How Well Do Multi-modal LLMs Interpret CT Scans? An Auto-Evaluation Framework for Analyses

0
Sign in to get full access
Overview
- This paper explores a method for automatically evaluating the performance of large language models (LLMs) like GPT-4 on vision-based tasks.
- The researchers propose a technique to "decompose" the predictions made by these models, breaking them down into interpretable components that can be more easily analyzed and compared.
- The goal is to enable more granular and insightful evaluation of LLM capabilities, particularly in domains like medical imaging where accurate and explainable predictions are crucial.
Plain English Explanation
The researchers in this paper are trying to find a better way to evaluate how well large language models like GPT-4 perform on tasks that involve analyzing images. These models have become very powerful at understanding and generating human language, but they are also starting to be used for tasks that involve vision and images, like identifying objects or medical conditions in medical scans.
The challenge is that it can be difficult to understand exactly how these models are making their predictions on visual tasks. The researchers wanted to develop a method to "break down" the model's predictions into more interpretable parts, so that we can better understand the reasoning behind them. This could be especially important in domains like healthcare, where the accuracy and transparency of the model's decisions are critical.
The key idea is to take the model's output on a visual task and analyze it in more detail. For example, if the model is trying to identify a medical condition in an X-ray image, the researchers want to look at not just the final prediction, but also the intermediate steps the model used to arrive at that conclusion. By understanding these underlying components, we can get a clearer picture of how the model is working and potentially identify areas where it may be making mistakes or biased decisions.
Overall, this research aims to open up the "black box" of these powerful language models when applied to vision-based tasks, making their inner workings more transparent and allowing for more rigorous evaluation and improvement over time. This could have important implications for the use of AI in high-stakes domains like healthcare.
Technical Explanation
The researchers propose a technique called "Decomposing Vision-based LLM Predictions" to enable more granular evaluation of large language models (LLMs) on visual tasks. The core idea is to break down the model's end-to-end predictions into interpretable intermediate components that can be independently analyzed.
Specifically, the researchers take the following steps:
- Image Encoding: The input image is passed through a computer vision model to extract visual features.
- Language Encoding: The visual features are then combined with text prompts and fed into an LLM like GPT-4 to generate textual predictions.
- Prediction Decomposition: The researchers analyze the LLM's internal activations to identify the specific components (e.g., object detection, attribute recognition) that contributed to the final prediction.
By isolating these intermediate steps, the researchers can better understand how the LLM is reasoning about the visual information and where potential issues or biases may be arising.
The authors demonstrate this approach on a medical imaging task, where the LLM is used to generate radiology report text based on input X-ray images. They show how the prediction decomposition can reveal insights about the model's performance, such as its ability to detect specific anatomical structures or recognize certain medical conditions.
This work builds on recent research exploring the use of multimodal LLMs and the evaluation of LLM-based radiology report generation. It also complements efforts to develop clinically-accessible radiology foundation models and evaluate the vision detection capabilities of GPT-4.
Critical Analysis
The researchers present a compelling approach for opening up the "black box" of LLM predictions on visual tasks, which is an important step towards building trust and transparency in these powerful models. By decomposing the predictions into interpretable components, the technique allows for more nuanced evaluation and identification of potential issues or biases.
That said, the paper does not address some key limitations and open questions:
- The evaluation is limited to a single medical imaging task, so it's unclear how well the approach would generalize to other vision-based applications.
- The paper does not explore how the prediction decomposition could be used to actually improve the LLM's performance, beyond just providing insights.
- There are open questions about the reliability and consistency of the prediction decomposition, especially as LLMs become more complex and opaque.
Additionally, this work highlights the broader challenge of developing general-purpose vs. domain-adapted large language models - the tradeoffs between flexibility and specialized performance.
Overall, the researchers have made an important contribution, but there is still considerable work to be done to translate these insights into practical, trustworthy AI systems, especially in high-stakes domains like healthcare.
Conclusion
This paper presents a novel method for decomposing the predictions of large language models on vision-based tasks, with the goal of enabling more granular and insightful evaluation of these powerful AI systems. By breaking down the end-to-end predictions into interpretable intermediate components, the researchers aim to provide greater transparency into the models' reasoning and identify potential issues or biases.
The work has important implications for the development of multimodal AI systems, particularly in domains like medical imaging where accuracy and explainability are critical. By opening up the "black box" of LLM predictions, this research lays the groundwork for more robust and trustworthy AI-powered tools that can be responsibly integrated into real-world applications.
While the current evaluation is limited to a specific medical imaging task, the general principles and techniques introduced in this paper have the potential to be widely applicable. As the field of AI continues to advance, tools like this will be essential for ensuring that these powerful technologies are developed and deployed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Well Do Multi-modal LLMs Interpret CT Scans? An Auto-Evaluation Framework for Analyses
Qingqing Zhu, Benjamin Hou, Tejas S. Mathai, Pritam Mukherjee, Qiao Jin, Xiuying Chen, Zhizheng Wang, Ruida Cheng, Ronald M. Summers, Zhiyong Lu
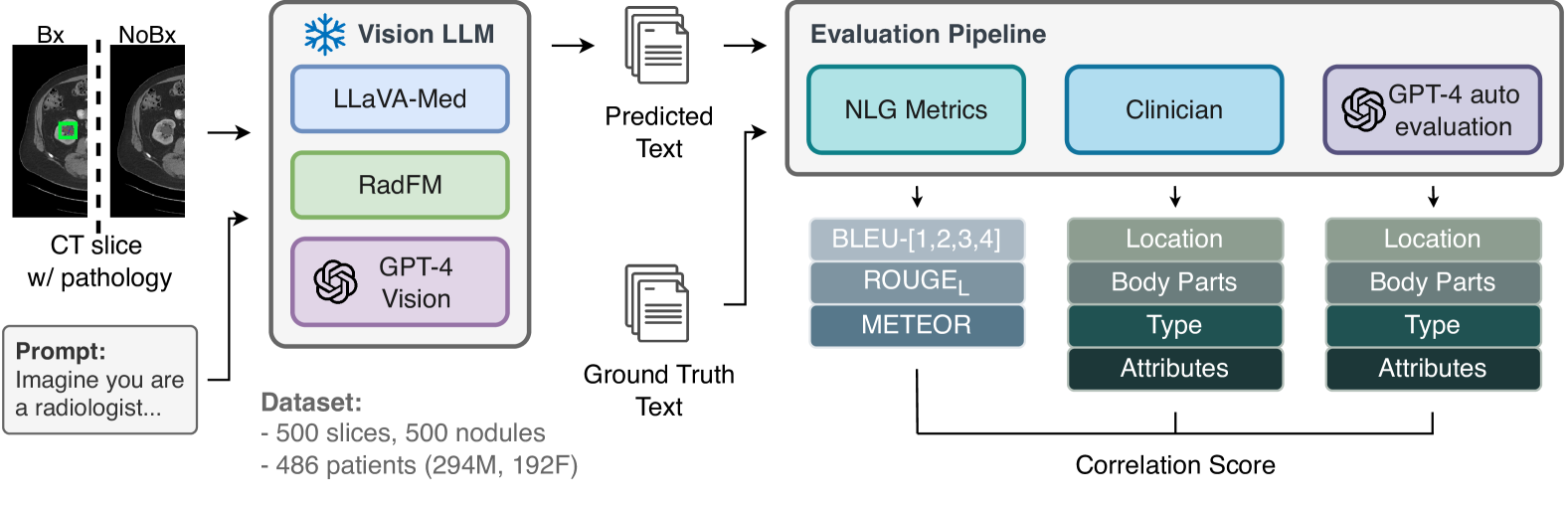
Automatically interpreting CT scans can ease the workload of radiologists. However, this is challenging mainly due to the scarcity of adequate datasets and reference standards for evaluation. This study aims to bridge this gap by introducing a novel evaluation framework, named ``GPTRadScore''. This framework assesses the capabilities of multi-modal LLMs, such as GPT-4 with Vision (GPT-4V), Gemini Pro Vision, LLaVA-Med, and RadFM, in generating descriptions for prospectively-identified findings. By employing a decomposition technique based on GPT-4, GPTRadScore compares these generated descriptions with gold-standard report sentences, analyzing their accuracy in terms of body part, location, and type of finding. Evaluations demonstrated a high correlation with clinician assessments and highlighted its potential over traditional metrics, such as BLEU, METEOR, and ROUGE. Furthermore, to contribute to future studies, we plan to release a benchmark dataset annotated by clinicians. Using GPTRadScore, we found that while GPT-4V and Gemini Pro Vision fare better, their performance revealed significant areas for improvement, primarily due to limitations in the dataset used for training these models. To demonstrate this potential, RadFM was fine-tuned and it resulted in significant accuracy improvements: location accuracy rose from 3.41% to 12.8%, body part accuracy from 29.12% to 53%, and type accuracy from 9.24% to 30%, thereby validating our hypothesis.
Read more6/19/2024
0
Potential of Multimodal Large Language Models for Data Mining of Medical Images and Free-text Reports
Yutong Zhang, Yi Pan, Tianyang Zhong, Peixin Dong, Kangni Xie, Yuxiao Liu, Hanqi Jiang, Zhengliang Liu, Shijie Zhao, Tuo Zhang, Xi Jiang, Dinggang Shen, Tianming Liu, Xin Zhang
Medical images and radiology reports are crucial for diagnosing medical conditions, highlighting the importance of quantitative analysis for clinical decision-making. However, the diversity and cross-source heterogeneity of these data challenge the generalizability of current data-mining methods. Multimodal large language models (MLLMs) have recently transformed many domains, significantly affecting the medical field. Notably, Gemini-Vision-series (Gemini) and GPT-4-series (GPT-4) models have epitomized a paradigm shift in Artificial General Intelligence (AGI) for computer vision, showcasing their potential in the biomedical domain. In this study, we evaluated the performance of the Gemini, GPT-4, and 4 popular large models for an exhaustive evaluation across 14 medical imaging datasets, including 5 medical imaging categories (dermatology, radiology, dentistry, ophthalmology, and endoscopy), and 3 radiology report datasets. The investigated tasks encompass disease classification, lesion segmentation, anatomical localization, disease diagnosis, report generation, and lesion detection. Our experimental results demonstrated that Gemini-series models excelled in report generation and lesion detection but faces challenges in disease classification and anatomical localization. Conversely, GPT-series models exhibited proficiency in lesion segmentation and anatomical localization but encountered difficulties in disease diagnosis and lesion detection. Additionally, both the Gemini series and GPT series contain models that have demonstrated commendable generation efficiency. While both models hold promise in reducing physician workload, alleviating pressure on limited healthcare resources, and fostering collaboration between clinical practitioners and artificial intelligence technologies, substantial enhancements and comprehensive validations remain imperative before clinical deployment.
Read more7/9/2024

0
An Early Investigation into the Utility of Multimodal Large Language Models in Medical Imaging
Sulaiman Khan, Md. Rafiul Biswas, Alina Murad, Hazrat Ali, Zubair Shah
Recent developments in multimodal large language models (MLLMs) have spurred significant interest in their potential applications across various medical imaging domains. On the one hand, there is a temptation to use these generative models to synthesize realistic-looking medical image data, while on the other hand, the ability to identify synthetic image data in a pool of data is also significantly important. In this study, we explore the potential of the Gemini (textit{gemini-1.0-pro-vision-latest}) and GPT-4V (gpt-4-vision-preview) models for medical image analysis using two modalities of medical image data. Utilizing synthetic and real imaging data, both Gemini AI and GPT-4V are first used to classify real versus synthetic images, followed by an interpretation and analysis of the input images. Experimental results demonstrate that both Gemini and GPT-4 could perform some interpretation of the input images. In this specific experiment, Gemini was able to perform slightly better than the GPT-4V on the classification task. In contrast, responses associated with GPT-4V were mostly generic in nature. Our early investigation presented in this work provides insights into the potential of MLLMs to assist with the classification and interpretation of retinal fundoscopy and lung X-ray images. We also identify key limitations associated with the early investigation study on MLLMs for specialized tasks in medical image analysis.
Read more6/4/2024

0
MRScore: Evaluating Radiology Report Generation with LLM-based Reward System
Yunyi Liu, Zhanyu Wang, Yingshu Li, Xinyu Liang, Lingqiao Liu, Lei Wang, Luping Zhou
In recent years, automated radiology report generation has experienced significant growth. This paper introduces MRScore, an automatic evaluation metric tailored for radiology report generation by leveraging Large Language Models (LLMs). Conventional NLG (natural language generation) metrics like BLEU are inadequate for accurately assessing the generated radiology reports, as systematically demonstrated by our observations within this paper. To address this challenge, we collaborated with radiologists to develop a framework that guides LLMs for radiology report evaluation, ensuring alignment with human analysis. Our framework includes two key components: i) utilizing GPT to generate large amounts of training data, i.e., reports with different qualities, and ii) pairing GPT-generated reports as accepted and rejected samples and training LLMs to produce MRScore as the model reward. Our experiments demonstrate MRScore's higher correlation with human judgments and superior performance in model selection compared to traditional metrics. Our code and datasets will be available on GitHub.
Read more4/30/2024