HowToCaption: Prompting LLMs to Transform Video Annotations at Scale

0
📊
Sign in to get full access
Overview
- Instructional videos are a common source for learning text-video or multimodal representations
- Subtitles extracted from the audio signal using automatic speech recognition (ASR) provide noisy supervision for training text-video models
- This work proposes using large language models (LLMs) to generate high-quality video descriptions aligned with the video content at scale
Plain English Explanation
Instructional videos often have subtitles that are automatically generated from the audio. While these subtitles can be used to train models that combine text and video, the subtitles don't always match what's happening in the video. This can lead to poor performance when using the subtitles to train these models.
This paper suggests using powerful language models, called large language models (LLMs), to generate better video captions that are more aligned with the video content. The researchers developed a method to prompt the LLM to create plausible video captions based on the longer context of the subtitles, rather than just one sentence at a time. They also had the LLM generate timestamps for the captions so they could be aligned with the video.
This allowed them to create a new large-scale dataset of high-quality video captions without any human supervision. When they used this dataset to train text-video models, the models performed significantly better on standard benchmarks. The captions also helped the models differentiate the textual narration from the audio, improving their performance on tasks involving both text and audio.
Technical Explanation
The researchers proposed a method to leverage the capabilities of large language models (LLMs) to generate high-quality video captions aligned with instructional videos at scale. Specifically, they prompt the LLM to create plausible video captions based on the ASR subtitles extracted from the audio signal in the videos.
To capture the contextual information beyond a single sentence, the prompting method takes into account the longer text of the subtitles. The researchers also prompt the LLM to generate timestamps for each produced caption based on the timestamps of the subtitles, and then align the generated captions to the video temporally.
This allowed them to obtain human-style video captions at scale without any human supervision. They applied this method to the HowTo100M dataset, creating a new large-scale dataset called HowToCaption.
Evaluation of the HowToCaption dataset shows that the resulting captions significantly improve performance on various text-video retrieval and video captioning benchmarks compared to using the original ASR subtitles. The captions also lead to a better disentanglement of textual narration from the audio, boosting performance on text-video-audio tasks.
Critical Analysis
The researchers acknowledge that while their method can generate high-quality video captions at scale, there may still be some limitations or room for further improvement. For example, the captions generated by the LLM may not always perfectly match the visual content of the video, and there could be biases or inconsistencies introduced by the prompting process.
Additionally, the researchers did not conduct a detailed analysis of the specific failure cases or areas where the generated captions fall short. It would be helpful to understand the types of errors or shortcomings in the captions to identify opportunities for further refinement of the method.
Furthermore, the researchers did not explore the potential impact of the choice of LLM or the prompting strategy on the quality and alignment of the generated captions. Investigating these factors could lead to insights on how to further optimize the caption generation process.
Overall, the researchers have developed an innovative approach to leveraging the power of LLMs to address the limitations of using ASR subtitles for training text-video models. The resulting HowToCaption dataset represents a significant step forward in the field, but continued research and refinement could lead to even more robust and accurate video caption generation methods.
Conclusion
This paper presents a novel approach to leveraging large language models (LLMs) to generate high-quality video captions aligned with instructional videos at scale. By prompting the LLM to create captions based on the context of the ASR subtitles, and generating timestamps to align the captions with the video, the researchers were able to create a new large-scale dataset called HowToCaption without any human supervision.
The evaluation of the HowToCaption dataset shows that it can significantly improve the performance of text-video models on various benchmarks, compared to using the original ASR subtitles. The generated captions also help to better disentangle the textual narration from the audio, leading to improved performance on tasks involving both text and audio.
This work demonstrates the potential of LLMs to transform low-quality, noisy annotations into high-quality, contextually-relevant video descriptions at scale. As the field of multimodal learning continues to advance, techniques like the one presented in this paper will be crucial for building robust and versatile models that can effectively leverage the rich information available in instructional videos and other multimedia sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Nina Shvetsova, Anna Kukleva, Xudong Hong, Christian Rupprecht, Bernt Schiele, Hilde Kuehne
Instructional videos are a common source for learning text-video or even multimodal representations by leveraging subtitles extracted with automatic speech recognition systems (ASR) from the audio signal in the videos. However, in contrast to human-annotated captions, both speech and subtitles naturally differ from the visual content of the videos and thus provide only noisy supervision. As a result, large-scale annotation-free web video training data remains sub-optimal for training text-video models. In this work, we propose to leverage the capabilities of large language models (LLMs) to obtain high-quality video descriptions aligned with videos at scale. Specifically, we prompt an LLM to create plausible video captions based on ASR subtitles of instructional videos. To this end, we introduce a prompting method that is able to take into account a longer text of subtitles, allowing us to capture the contextual information beyond one single sentence. We further prompt the LLM to generate timestamps for each produced caption based on the timestamps of the subtitles and finally align the generated captions to the video temporally. In this way, we obtain human-style video captions at scale without human supervision. We apply our method to the subtitles of the HowTo100M dataset, creating a new large-scale dataset, HowToCaption. Our evaluation shows that the resulting captions not only significantly improve the performance over many different benchmark datasets for zero-shot text-video retrieval and video captioning, but also lead to a disentangling of textual narration from the audio, boosting the performance in text-video-audio tasks.
Read more9/10/2024

0
Captioning Visualizations with Large Language Models (CVLLM): A Tutorial
Giuseppe Carenini, Jordon Johnson, Ali Salamatian
Automatically captioning visualizations is not new, but recent advances in large language models(LLMs) open exciting new possibilities. In this tutorial, after providing a brief review of Information Visualization (InfoVis) principles and past work in captioning, we introduce neural models and the transformer architecture used in generic LLMs. We then discuss their recent applications in InfoVis, with a focus on captioning. Additionally, we explore promising future directions in this field.
Read more7/1/2024
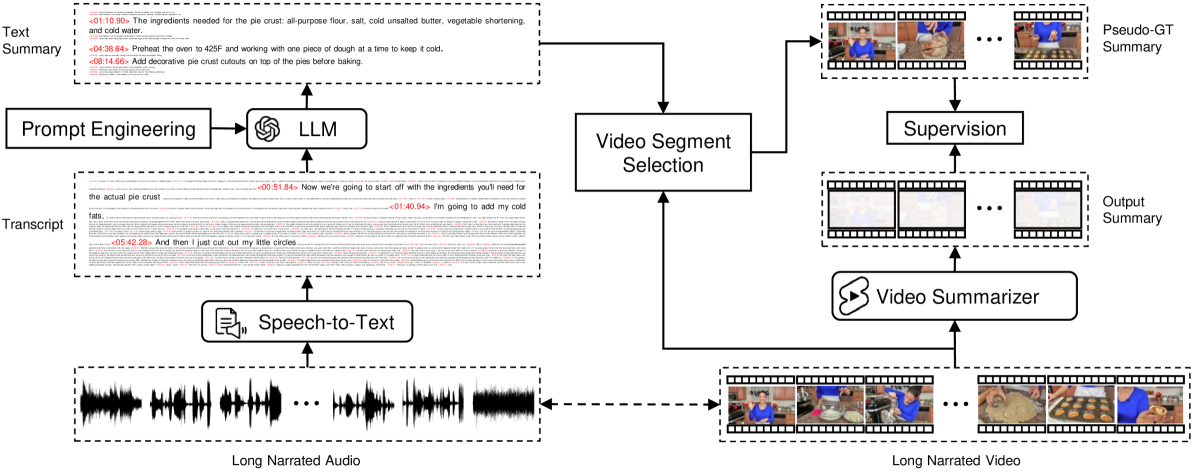
0
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
Read more4/5/2024

0
Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
Read more4/17/2024