FoundaBench: Evaluating Chinese Fundamental Knowledge Capabilities of Large Language Models
2404.18359
0
0

Abstract
In the burgeoning field of large language models (LLMs), the assessment of fundamental knowledge remains a critical challenge, particularly for models tailored to Chinese language and culture. This paper introduces FoundaBench, a pioneering benchmark designed to rigorously evaluate the fundamental knowledge capabilities of Chinese LLMs. FoundaBench encompasses a diverse array of 3354 multiple-choice questions across common sense and K-12 educational subjects, meticulously curated to reflect the breadth and depth of everyday and academic knowledge. We present an extensive evaluation of 12 state-of-the-art LLMs using FoundaBench, employing both traditional assessment methods and our CircularEval protocol to mitigate potential biases in model responses. Our results highlight the superior performance of models pre-trained on Chinese corpora, and reveal a significant disparity between models' reasoning and memory recall capabilities. The insights gleaned from FoundaBench evaluations set a new standard for understanding the fundamental knowledge of LLMs, providing a robust framework for future advancements in the field.
Create account to get full access
Overview
- This paper introduces FoundaBench, a benchmark designed to evaluate the Chinese fundamental knowledge capabilities of large language models (LLMs).
- FoundaBench covers a diverse range of topics, including history, geography, culture, and science, aiming to assess the broad knowledge of LLMs.
- The benchmark includes both multiple-choice and open-ended questions, challenging models to demonstrate their understanding of Chinese fundamental knowledge.
- The authors evaluate several state-of-the-art LLMs on FoundaBench and provide insights into their strengths and weaknesses in this domain.
Plain English Explanation
The paper presents a new benchmark called FoundaBench that is designed to test the knowledge of large language models (LLMs) on a wide range of fundamental topics related to Chinese history, geography, culture, and science. The goal is to evaluate how well these powerful AI models can demonstrate an understanding of core knowledge about China.
FoundaBench includes both multiple-choice and open-ended questions, which allows it to assess different aspects of the models' capabilities. The authors tested several cutting-edge LLMs on this benchmark and analyzed their performance, identifying areas where the models excel as well as where they struggle. This provides valuable insights into the current state of large language models and their ability to comprehend and reason about fundamental Chinese knowledge.
By creating a comprehensive benchmark like FoundaBench, the researchers aim to better understand the strengths and limitations of LLMs when it comes to mastering the breadth of information that humans typically acquire through education and life experience. This can help guide the development of more capable and well-rounded AI systems in the future.
Technical Explanation
The paper introduces FoundaBench, a new benchmark for evaluating the Chinese fundamental knowledge capabilities of large language models (LLMs). FoundaBench covers a diverse range of topics, including history, geography, culture, and science, with the goal of assessing the broad knowledge of these models.
The benchmark consists of both multiple-choice and open-ended questions, allowing it to measure different aspects of the models' understanding. The authors evaluate several state-of-the-art LLMs, including Causalbench, Measuring Taiwanese Mandarin Language Understanding, and Chinese Tiny LLM Pretraining, on the FoundaBench test set.
The results provide insights into the strengths and weaknesses of these LLMs in terms of their ability to recall and reason about fundamental Chinese knowledge. The authors identify areas where the models excel, as well as areas where they struggle, and discuss the implications of these findings for the development of more capable and well-rounded AI systems.
Critical Analysis
The FoundaBench benchmark presented in this paper is a valuable contribution to the field of language model evaluation, as it focuses on a specific and important domain of knowledge – Chinese fundamental knowledge. By testing LLMs on a diverse set of questions covering history, geography, culture, and science, the authors are able to gain a more comprehensive understanding of the models' capabilities and limitations.
However, the paper does not provide a detailed discussion of the limitations and caveats of the FoundaBench benchmark itself. For example, it would be helpful to know how the questions were selected and curated, and whether the benchmark covers the most crucial aspects of Chinese fundamental knowledge. Additionally, the paper does not address potential biases or shortcomings in the LLMs' training data or pretraining approaches that could impact their performance on this benchmark.
Furthermore, the critical analysis section could be strengthened by considering broader implications and potential societal impacts of this research. For instance, it would be interesting to discuss how the findings from FoundaBench could inform the development of more culturally-aware and inclusive AI systems, or how these insights could be applied to improve educational resources and curricula.
Conclusion
The FoundaBench benchmark presented in this paper is a valuable tool for evaluating the Chinese fundamental knowledge capabilities of large language models. By testing a diverse range of topics, the benchmark provides a comprehensive assessment of the models' strengths and weaknesses in this domain.
The results from the FoundaBench evaluation offer insights that can inform the development of more capable and well-rounded AI systems, better equipped to understand and reason about fundamental knowledge related to Chinese history, geography, culture, and science. As the field of language model research continues to advance, benchmarks like FoundaBench will play an important role in driving progress and ensuring that these models become increasingly useful and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

NewsBench: A Systematic Evaluation Framework for Assessing Editorial Capabilities of Large Language Models in Chinese Journalism
Miao Li, Ming-Bin Chen, Bo Tang, Shengbin Hou, Pengyu Wang, Haiying Deng, Zhiyu Li, Feiyu Xiong, Keming Mao, Peng Cheng, Yi Luo
0
0
We present NewsBench, a novel evaluation framework to systematically assess the capabilities of Large Language Models (LLMs) for editorial capabilities in Chinese journalism. Our constructed benchmark dataset is focused on four facets of writing proficiency and six facets of safety adherence, and it comprises manually and carefully designed 1,267 test samples in the types of multiple choice questions and short answer questions for five editorial tasks in 24 news domains. To measure performances, we propose different GPT-4 based automatic evaluation protocols to assess LLM generations for short answer questions in terms of writing proficiency and safety adherence, and both are validated by the high correlations with human evaluations. Based on the systematic evaluation framework, we conduct a comprehensive analysis of ten popular LLMs which can handle Chinese. The experimental results highlight GPT-4 and ERNIE Bot as top performers, yet reveal a relative deficiency in journalistic safety adherence in creative writing tasks. Our findings also underscore the need for enhanced ethical guidance in machine-generated journalistic content, marking a step forward in aligning LLMs with journalistic standards and safety considerations.
6/5/2024
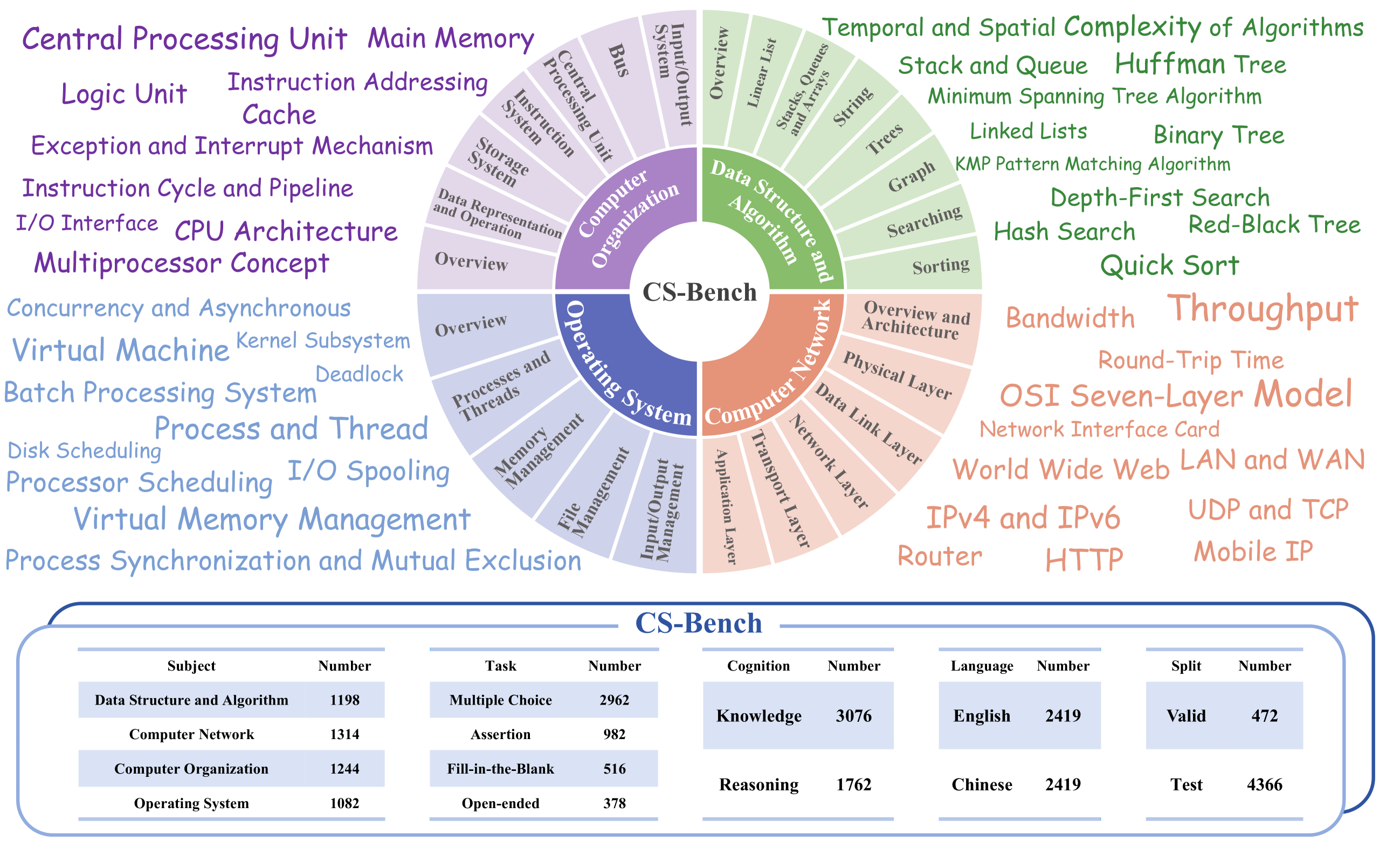
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024

CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Yizhi LI, Ge Zhang, Xingwei Qu, Jiali Li, Zhaoqun Li, Zekun Wang, Hao Li, Ruibin Yuan, Yinghao Ma, Kai Zhang, Wangchunshu Zhou, Yiming Liang, Lei Zhang, Lei Ma, Jiajun Zhang, Zuowen Li, Stephen W. Huang, Chenghua Lin, Jie Fu
0
0
The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate data contamination, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work not only uncovers the current limitations of LLMs in handling Chinese language tasks but also sets a new standard for future LLM generalizability research, pushing towards the development of more adaptable, culturally informed, and linguistically diverse models.
6/5/2024
💬
CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
Yang Lei, Jiangtong Li, Dawei Cheng, Zhijun Ding, Changjun Jiang
0
0
Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
5/22/2024