Captioning Visualizations with Large Language Models (CVLLM): A Tutorial

0

Sign in to get full access
Overview
- Introduces a tutorial on "Captioning Visualizations with Large Language Models (CVLLM)"
- Covers past editions, similar initiatives, and the target audience for the tutorial
- Provides a technical explanation of the key elements, including experiment design, architecture, and insights
- Offers a critical analysis of the research, discussing caveats, limitations, and areas for further exploration
- Concludes with a summary of the main takeaways and their potential implications
Plain English Explanation
This tutorial provides a comprehensive guide on how to use large language models, such as GPT-3 and DALL-E, to automatically generate captions for visualizations like charts, graphs, and images. The tutorial is designed for a wide audience, including data scientists, visualization designers, and anyone interested in the intersection of natural language processing and visual data.
The tutorial covers the history of similar initiatives and the specific goals and target audience for this edition. It then delves into a detailed technical explanation of the approaches used, including the experimental setup, model architectures, and key insights from the research. This includes the use of synthetic data to boost the performance of vision-language models, as well as advancements in multimodal large language models that enable powerful cross-modal reasoning.
The tutorial also includes a critical analysis of the research, highlighting potential limitations and areas for further exploration. For example, the challenges of adapting these models to diverse datasets and visualization types are discussed, as well as the need for improving the interpretability and controllability of the generated captions.
Overall, this tutorial is a valuable resource for anyone interested in leveraging the latest advancements in natural language processing and computer vision to enhance data visualization and communication. By providing a clear and accessible overview of the technical details, as well as a critical analysis of the research, the tutorial aims to empower readers to explore and apply these exciting new capabilities in their own work.
Technical Explanation
The tutorial covers the "Captioning Visualizations with Large Language Models (CVLLM)" approach, which leverages the powerful cross-modal reasoning capabilities of multimodal large language models to automatically generate descriptive captions for a wide range of visualizations.
The key elements of the CVLLM approach include:
-
Experimental Setup: The researchers curated a large dataset of visualizations, such as charts, graphs, and infographics, paired with human-written captions. This dataset was used to fine-tune and evaluate the performance of various language models on the task of visualization captioning.
-
Model Architecture: The tutorial explores different model architectures, including vision-language models that combine computer vision and natural language processing, as well as techniques for boosting the performance of these models using synthetic captions.
-
Key Insights: The tutorial discusses the insights gained from the research, such as the ability of large language models to capture the semantic and contextual information in visualizations, and the importance of incorporating domain-specific knowledge to generate high-quality captions.
The technical explanation delves into the details of the experimental setup, model architectures, and key findings, providing readers with a comprehensive understanding of the CVLLM approach and its potential applications in the field of automated data visualization from natural language.
Critical Analysis
The tutorial acknowledges several caveats and limitations of the CVLLM approach:
-
Dataset Diversity: The researchers note that the current dataset used for training and evaluation may not be representative of the full diversity of visualizations encountered in real-world scenarios. Expanding the dataset to include a wider range of visualization types and domains is an important area for future research.
-
Interpretability and Controllability: While the large language models used in CVLLM can generate sophisticated captions, the underlying decision-making process can be opaque. Improving the interpretability and controllability of the generated captions is a key challenge to address for practical applications.
-
Generalization and Adaptation: The tutorial highlights the need to further explore the ability of CVLLM models to generalize to new visualization types and adapt to specific user preferences or domain-specific requirements.
The critical analysis encourages readers to think critically about the limitations and potential issues with the CVLLM approach, while also recognizing the significant advancements made in the field of vision-language modeling. By identifying these areas for further research and improvement, the tutorial aims to guide future work and foster a deeper understanding of the challenges and opportunities in this rapidly evolving field.
Conclusion
The "Captioning Visualizations with Large Language Models (CVLLM)" tutorial provides a comprehensive overview of a powerful approach for automatically generating descriptive captions for a wide range of visualizations. By leveraging the cross-modal reasoning capabilities of large language models, the CVLLM approach has the potential to revolutionize the way we interact with and communicate data through visual representations.
The tutorial's detailed technical explanation, coupled with a critical analysis of the research, equips readers with a thorough understanding of the current state of the art and the key challenges that need to be addressed. As the field of multimodal large language models continues to advance, the insights and recommendations provided in this tutorial will be invaluable for researchers, practitioners, and anyone interested in enhancing data visualization and communication through the power of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Captioning Visualizations with Large Language Models (CVLLM): A Tutorial
Giuseppe Carenini, Jordon Johnson, Ali Salamatian
Automatically captioning visualizations is not new, but recent advances in large language models(LLMs) open exciting new possibilities. In this tutorial, after providing a brief review of Information Visualization (InfoVis) principles and past work in captioning, we introduce neural models and the transformer architecture used in generic LLMs. We then discuss their recent applications in InfoVis, with a focus on captioning. Additionally, we explore promising future directions in this field.
Read more7/1/2024
0
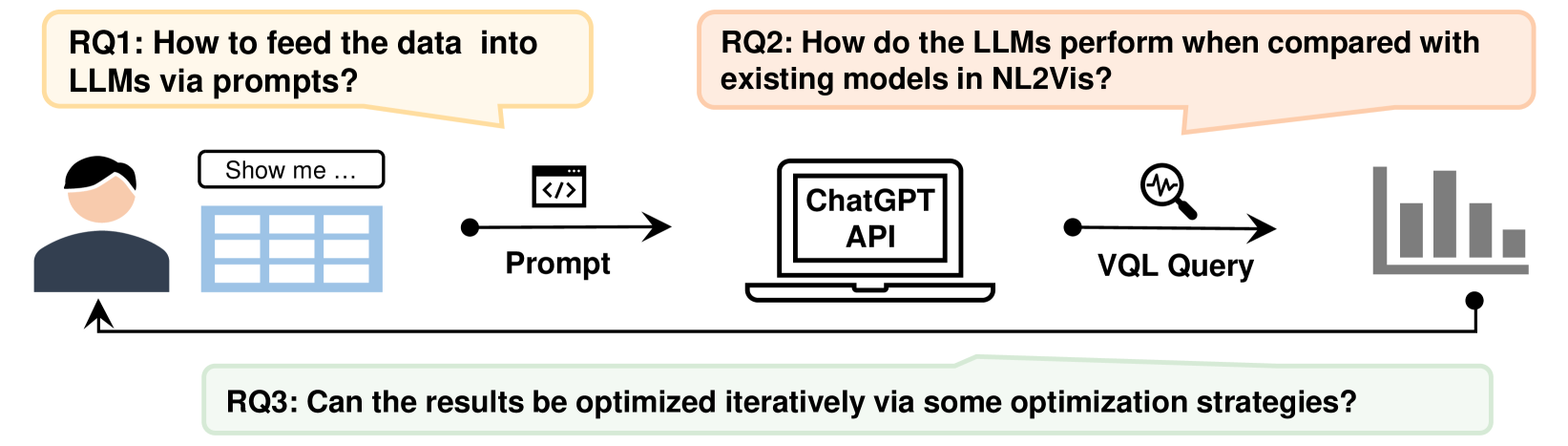
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Yang Wu, Yao Wan, Hongyu Zhang, Yulei Sui, Wucai Wei, Wei Zhao, Guandong Xu, Hai Jin
The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
Read more4/29/2024
📊
0
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Nina Shvetsova, Anna Kukleva, Xudong Hong, Christian Rupprecht, Bernt Schiele, Hilde Kuehne
Instructional videos are a common source for learning text-video or even multimodal representations by leveraging subtitles extracted with automatic speech recognition systems (ASR) from the audio signal in the videos. However, in contrast to human-annotated captions, both speech and subtitles naturally differ from the visual content of the videos and thus provide only noisy supervision. As a result, large-scale annotation-free web video training data remains sub-optimal for training text-video models. In this work, we propose to leverage the capabilities of large language models (LLMs) to obtain high-quality video descriptions aligned with videos at scale. Specifically, we prompt an LLM to create plausible video captions based on ASR subtitles of instructional videos. To this end, we introduce a prompting method that is able to take into account a longer text of subtitles, allowing us to capture the contextual information beyond one single sentence. We further prompt the LLM to generate timestamps for each produced caption based on the timestamps of the subtitles and finally align the generated captions to the video temporally. In this way, we obtain human-style video captions at scale without human supervision. We apply our method to the subtitles of the HowTo100M dataset, creating a new large-scale dataset, HowToCaption. Our evaluation shows that the resulting captions not only significantly improve the performance over many different benchmark datasets for zero-shot text-video retrieval and video captioning, but also lead to a disentangling of textual narration from the audio, boosting the performance in text-video-audio tasks.
Read more9/10/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024