How to Train the Teacher Model for Effective Knowledge Distillation

0

Sign in to get full access
Overview
- Explains how to effectively train a teacher model for knowledge distillation
- Outlines key techniques and principles for enhancing the performance of the teacher model
- Covers related research on improving knowledge distillation through better teacher training
Plain English Explanation
Knowledge distillation is a technique used in machine learning where a <a href="https://aimodels.fyi/papers/arxiv/toward-student-oriented-teacher-network-training-knowledge">smaller, less complex student model</a> learns from a <a href="https://aimodels.fyi/papers/arxiv/good-teachers-explain-explanation-enhanced-knowledge-distillation">larger, more powerful teacher model</a>. The goal is to transfer the knowledge and capabilities of the teacher to the student, allowing the student to perform well even though it has a simpler architecture.
The key to effective knowledge distillation is training the teacher model in the right way. This paper explores techniques for <a href="https://aimodels.fyi/papers/arxiv/improve-knowledge-distillation-via-label-revision-data">improving the training of the teacher model</a> to enhance its ability to transfer knowledge to the student.
Some of the key ideas include:
- Focusing the teacher's training on the areas that are most important for the student to learn
- Designing the teacher's architecture and training process to maximize the useful information it can provide to the student
- <a href="https://aimodels.fyi/papers/arxiv/robust-knowledge-distillation-based-feature-variance-against">Ensuring the teacher model is robust and reliable</a>, so the student can trust the knowledge it is receiving
By applying these principles, the researchers show how to train a highly effective teacher model that can significantly boost the performance of the student model through knowledge distillation.
Technical Explanation
The paper proposes several techniques for enhancing the training of the teacher model in knowledge distillation:
-
Targeted Training: The researchers suggest focusing the teacher's training on the areas that are most relevant and important for the student model to learn. This can involve modifying the loss function or training data to emphasize these crucial aspects.
-
Architectural Design: The paper explores ways to design the teacher model's architecture to maximize the useful information it can provide to the student. This may include adding specialized modules or adapting the model structure.
-
Robust Training: The researchers highlight the need to ensure the teacher model is robust and reliable, so the student can trust the knowledge it receives. Techniques like <a href="https://aimodels.fyi/papers/arxiv/robust-knowledge-distillation-based-feature-variance-against">feature variance regularization</a> are proposed to improve the teacher's stability and generalization.
-
Distillation-Aware Optimization: The training of the teacher model is optimized with the student's performance in mind, rather than just the teacher's own accuracy. This can involve <a href="https://aimodels.fyi/papers/arxiv/improve-knowledge-distillation-via-label-revision-data">label revision</a> or other techniques to align the teacher's outputs with the student's needs.
The paper presents extensive experiments across different datasets and architectures, demonstrating the effectiveness of these techniques in improving the performance of the student model through enhanced knowledge distillation.
Critical Analysis
The paper provides a comprehensive exploration of techniques for training effective teacher models in knowledge distillation. The proposed approaches seem well-grounded in the existing literature and show promising empirical results.
However, one potential limitation is that the paper focuses primarily on improving the teacher model, without much discussion of the student model's architecture or training process. In practice, the success of knowledge distillation may also depend on factors related to the student model, such as its initial capacity, training data, and learning objective.
Additionally, the paper does not address the computational and resource costs associated with the more complex teacher model training process. Depending on the application, these additional training overheads may be a concern that needs to be weighed against the performance gains.
Further research could explore the tradeoffs between teacher model complexity, training effort, and student model performance, as well as investigate ways to optimize the overall knowledge distillation pipeline beyond just the teacher model.
Conclusion
This paper presents a valuable contribution to the field of knowledge distillation by highlighting the importance of effectively training the teacher model. The proposed techniques, such as targeted training, architectural design, and distillation-aware optimization, offer a systematic approach to enhancing the teacher's ability to transfer knowledge to the student model.
By implementing these principles, researchers and practitioners can develop more powerful student models without sacrificing the efficiency and deployment advantages of knowledge distillation. This work can help advance the state of the art in model compression and deployment, with potential applications in a wide range of machine learning domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How to Train the Teacher Model for Effective Knowledge Distillation
Shayan Mohajer Hamidi, Xizhen Deng, Renhao Tan, Linfeng Ye, Ahmed Hussein Salamah
Recently, it was shown that the role of the teacher in knowledge distillation (KD) is to provide the student with an estimate of the true Bayes conditional probability density (BCPD). Notably, the new findings propose that the student's error rate can be upper-bounded by the mean squared error (MSE) between the teacher's output and BCPD. Consequently, to enhance KD efficacy, the teacher should be trained such that its output is close to BCPD in MSE sense. This paper elucidates that training the teacher model with MSE loss equates to minimizing the MSE between its output and BCPD, aligning with its core responsibility of providing the student with a BCPD estimate closely resembling it in MSE terms. In this respect, through a comprehensive set of experiments, we demonstrate that substituting the conventional teacher trained with cross-entropy loss with one trained using MSE loss in state-of-the-art KD methods consistently boosts the student's accuracy, resulting in improvements of up to 2.6%.
Read more7/26/2024
🌐
0
Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
Read more5/10/2024
🌿
0
Good Teachers Explain: Explanation-Enhanced Knowledge Distillation
Amin Parchami-Araghi, Moritz Bohle, Sukrut Rao, Bernt Schiele
Knowledge Distillation (KD) has proven effective for compressing large teacher models into smaller student models. While it is well known that student models can achieve similar accuracies as the teachers, it has also been shown that they nonetheless often do not learn the same function. It is, however, often highly desirable that the student's and teacher's functions share similar properties such as basing the prediction on the same input features, as this ensures that students learn the 'right features' from the teachers. In this work, we explore whether this can be achieved by not only optimizing the classic KD loss but also the similarity of the explanations generated by the teacher and the student. Despite the idea being simple and intuitive, we find that our proposed 'explanation-enhanced' KD (e$^2$KD) (1) consistently provides large gains in terms of accuracy and student-teacher agreement, (2) ensures that the student learns from the teacher to be right for the right reasons and to give similar explanations, and (3) is robust with respect to the model architectures, the amount of training data, and even works with 'approximate', pre-computed explanations.
Read more7/23/2024
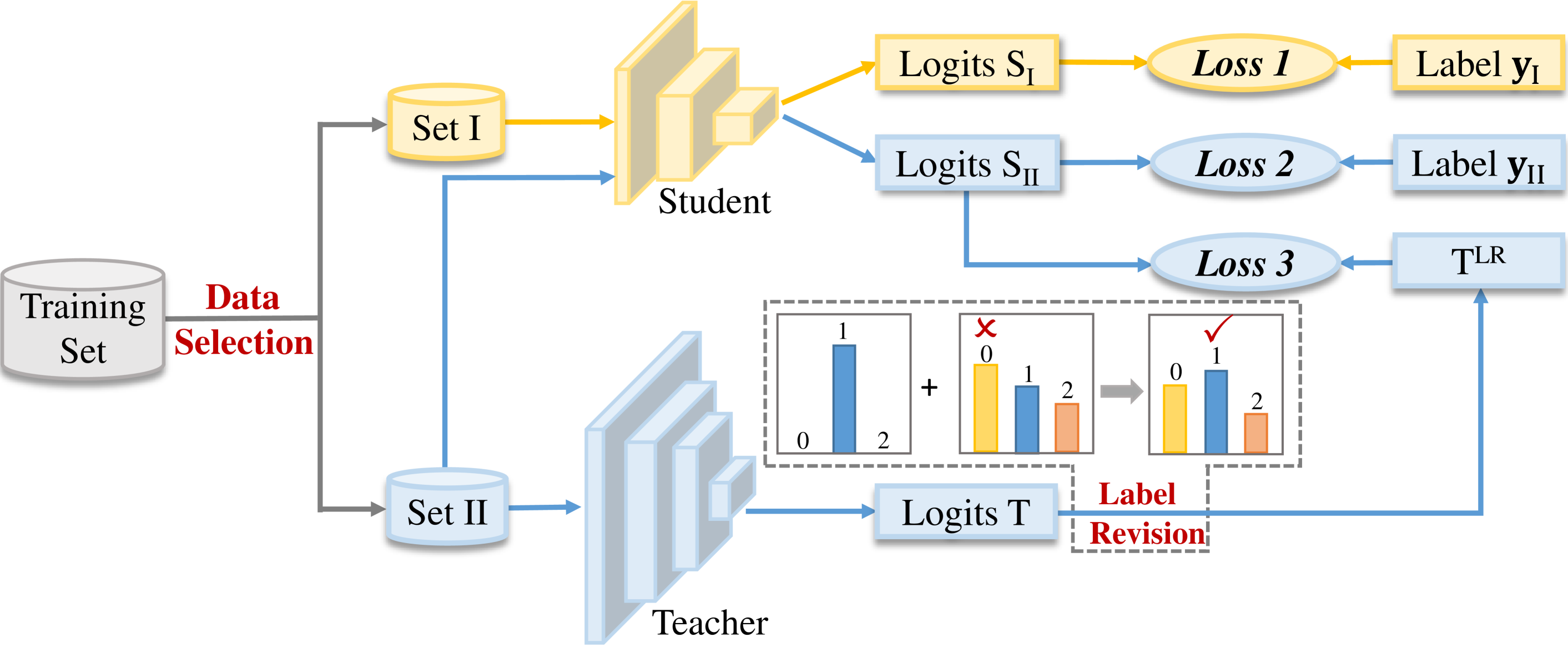
0
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Read more4/8/2024