GazeCLIP: Towards Enhancing Gaze Estimation via Text Guidance
2401.00260
0
0

Abstract
Over the past decade, visual gaze estimation has garnered increasing attention within the research community, owing to its wide-ranging application scenarios. While existing estimation approaches have achieved remarkable success in enhancing prediction accuracy, they primarily infer gaze from single-image signals, neglecting the potential benefits of the currently dominant text guidance. Notably, visual-language collaboration has been extensively explored across various visual tasks, such as image synthesis and manipulation, leveraging the remarkable transferability of large-scale Contrastive Language-Image Pre-training (CLIP) model. Nevertheless, existing gaze estimation approaches overlook the rich semantic cues conveyed by linguistic signals and the priors embedded in CLIP feature space, thereby yielding performance setbacks. To address this gap, we delve deeply into the text-eye collaboration protocol and introduce a novel gaze estimation framework, named GazeCLIP. Specifically, we intricately design a linguistic description generator to produce text signals with coarse directional cues. Additionally, a CLIP-based backbone that excels in characterizing text-eye pairs for gaze estimation is presented. This is followed by the implementation of a fine-grained multi-modal fusion module aimed at modeling the interrelationships between heterogeneous inputs. Extensive experiments on three challenging datasets demonstrate the superiority of the proposed GazeCLIP which achieves the state-of-the-art accuracy.
Create account to get full access
Overview
- This paper introduces GazeCLIP, a novel approach to enhancing gaze estimation performance by leveraging text-based guidance.
- The researchers explore how incorporating language information can improve the accuracy and robustness of gaze estimation models.
- GazeCLIP integrates the strengths of language models like CLIP with traditional gaze estimation techniques.
Plain English Explanation
The paper discusses a new method called GazeCLIP that aims to improve the accuracy of gaze tracking systems. Gaze tracking is the process of detecting where a person's eyes are looking on a screen or in the real world. This information has many applications, like controlling computers with your eyes or understanding how people interact with visual content.
Traditional gaze tracking models rely solely on visual information from cameras. GazeCLIP tries to enhance these models by also incorporating language data. The researchers hypothesize that adding language cues, like descriptions of what is being viewed, can help the gaze estimation system perform better.
GazeCLIP builds on top of powerful language models like CLIP, which can understand the meaning of text and how it relates to images. The idea is to use this language understanding to guide and refine the gaze tracking process, leading to more accurate results.
Technical Explanation
The paper presents the GazeCLIP framework, which combines gaze estimation with language-based guidance. The key technical components include:
- Gaze Estimation Module: This is a standard deep learning model for predicting gaze direction from eye images.
- Language Module: This is a CLIP-style language model that can understand the semantic meaning of text descriptions.
- Cross-Modal Interaction: GazeCLIP aligns the gaze estimation and language modules, allowing the language understanding to provide feedback and refinement to the gaze prediction.
The researchers evaluate GazeCLIP on several gaze estimation benchmarks, including MPIIGaze and RIO. Their results demonstrate that the text-guided approach can outperform traditional gaze estimation methods, particularly in challenging real-world scenarios.
Critical Analysis
The paper presents a compelling approach to enhancing gaze estimation by leveraging language understanding. However, a few potential limitations are worth considering:
- Dataset Dependency: The performance of GazeCLIP may be dependent on the quality and coverage of the text descriptions used during training. Inadequate or biased language data could limit the model's generalization.
- Computational Efficiency: Integrating a large language model like CLIP may increase the computational requirements of the gaze estimation system, which could be a concern for real-time applications or deployments on resource-constrained devices.
- Robustness to Noise: The paper does not extensively explore the model's resilience to noisy or partial language inputs, which could be important for real-world use cases where text descriptions may be incomplete or inaccurate.
Further research could investigate ways to address these potential limitations, such as developing more efficient cross-modal fusion techniques or exploring self-supervised language learning approaches to reduce dataset dependency.
Conclusion
The GazeCLIP paper presents a novel and promising direction for enhancing gaze estimation by integrating language-based guidance. By leveraging the semantic understanding of text descriptions, the researchers demonstrate improved gaze prediction accuracy, particularly in challenging real-world scenarios.
This work highlights the potential benefits of combining computer vision and natural language processing techniques to tackle complex perception problems. As gaze estimation continues to find applications in areas like human-computer interaction, assisted technology, and behavioral analysis, approaches like GazeCLIP could lead to more robust and reliable gaze tracking systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
0
0
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
5/14/2024
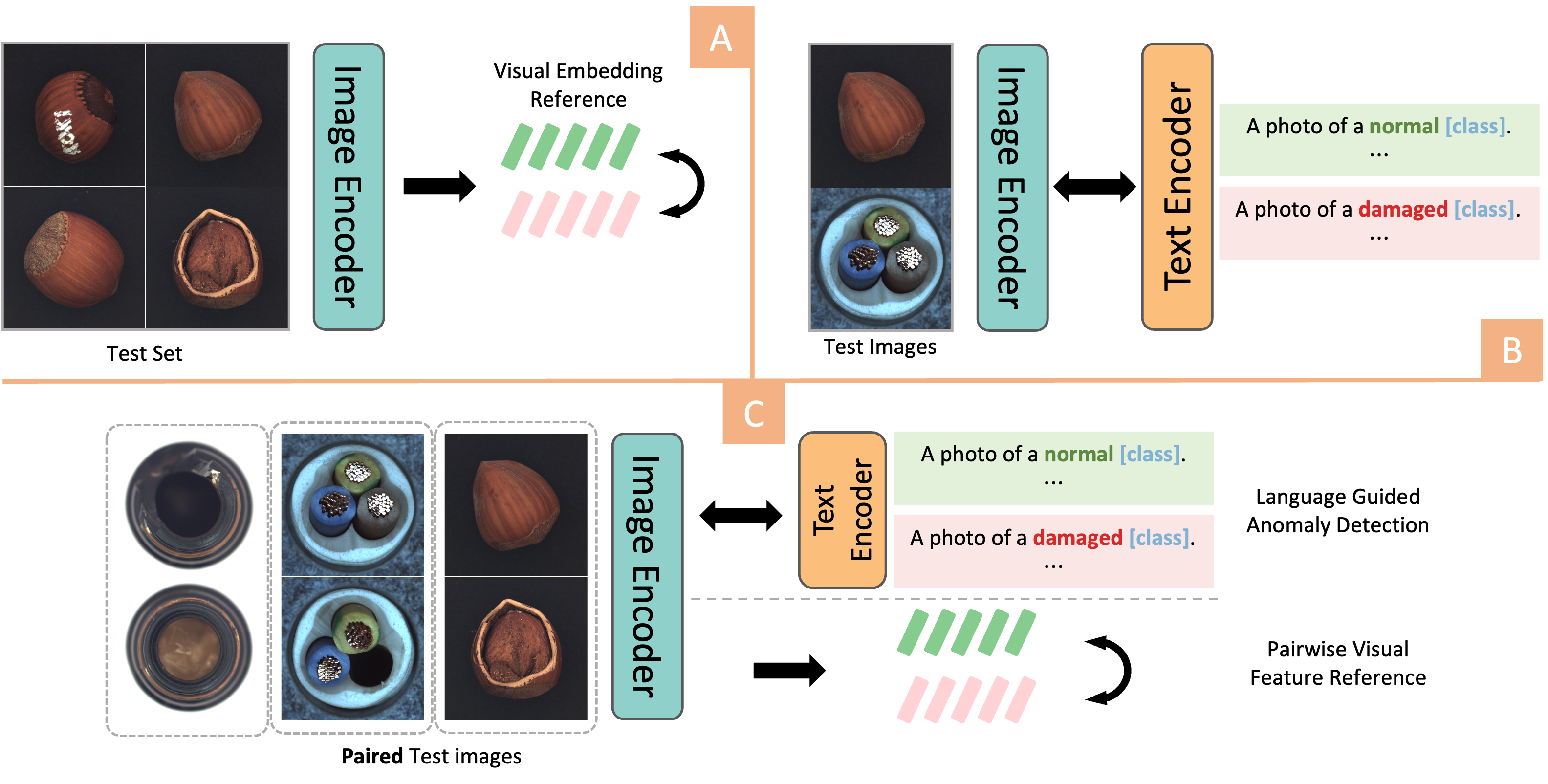
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
0
0
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
5/9/2024
👀
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
0
0
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
6/3/2024
⚙️
CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts
Yichao Cai, Yuhang Liu, Zhen Zhang, Javen Qinfeng Shi
0
0
Contrastive vision-language models, such as CLIP, have garnered considerable attention for various dowmsteam tasks, mainly due to the remarkable ability of the learned features for generalization. However, the features they learned often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begins with exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like model's encoders to concentrate on latent content information, refining the learned representations by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state-of-the-art in multimodal learning.
4/30/2024