How to Choose a Reinforcement-Learning Algorithm

0
🔍
Sign in to get full access
Overview
- Provides a guide for choosing the appropriate reinforcement learning (RL) algorithm for a given problem.
- Covers key considerations in selecting an RL algorithm, including the problem characteristics, performance requirements, and computational constraints.
- Offers a structured approach to evaluate and compare different RL algorithms to find the best fit.
Plain English Explanation
Reinforcement learning is a powerful technique for training AI systems to make decisions and take actions in complex environments. However, with the wide variety of RL algorithms available, it can be challenging to determine which one is most suitable for a particular problem.
This guide aims to help researchers and practitioners navigate the process of choosing the right RL algorithm. It outlines the key factors to consider, such as the type of problem (e.g., continuous or discrete actions, stochastic or deterministic environment), the desired performance characteristics (e.g., sample efficiency, scalability, interpretability), and the available computational resources.
By systematically evaluating these factors, the guide provides a structured approach to assess and compare different RL algorithms. This can help users identify the algorithm that best fits their specific requirements and constraints, leading to more effective and efficient RL-based solutions.
The guide also emphasizes the importance of understanding the strengths and limitations of different RL algorithms, as well as the potential trade-offs involved in selecting one over another. This knowledge can help users make informed decisions and avoid common pitfalls when applying RL to real-world problems.
Technical Explanation
The paper presents a comprehensive framework for choosing the appropriate reinforcement learning (RL) algorithm for a given problem. It begins by outlining the key characteristics of RL problems, such as the nature of the state and action spaces (e.g., continuous or discrete), the dynamics of the environment (e.g., stochastic or deterministic), and the reward structure.
The authors then introduce a set of performance criteria that are critical in selecting an RL algorithm, including sample efficiency, scalability, interpretability, and robustness. They provide a detailed discussion of how these criteria can impact the choice of algorithm and the tradeoffs that may need to be considered.
Next, the paper delves into the different families of RL algorithms, including value-based methods (e.g., Q-learning, DQN), policy-based methods (e.g., REINFORCE, PPO), and actor-critic methods (e.g., A3C, DDPG). The authors analyze the strengths and weaknesses of each algorithm type, highlighting their suitability for different problem domains and performance requirements.
The core of the paper presents a structured decision-making process for evaluating and comparing RL algorithms. This process involves defining the problem requirements, mapping them to the key algorithm characteristics, and then systematically assessing the performance of candidate algorithms on relevant metrics.
The authors demonstrate the application of this framework through a case study involving a continuous control task. They showcase how the framework can guide the selection of an appropriate RL algorithm, considering factors such as the continuous action space, the stochastic environment dynamics, and the need for sample efficiency and scalability.
Critical Analysis
The paper provides a valuable and much-needed guide for practitioners and researchers in the field of reinforcement learning. By systematically addressing the key factors to consider when choosing an RL algorithm, the authors offer a structured approach that can help users navigate the complex landscape of RL algorithms and make informed decisions.
One of the strengths of the paper is its comprehensive coverage of RL algorithm characteristics and performance criteria. The authors have done an excellent job of identifying the relevant factors and providing clear explanations of their implications. This can be particularly helpful for novice RL practitioners who may be overwhelmed by the vast array of available algorithms.
However, the paper could be further strengthened by including more detailed discussions on the potential limitations and caveats of the proposed framework. For example, the authors could explore how the framework might need to be adjusted for specific problem domains or how it might handle situations where multiple RL algorithms perform similarly on the evaluated criteria.
Additionally, the case study provided in the paper, while informative, could be expanded to include a broader range of problem types and RL algorithms. This would help demonstrate the versatility and generalizability of the proposed framework.
Conclusion
This paper offers a valuable guide for researchers and practitioners in the field of reinforcement learning. By providing a structured approach to evaluating and comparing RL algorithms, it empowers users to make informed decisions that better align with their specific problem requirements and constraints.
The comprehensive coverage of RL algorithm characteristics and performance criteria, coupled with the structured decision-making process, makes this paper a valuable resource for anyone seeking to apply RL techniques effectively. The insights and recommendations presented can help users navigate the complex RL landscape and develop more efficient and robust RL-based solutions.
While the paper could be further strengthened by addressing some potential limitations and expanding the case studies, it stands as a significant contribution to the RL community, offering a practical and well-thought-out framework for choosing the most appropriate RL algorithm for a given problem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
How to Choose a Reinforcement-Learning Algorithm
Fabian Bongratz, Vladimir Golkov, Lukas Mautner, Luca Della Libera, Frederik Heetmeyer, Felix Czaja, Julian Rodemann, Daniel Cremers
The field of reinforcement learning offers a large variety of concepts and methods to tackle sequential decision-making problems. This variety has become so large that choosing an algorithm for a task at hand can be challenging. In this work, we streamline the process of choosing reinforcement-learning algorithms and action-distribution families. We provide a structured overview of existing methods and their properties, as well as guidelines for when to choose which methods. An interactive version of these guidelines is available online at https://rl-picker.github.io/.
Read more7/31/2024
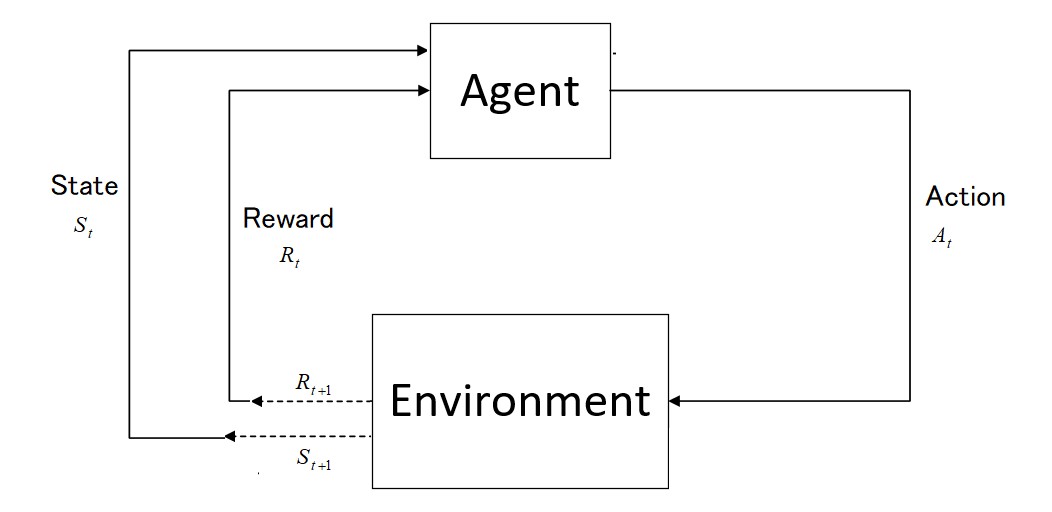
0
An Introduction to Reinforcement Learning: Fundamental Concepts and Practical Applications
Majid Ghasemi, Amir Hossein Moosavi, Ibrahim Sorkhoh, Anjali Agrawal, Fadi Alzhouri, Dariush Ebrahimi
Reinforcement Learning (RL) is a branch of Artificial Intelligence (AI) which focuses on training agents to make decisions by interacting with their environment to maximize cumulative rewards. An overview of RL is provided in this paper, which discusses its core concepts, methodologies, recent trends, and resources for learning. We provide a detailed explanation of key components of RL such as states, actions, policies, and reward signals so that the reader can build a foundational understanding. The paper also provides examples of various RL algorithms, including model-free and model-based methods. In addition, RL algorithms are introduced and resources for learning and implementing them are provided, such as books, courses, and online communities. This paper demystifies a comprehensive yet simple introduction for beginners by offering a structured and clear pathway for acquiring and implementing real-time techniques.
Read more8/16/2024
🏅
0
A Review of Safe Reinforcement Learning: Methods, Theory and Applications
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Alois Knoll
Reinforcement Learning (RL) has achieved tremendous success in many complex decision-making tasks. However, safety concerns are raised during deploying RL in real-world applications, leading to a growing demand for safe RL algorithms, such as in autonomous driving and robotics scenarios. While safe control has a long history, the study of safe RL algorithms is still in the early stages. To establish a good foundation for future safe RL research, in this paper, we provide a review of safe RL from the perspectives of methods, theories, and applications. Firstly, we review the progress of safe RL from five dimensions and come up with five crucial problems for safe RL being deployed in real-world applications, coined as 2H3W. Secondly, we analyze the algorithm and theory progress from the perspectives of answering the 2H3W problems. Particularly, the sample complexity of safe RL algorithms is reviewed and discussed, followed by an introduction to the applications and benchmarks of safe RL algorithms. Finally, we open the discussion of the challenging problems in safe RL, hoping to inspire future research on this thread. To advance the study of safe RL algorithms, we release an open-sourced repository containing the implementations of major safe RL algorithms at the link: https://github.com/chauncygu/Safe-Reinforcement-Learning-Baselines.git.
Read more5/28/2024
0
A Pontryagin Perspective on Reinforcement Learning
Onno Eberhard, Claire Vernade, Michael Muehlebach
Reinforcement learning has traditionally focused on learning state-dependent policies to solve optimal control problems in a closed-loop fashion. In this work, we introduce the paradigm of open-loop reinforcement learning where a fixed action sequence is learned instead. We present three new algorithms: one robust model-based method and two sample-efficient model-free methods. Rather than basing our algorithms on Bellman's equation from dynamic programming, our work builds on Pontryagin's principle from the theory of open-loop optimal control. We provide convergence guarantees and evaluate all methods empirically on a pendulum swing-up task, as well as on two high-dimensional MuJoCo tasks, demonstrating remarkable performance compared to existing baselines.
Read more5/29/2024