How is Visual Attention Influenced by Text Guidance? Database and Model

0

Sign in to get full access
Overview
- This paper presents a new database and model for understanding how visual attention is influenced by textual guidance.
- The researchers collected eye-tracking data from participants viewing images with different types of textual cues, and used this data to train a model that can predict visual attention based on the text.
- The paper explores the interplay between language and vision, and how textual information can shape our visual perception and focus.
Plain English Explanation
The researchers in this study wanted to understand how the words and phrases we see can affect where we look and what we pay attention to in images. To do this, they created a new database of images with different types of text cues, and tracked people's eye movements as they viewed these images.
By analyzing the eye-tracking data, the researchers were able to train a machine learning model that can predict where people will focus their attention based on the text that is present. This model provides insights into the complex interplay between language and visual perception - how the words and captions we read can guide and influence what we notice in an image.
The findings from this work could have applications in areas like visual search, image captioning, and human-computer interaction, where understanding the role of text in shaping visual attention is important. It also raises interesting questions about the cognitive processes underlying our ability to integrate textual and visual information.
Technical Explanation
The researchers first created a new database of images with different types of textual cues, such as captions, keywords, and free-form text. They then conducted an eye-tracking study, where participants viewed these images while their gaze patterns were recorded.
From the eye-tracking data, the researchers extracted features like fixation durations, saccade amplitudes, and scanpaths, and used these to train a multimodal attention prediction model. This model takes as input both the image and the associated text, and outputs a saliency map that predicts where the viewer is likely to focus their attention.
The model uses a convolutional neural network to process the visual information, and a recurrent neural network to process the textual information. The outputs of these networks are then combined through a multimodal fusion module to generate the final attention prediction.
The researchers evaluated the model's performance on several benchmark datasets, and found that it outperformed existing state-of-the-art visual attention models, especially in cases where textual cues were present. This suggests that incorporating language-based information can significantly improve our ability to understand and predict human visual attention.
Critical Analysis
One limitation of the study is that the eye-tracking data was collected in a controlled laboratory setting, which may not fully capture the complexity of real-world visual search and attention processes. Additionally, the textual cues used in the study were relatively simple and straightforward; it would be interesting to see how the model performs on more nuanced or contextual language.
Another potential issue is the reliance on saliency-based attention prediction, which may not fully capture the top-down, goal-oriented nature of human visual attention. [Future work could explore more advanced attention modeling techniques, such as those used in disentangled text-to-image personalization or severity-controlled text-to-image generation.]
That said, the researchers' approach of integrating textual and visual information is a promising direction, and the new database they created could be a valuable resource for the broader computer vision and cognitive science research communities.
Conclusion
This paper presents an important step forward in understanding the complex interplay between language and visual attention. By creating a new dataset and training a multimodal attention prediction model, the researchers have provided valuable insights into how textual cues can shape our visual perception and focus.
The findings from this work have potential applications in areas like visual search, image captioning, and human-computer interaction, where understanding the role of text in guiding visual attention is crucial. Moreover, the research raises interesting questions about the cognitive processes underlying our ability to integrate textual and visual information, which could have broader implications for the study of human perception and cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How is Visual Attention Influenced by Text Guidance? Database and Model
Yinan Sun, Xiongkuo Min, Huiyu Duan, Guangtao Zhai
The analysis and prediction of visual attention have long been crucial tasks in the fields of computer vision and image processing. In practical applications, images are generally accompanied by various text descriptions, however, few studies have explored the influence of text descriptions on visual attention, let alone developed visual saliency prediction models considering text guidance. In this paper, we conduct a comprehensive study on text-guided image saliency (TIS) from both subjective and objective perspectives. Specifically, we construct a TIS database named SJTU-TIS, which includes 1200 text-image pairs and the corresponding collected eye-tracking data. Based on the established SJTU-TIS database, we analyze the influence of various text descriptions on visual attention. Then, to facilitate the development of saliency prediction models considering text influence, we construct a benchmark for the established SJTU-TIS database using state-of-the-art saliency models. Finally, considering the effect of text descriptions on visual attention, while most existing saliency models ignore this impact, we further propose a text-guided saliency (TGSal) prediction model, which extracts and integrates both image features and text features to predict the image saliency under various text-description conditions. Our proposed model significantly outperforms the state-of-the-art saliency models on both the SJTU-TIS database and the pure image saliency databases in terms of various evaluation metrics. The SJTU-TIS database and the code of the proposed TGSal model will be released at: https://github.com/IntMeGroup/TGSal.
Read more4/15/2024
🖼️
0
GazeFusion: Saliency-guided Image Generation
Yunxiang Zhang, Nan Wu, Connor Z. Lin, Gordon Wetzstein, Qi Sun
Diffusion models offer unprecedented image generation capabilities given just a text prompt. While emerging control mechanisms have enabled users to specify the desired spatial arrangements of the generated content, they cannot predict or control where viewers will pay more attention due to the complexity of human vision. Recognizing the critical necessity of attention-controllable image generation in practical applications, we present a saliency-guided framework to incorporate the data priors of human visual attention into the generation process. Given a desired viewer attention distribution, our control module conditions a diffusion model to generate images that attract viewers' attention toward desired areas. To assess the efficacy of our approach, we performed an eye-tracked user study and a large-scale model-based saliency analysis. The results evidence that both the cross-user eye gaze distributions and the saliency model predictions align with the desired attention distributions. Lastly, we outline several applications, including interactive design of saliency guidance, attention suppression in unwanted regions, and adaptive generation for varied display/viewing conditions.
Read more7/8/2024
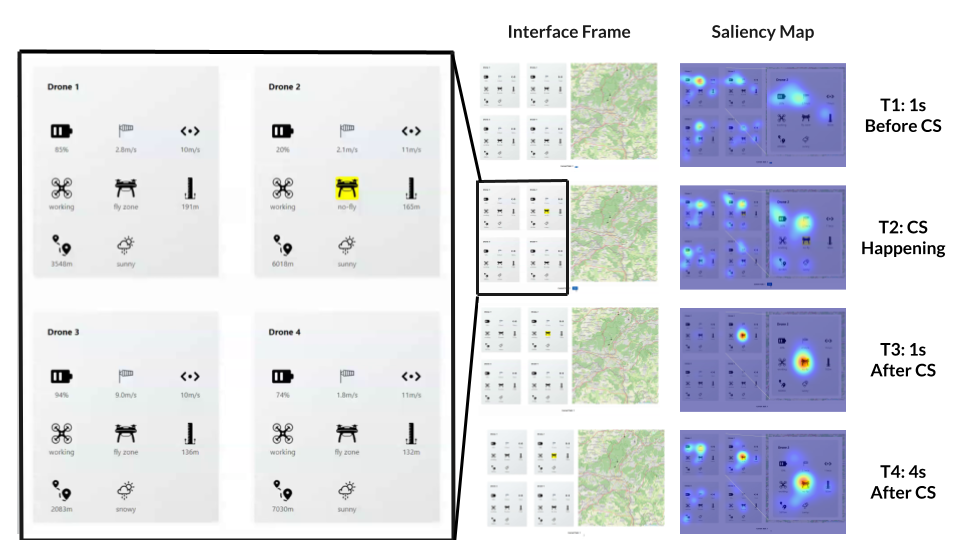
0
Enhancing Saliency Prediction in Monitoring Tasks: The Role of Visual Highlights
Zekun Wu, Anna Maria Feit
This study examines the role of visual highlights in guiding user attention in drone monitoring tasks, employing a simulated interface for observation. The experiment results show that such highlights can significantly expedite the visual attention on the corresponding area. Based on this observation, we leverage both the temporal and spatial information in the highlight to develop a new saliency model: the highlight-informed saliency model (HISM), to infer the visual attention change in the highlight condition. Our findings show the effectiveness of visual highlights in enhancing user attention and demonstrate the potential of incorporating these cues into saliency prediction models.
Read more5/17/2024

0
GazeCLIP: Towards Enhancing Gaze Estimation via Text Guidance
Jun Wang, Hao Ruan, Mingjie Wang, Chuanghui Zhang, Huachun Li, Jun Zhou
Over the past decade, visual gaze estimation has garnered increasing attention within the research community, owing to its wide-ranging application scenarios. While existing estimation approaches have achieved remarkable success in enhancing prediction accuracy, they primarily infer gaze from single-image signals, neglecting the potential benefits of the currently dominant text guidance. Notably, visual-language collaboration has been extensively explored across various visual tasks, such as image synthesis and manipulation, leveraging the remarkable transferability of large-scale Contrastive Language-Image Pre-training (CLIP) model. Nevertheless, existing gaze estimation approaches overlook the rich semantic cues conveyed by linguistic signals and the priors embedded in CLIP feature space, thereby yielding performance setbacks. To address this gap, we delve deeply into the text-eye collaboration protocol and introduce a novel gaze estimation framework, named GazeCLIP. Specifically, we intricately design a linguistic description generator to produce text signals with coarse directional cues. Additionally, a CLIP-based backbone that excels in characterizing text-eye pairs for gaze estimation is presented. This is followed by the implementation of a fine-grained multi-modal fusion module aimed at modeling the interrelationships between heterogeneous inputs. Extensive experiments on three challenging datasets demonstrate the superiority of the proposed GazeCLIP which achieves the state-of-the-art accuracy.
Read more4/29/2024