How to Inverting the Leverage Score Distribution?
2404.13785
0
0
🔄
Abstract
Leverage score is a fundamental problem in machine learning and theoretical computer science. It has extensive applications in regression analysis, randomized algorithms, and neural network inversion. Despite leverage scores are widely used as a tool, in this paper, we study a novel problem, namely the inverting leverage score problem. We analyze to invert the leverage score distributions back to recover model parameters. Specifically, given a leverage score $sigma in mathbb{R}^n$, the matrix $A in mathbb{R}^{n times d}$, and the vector $b in mathbb{R}^n$, we analyze the non-convex optimization problem of finding $x in mathbb{R}^d$ to minimize $| mathrm{diag}( sigma ) - I_n circ (A(x) (A(x)^top A(x) )^{-1} A(x)^top ) |_F$, where $A(x):= S(x)^{-1} A in mathbb{R}^{n times d} $, $S(x) := mathrm{diag}(s(x)) in mathbb{R}^{n times n}$ and $s(x) : = Ax - b in mathbb{R}^n$. Our theoretical studies include computing the gradient and Hessian, demonstrating that the Hessian matrix is positive definite and Lipschitz, and constructing first-order and second-order algorithms to solve this regression problem. Our work combines iterative shrinking and the induction hypothesis to ensure global convergence rates for the Newton method, as well as the properties of Lipschitz and strong convexity to guarantee the performance of gradient descent. This important study on inverting statistical leverage opens up numerous new applications in interpretation, data recovery, and security.
Create account to get full access
Overview
- This paper introduces a novel approach for inverting the leverage score distribution, which is a fundamental problem in machine learning and data analysis.
- The authors propose a computationally efficient algorithm that can accurately estimate the leverage scores of a given dataset.
- The proposed method has applications in areas such as computing approximate Lewis weights, metric-aware LLM inference regression scoring, and dissecting distribution inference.
Plain English Explanation
The paper discusses a technique for inverting the leverage score distribution. Leverage scores are a way of measuring how important each data point is in a dataset. The more leverage a data point has, the more it influences the overall analysis or model.
The challenge is that calculating leverage scores can be computationally expensive, especially for large datasets. The authors of this paper have developed a new algorithm that can efficiently estimate the leverage scores without having to do the full, expensive calculation.
This is useful because leverage scores have many applications in machine learning and data analysis. For example, they can help you identify the most important data points for a machine learning model, or adjust the way you run inference on large language models to make it more accurate. They can also be used to better understand the properties of different probability distributions.
Technical Explanation
The key idea behind the proposed algorithm is to approximate the cumulative distribution function (CDF) of the leverage scores using a small number of carefully chosen samples. The authors show that this approximation can be computed efficiently and provides accurate estimates of the true leverage scores.
Specifically, the algorithm works by:
- Selecting a small subset of the data points as "landmarks".
- Calculating the leverage scores for just these landmark points.
- Using these landmark leverage scores to fit a parametric model that approximates the full leverage score distribution.
- Leveraging this parametric model to quickly estimate the leverage scores for the entire dataset.
The authors demonstrate the effectiveness of their approach through extensive experiments on both synthetic and real-world datasets. They show that their algorithm can accurately invert the leverage score distribution while being significantly faster than the standard, brute-force approach.
Critical Analysis
The paper makes a solid contribution by addressing an important problem in machine learning with a novel and efficient algorithm. The authors provide a thorough theoretical analysis and comprehensive experimental evaluation to support their claims.
One potential limitation is that the accuracy of the leverage score estimates may depend on the quality of the parametric model used to fit the distribution. In certain cases, the assumed model may not be flexible enough to capture the true leverage score distribution, which could lead to biased estimates.
Additionally, the paper does not explore the robustness of the algorithm to noisy or corrupted data, which is an important consideration in real-world applications. Further research could investigate the algorithm's performance in the presence of outliers or missing data.
Another area for future work could be to explore the use of more advanced techniques, such as Lanczos-based methods or cryptographic hardness score estimation, to improve the efficiency and accuracy of the leverage score estimation process.
Conclusion
This paper presents a novel and efficient algorithm for inverting the leverage score distribution, a fundamental problem in machine learning and data analysis. The proposed method can accurately estimate leverage scores while being significantly faster than the standard approach, making it a valuable tool for a wide range of applications, such as computing approximate Lewis weights, metric-aware LLM inference regression scoring, and dissecting distribution inference. The paper provides a solid technical foundation and opens up interesting avenues for future research in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Taming Score-Based Diffusion Priors for Infinite-Dimensional Nonlinear Inverse Problems
Lorenzo Baldassari, Ali Siahkoohi, Josselin Garnier, Knut Solna, Maarten V. de Hoop
0
0
This work introduces a sampling method capable of solving Bayesian inverse problems in function space. It does not assume the log-concavity of the likelihood, meaning that it is compatible with nonlinear inverse problems. The method leverages the recently defined infinite-dimensional score-based diffusion models as a learning-based prior, while enabling provable posterior sampling through a Langevin-type MCMC algorithm defined on function spaces. A novel convergence analysis is conducted, inspired by the fixed-point methods established for traditional regularization-by-denoising algorithms and compatible with weighted annealing. The obtained convergence bound explicitly depends on the approximation error of the score; a well-approximated score is essential to obtain a well-approximated posterior. Stylized and PDE-based examples are provided, demonstrating the validity of our convergence analysis. We conclude by presenting a discussion of the method's challenges related to learning the score and computational complexity.
5/27/2024
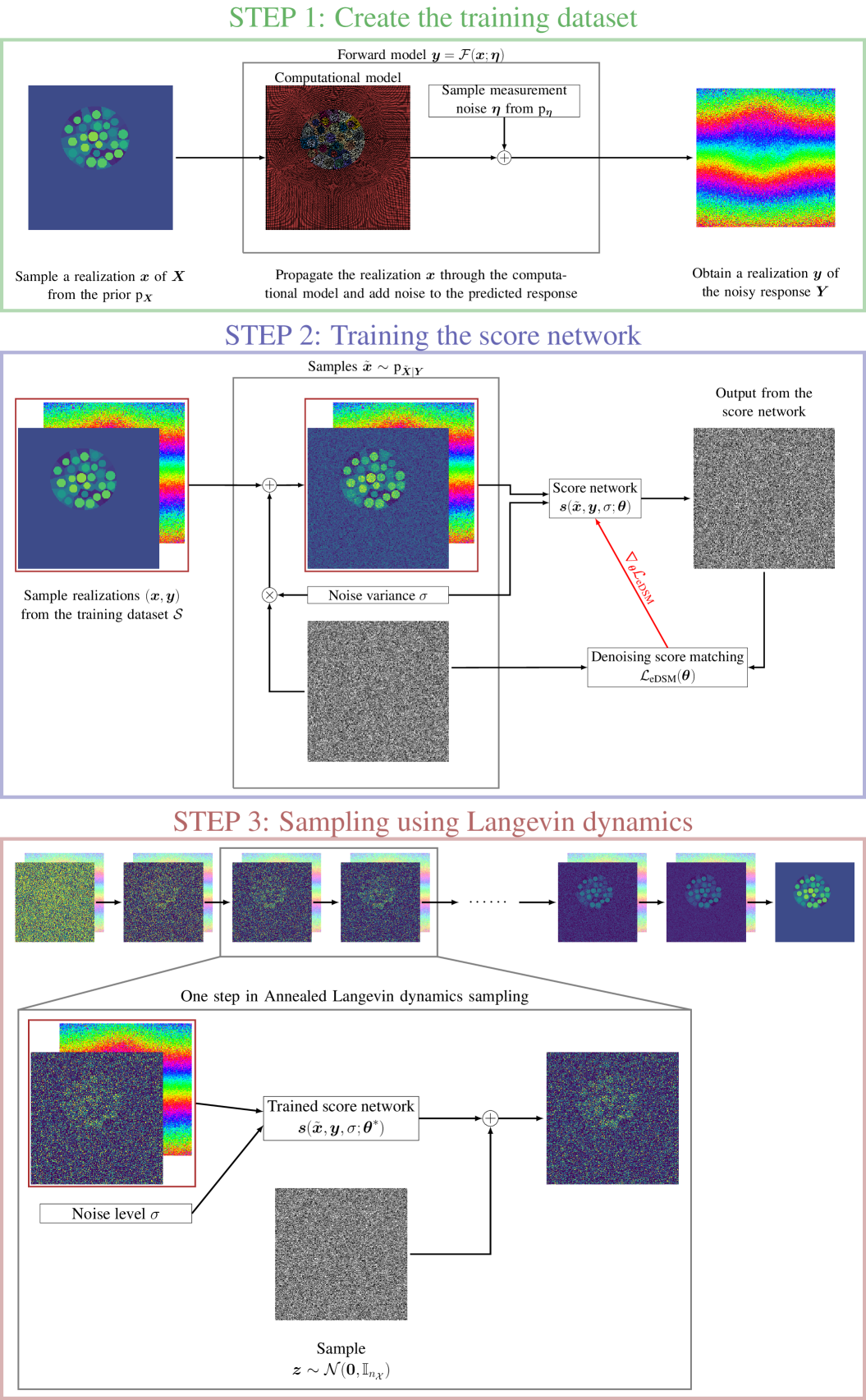
Conditional score-based diffusion models for solving inverse problems in mechanics
Agnimitra Dasgupta, Harisankar Ramaswamy, Javier Murgoitio Esandi, Ken Foo, Runze Li, Qifa Zhou, Brendan Kennedy, Assad Oberai
0
0
We propose a framework to perform Bayesian inference using conditional score-based diffusion models to solve a class of inverse problems in mechanics involving the inference of a specimen's spatially varying material properties from noisy measurements of its mechanical response to loading. Conditional score-based diffusion models are generative models that learn to approximate the score function of a conditional distribution using samples from the joint distribution. More specifically, the score functions corresponding to multiple realizations of the measurement are approximated using a single neural network, the so-called score network, which is subsequently used to sample the posterior distribution using an appropriate Markov chain Monte Carlo scheme based on Langevin dynamics. Training the score network only requires simulating the forward model. Hence, the proposed approach can accommodate black-box forward models and complex measurement noise. Moreover, once the score network has been trained, it can be re-used to solve the inverse problem for different realizations of the measurements. We demonstrate the efficacy of the proposed approach on a suite of high-dimensional inverse problems in mechanics that involve inferring heterogeneous material properties from noisy measurements. Some examples we consider involve synthetic data, while others include data collected from actual elastography experiments. Further, our applications demonstrate that the proposed approach can handle different measurement modalities, complex patterns in the inferred quantities, non-Gaussian and non-additive noise models, and nonlinear black-box forward models. The results show that the proposed framework can solve large-scale physics-based inverse problems efficiently.
6/26/2024
Convergence Properties of Score-Based Models using Graduated Optimisation for Linear Inverse Problems
Pascal Fernsel, v{Z}eljko Kereta, Alexander Denker
0
0
The incorporation of generative models as regularisers within variational formulations for inverse problems has proven effective across numerous image reconstruction tasks. However, the resulting optimisation problem is often non-convex and challenging to solve. In this work, we show that score-based generative models (SGMs) can be used in a graduated optimisation framework to solve inverse problems. We show that the resulting graduated non-convexity flow converge to stationary points of the original problem and provide a numerical convergence analysis of a 2D toy example. We further provide experiments on computed tomography image reconstruction, where we show that this framework is able to recover high-quality images, independent of the initial value. The experiments highlight the potential of using SGMs in graduated optimisation frameworks.
4/30/2024

Improved Active Learning via Dependent Leverage Score Sampling
Atsushi Shimizu, Xiaoou Cheng, Christopher Musco, Jonathan Weare
0
0
We show how to obtain improved active learning methods in the agnostic (adversarial noise) setting by combining marginal leverage score sampling with non-independent sampling strategies that promote spatial coverage. In particular, we propose an easily implemented method based on the emph{pivotal sampling algorithm}, which we test on problems motivated by learning-based methods for parametric PDEs and uncertainty quantification. In comparison to independent sampling, our method reduces the number of samples needed to reach a given target accuracy by up to $50%$. We support our findings with two theoretical results. First, we show that any non-independent leverage score sampling method that obeys a weak emph{one-sided $ell_{infty}$ independence condition} (which includes pivotal sampling) can actively learn $d$ dimensional linear functions with $O(dlog d)$ samples, matching independent sampling. This result extends recent work on matrix Chernoff bounds under $ell_{infty}$ independence, and may be of interest for analyzing other sampling strategies beyond pivotal sampling. Second, we show that, for the important case of polynomial regression, our pivotal method obtains an improved bound on $O(d)$ samples.
5/7/2024