Understanding the Relationship between Prompts and Response Uncertainty in Large Language Models

0

Sign in to get full access
Overview
- Examines the relationship between prompts and response uncertainty in large language models
- Proposes a conceptual model to understand this relationship
- Explores how prompt design can influence the reliability and trustworthiness of language model outputs
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text, but their outputs can also be uncertain or unreliable. This paper looks at the connection between the prompts (the initial instructions or queries) given to these models and the level of uncertainty in their responses.
The researchers developed a conceptual model to help understand this relationship. They propose that the prompt provided to an LLM interacts with the model's internal representations (its complex understanding of language) to produce a response that may have varying degrees of uncertainty.
By carefully designing prompts, the researchers found that it's possible to influence the reliability and trustworthiness of the model's outputs. Prompts that are more specific and well-defined tend to result in responses with lower uncertainty, while more open-ended or ambiguous prompts can lead to greater uncertainty.
This research has important implications for how we use and interpret the outputs of powerful language models in real-world applications, where it's critical to understand their limitations and reliability.
Technical Explanation
The paper proposes a Prompt-Response Concept Model to describe the relationship between prompts and response uncertainty in LLMs. The model suggests that a prompt interacts with the model's internal representations (its complex understanding of language and the world) to produce a response, which may have varying degrees of uncertainty.
The researchers conducted experiments using the GPT-3 language model to test this conceptual model. They found that prompts with different levels of specificity and ambiguity had a significant impact on the uncertainty of the model's outputs, as measured by metrics like perplexity and self-reported uncertainty.
Prompts that were more specific and well-defined tended to result in responses with lower uncertainty, while more open-ended or ambiguous prompts led to greater uncertainty. The researchers also found that the complexity of the prompt (e.g., the number of instructions or the level of detail) could influence response uncertainty.
Critical Analysis
The paper provides a useful conceptual framework for understanding the relationship between prompts and response uncertainty in LLMs, but it also acknowledges several limitations and areas for further research.
One key limitation is that the experiments were conducted using only the GPT-3 model, so the findings may not generalize to other LLMs with different architectures or training approaches. The researchers suggest that investigating a broader range of models would be an important next step.
Additionally, the paper focuses on uncertainty as the primary metric for evaluating response reliability, but there may be other important factors to consider, such as the model's tendency to express uncertainty or its ability to acknowledge the limitations of its own knowledge.
Further research could also explore how factors like the context of the prompt, the domain of the task, and the user's expectations might influence the relationship between prompts and response uncertainty.
Conclusion
This paper provides a valuable conceptual model and empirical insights into the complex relationship between prompts and response uncertainty in large language models. By understanding how prompt design can influence the reliability and trustworthiness of LLM outputs, researchers and practitioners can develop more effective and responsible ways of using these powerful AI systems in real-world applications.
The findings from this study highlight the importance of carefully considering prompt design and the potential limitations of language models when relying on their outputs for decision-making or other critical tasks. Continued research in this area will be crucial as LLMs become increasingly integrated into our daily lives and decision-making processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding the Relationship between Prompts and Response Uncertainty in Large Language Models
Ze Yu Zhang, Arun Verma, Finale Doshi-Velez, Bryan Kian Hsiang Low
Large language models (LLMs) are widely used in decision-making, but their reliability, especially in critical tasks like healthcare, is not well-established. Therefore, understanding how LLMs reason and make decisions is crucial for their safe deployment. This paper investigates how the uncertainty of responses generated by LLMs relates to the information provided in the input prompt. Leveraging the insight that LLMs learn to infer latent concepts during pretraining, we propose a prompt-response concept model that explains how LLMs generate responses and helps understand the relationship between prompts and response uncertainty. We show that the uncertainty decreases as the prompt's informativeness increases, similar to epistemic uncertainty. Our detailed experimental results on real datasets validate our proposed model.
Read more8/23/2024

0
How Susceptible are LLMs to Influence in Prompts?
Sotiris Anagnostidis, Jannis Bulian
Large Language Models (LLMs) are highly sensitive to prompts, including additional context provided therein. As LLMs grow in capability, understanding their prompt-sensitivity becomes increasingly crucial for ensuring reliable and robust performance, particularly since evaluating these models becomes more challenging. In this work, we investigate how current models (Llama, Mixtral, Falcon) respond when presented with additional input from another model, mimicking a scenario where a more capable model -- or a system with access to more external information -- provides supplementary information to the target model. Across a diverse spectrum of question-answering tasks, we study how an LLM's response to multiple-choice questions changes when the prompt includes a prediction and explanation from another model. Specifically, we explore the influence of the presence of an explanation, the stated authoritativeness of the source, and the stated confidence of the supplementary input. Our findings reveal that models are strongly influenced, and when explanations are provided they are swayed irrespective of the quality of the explanation. The models are more likely to be swayed if the input is presented as being authoritative or confident, but the effect is small in size. This study underscores the significant prompt-sensitivity of LLMs and highlights the potential risks of incorporating outputs from external sources without thorough scrutiny and further validation. As LLMs continue to advance, understanding and mitigating such sensitivities will be crucial for their reliable and trustworthy deployment.
Read more8/23/2024
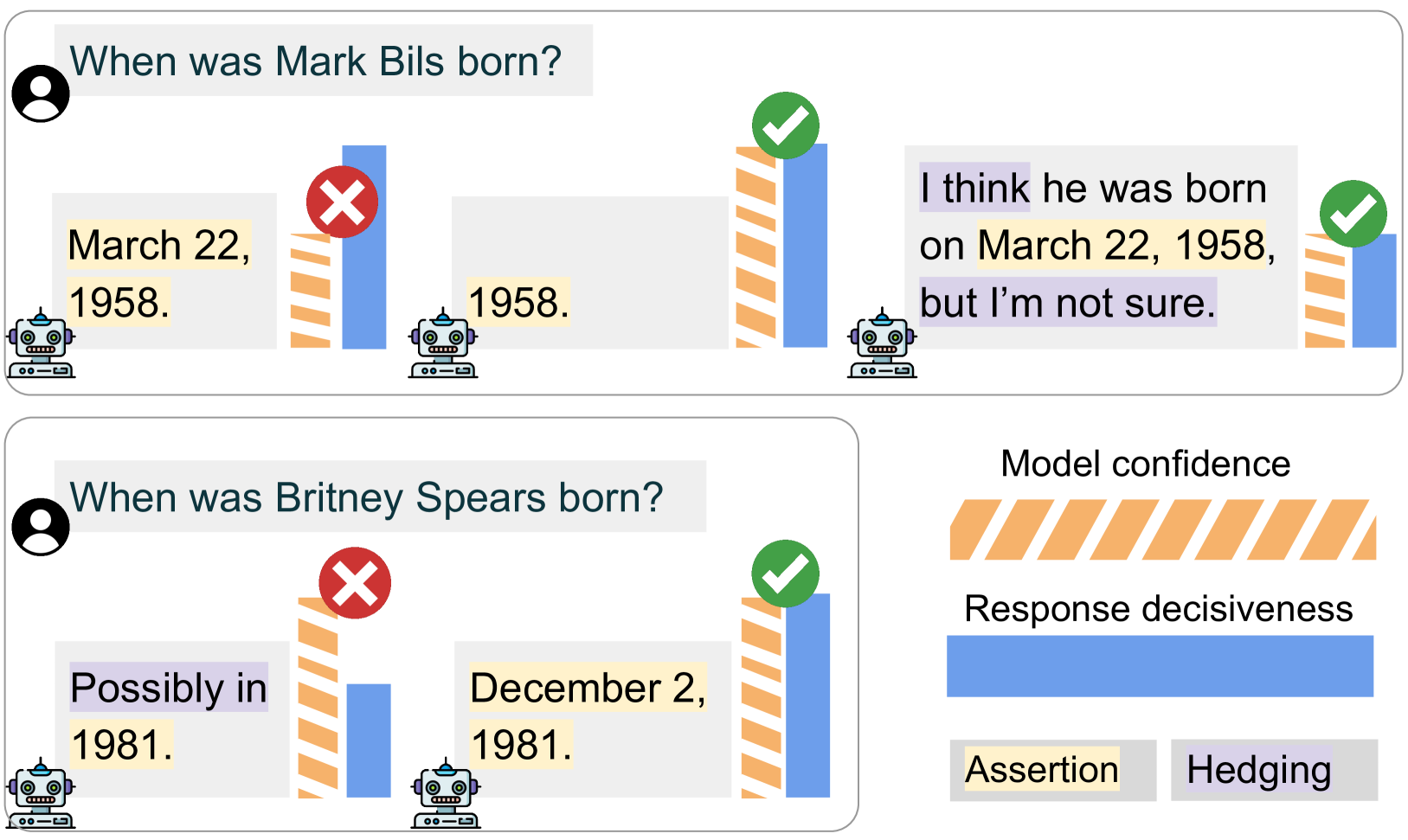
0
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Read more5/28/2024

0
Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, Maarten Sap
As natural language becomes the default interface for human-AI interaction, there is a need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence in responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are reluctant to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (an average of 47%) among confident responses. We test the risks of LM overconfidence by conducting human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in post training alignment and find that humans are biased against texts with uncertainty. Our work highlights new safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
Read more7/11/2024