMT} toolkit url{https://github.com/kenrickkung/CantoneseTranslation}.
Read more6/11/2024

0
CANTONMT: Investigating Back-Translation and Model-Switch Mechanisms for Cantonese-English Neural Machine Translation
Kung Yin Hong, Lifeng Han, Riza Batista-Navarro, Goran Nenadic
This paper investigates the development and evaluation of machine translation models from Cantonese to English, where we propose a novel approach to tackle low-resource language translations. The main objectives of the study are to develop a model that can effectively translate Cantonese to English and evaluate it against state-of-the-art commercial models. To achieve this, a new parallel corpus has been created by combining different available corpora online with preprocessing and cleaning. In addition, a monolingual Cantonese dataset has been created through web scraping to aid the synthetic parallel corpus generation. Following the data collection process, several approaches, including fine-tuning models, back-translation, and model switch, have been used. The translation quality of models has been evaluated with multiple quality metrics, including lexicon-based metrics (SacreBLEU and hLEPOR) and embedding-space metrics (COMET and BERTscore). Based on the automatic metrics, the best model is selected and compared against the 2 best commercial translators using the human evaluation framework HOPES. The best model proposed in this investigation (NLLB-mBART) with model switch mechanisms has reached comparable and even better automatic evaluation scores against State-of-the-art commercial models (Bing and Baidu Translators), with a SacreBLEU score of 16.8 on our test set. Furthermore, an open-source web application has been developed to allow users to translate between Cantonese and English, with the different trained models available for effective comparisons between models from this investigation and users. CANTONMT is available at https://github.com/kenrickkung/CantoneseTranslation
Read more5/15/2024

0
How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models
Jiyue Jiang, Liheng Chen, Pengan Chen, Sheng Wang, Qinghang Bao, Lingpeng Kong, Yu Li, Chuan Wu
The rapid evolution of large language models (LLMs) has transformed the competitive landscape in natural language processing (NLP), particularly for English and other data-rich languages. However, underrepresented languages like Cantonese, spoken by over 85 million people, face significant development gaps, which is particularly concerning given the economic significance of the Guangdong-Hong Kong-Macau Greater Bay Area, and in substantial Cantonese-speaking populations in places like Singapore and North America. Despite its wide use, Cantonese has scant representation in NLP research, especially compared to other languages from similarly developed regions. To bridge these gaps, we outline current Cantonese NLP methods and introduce new benchmarks designed to evaluate LLM performance in factual generation, mathematical logic, complex reasoning, and general knowledge in Cantonese, which aim to advance open-source Cantonese LLM technology. We also propose future research directions and recommended models to enhance Cantonese LLM development.
Read more8/30/2024
🧠
0
An Empirical Study on the Robustness of Massively Multilingual Neural Machine Translation
Supryadi, Leiyu Pan, Deyi Xiong
Massively multilingual neural machine translation (MMNMT) has been proven to enhance the translation quality of low-resource languages. In this paper, we empirically investigate the translation robustness of Indonesian-Chinese translation in the face of various naturally occurring noise. To assess this, we create a robustness evaluation benchmark dataset for Indonesian-Chinese translation. This dataset is automatically translated into Chinese using four NLLB-200 models of different sizes. We conduct both automatic and human evaluations. Our in-depth analysis reveal the correlations between translation error types and the types of noise present, how these correlations change across different model sizes, and the relationships between automatic evaluation indicators and human evaluation indicators. The dataset is publicly available at https://github.com/tjunlp-lab/ID-ZH-MTRobustEval.
Read more5/14/2024