How Susceptible are LLMs to Influence in Prompts?

0

Sign in to get full access
Overview
- The paper examines how susceptible large language models (LLMs) are to influence from the prompts they receive.
- It explores the potential for LLMs to be biased or manipulated by the way prompts are phrased or structured.
- The research aims to provide insights into the robustness and reliability of LLMs in real-world applications.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. However, there is a concern that these models may be susceptible to being influenced or biased by the prompts they are given. The Introduction section of the paper explores this issue, noting that the way a prompt is phrased could potentially sway the output of an LLM in unintended ways.
The Methodology section describes an experiment designed to test the susceptibility of LLMs to prompt influence. The researchers looked at how different formulations of the same prompt affected the output of the models. By understanding the extent to which LLMs can be influenced by prompts, the researchers hope to shed light on the reliability and robustness of these AI systems in real-world applications.
Technical Explanation
The Methodology section outlines the experiment conducted by the researchers. They examined the influence of prompts on the outputs of several prominent LLMs. The researchers systematically varied the phrasing and structure of prompts to observe any changes in the generated text.
The results of this experiment provide insights into the potential vulnerabilities of LLMs to prompt-based manipulation. The findings may have important implications for the development and deployment of these AI systems, particularly in applications where reliability and trustworthiness are critical.
Critical Analysis
The paper acknowledges some potential limitations of the research, such as the specific LLMs and prompts used in the experiments. The authors note that further research would be needed to fully understand the generalizability of the findings.
Additionally, the paper does not delve deeply into the potential societal or ethical implications of LLMs being susceptible to prompt-based influence. This is an area that could warrant further exploration and discussion.
Conclusion
This research provides valuable insights into the susceptibility of LLMs to prompt influence. By understanding the extent to which these AI systems can be biased or manipulated by the way prompts are formulated, the findings can inform the development of more robust and reliable LLMs for real-world applications. The implications of this research extend beyond technical considerations, as the potential for prompt-based influence raises important questions about the responsible development and deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Susceptible are LLMs to Influence in Prompts?
Sotiris Anagnostidis, Jannis Bulian
Large Language Models (LLMs) are highly sensitive to prompts, including additional context provided therein. As LLMs grow in capability, understanding their prompt-sensitivity becomes increasingly crucial for ensuring reliable and robust performance, particularly since evaluating these models becomes more challenging. In this work, we investigate how current models (Llama, Mixtral, Falcon) respond when presented with additional input from another model, mimicking a scenario where a more capable model -- or a system with access to more external information -- provides supplementary information to the target model. Across a diverse spectrum of question-answering tasks, we study how an LLM's response to multiple-choice questions changes when the prompt includes a prediction and explanation from another model. Specifically, we explore the influence of the presence of an explanation, the stated authoritativeness of the source, and the stated confidence of the supplementary input. Our findings reveal that models are strongly influenced, and when explanations are provided they are swayed irrespective of the quality of the explanation. The models are more likely to be swayed if the input is presented as being authoritative or confident, but the effect is small in size. This study underscores the significant prompt-sensitivity of LLMs and highlights the potential risks of incorporating outputs from external sources without thorough scrutiny and further validation. As LLMs continue to advance, understanding and mitigating such sensitivities will be crucial for their reliable and trustworthy deployment.
Read more8/23/2024

0
Understanding the Relationship between Prompts and Response Uncertainty in Large Language Models
Ze Yu Zhang, Arun Verma, Finale Doshi-Velez, Bryan Kian Hsiang Low
Large language models (LLMs) are widely used in decision-making, but their reliability, especially in critical tasks like healthcare, is not well-established. Therefore, understanding how LLMs reason and make decisions is crucial for their safe deployment. This paper investigates how the uncertainty of responses generated by LLMs relates to the information provided in the input prompt. Leveraging the insight that LLMs learn to infer latent concepts during pretraining, we propose a prompt-response concept model that explains how LLMs generate responses and helps understand the relationship between prompts and response uncertainty. We show that the uncertainty decreases as the prompt's informativeness increases, similar to epistemic uncertainty. Our detailed experimental results on real datasets validate our proposed model.
Read more8/23/2024
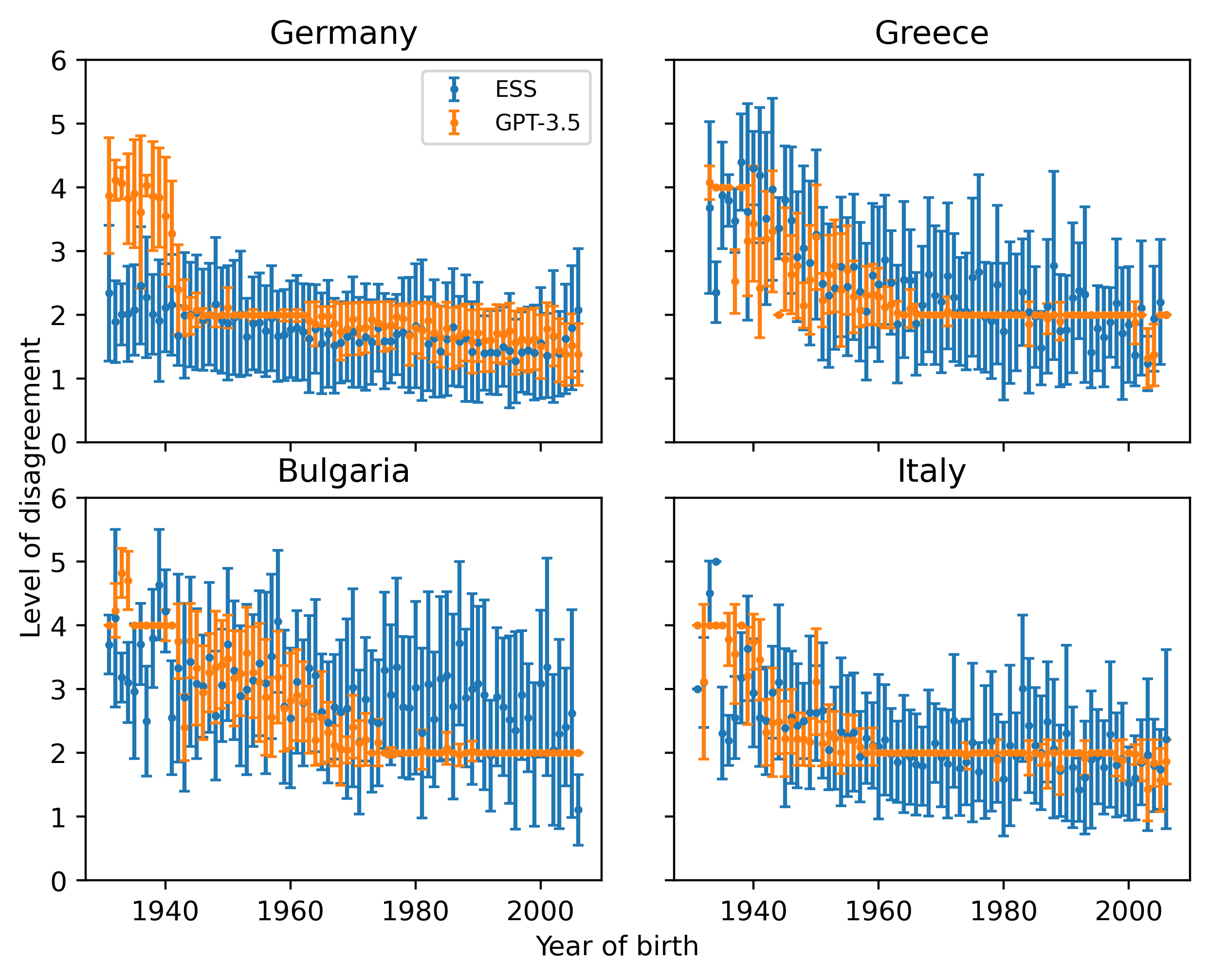
0
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
Read more5/30/2024
💬
0
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
Read more5/21/2024