HTR-VT: Handwritten Text Recognition with Vision Transformer

0

Sign in to get full access
Overview
- HTR-VT: Handwritten Text Recognition with Vision Transformer is a research paper that presents a new model for recognizing handwritten text using a vision transformer architecture.
- The paper explores the use of vision transformers, a type of deep learning model, for the task of handwritten text recognition (HTR).
- The proposed HTR-VT model outperforms previous state-of-the-art approaches on multiple benchmark datasets, demonstrating the effectiveness of vision transformers for this application.
Plain English Explanation
The paper introduces a new model called HTR-VT, which stands for Handwritten Text Recognition with Vision Transformer. This model is designed to recognize and transcribe handwritten text, a task that is important for applications like digitizing historical documents or processing handwritten forms.
The key innovation in HTR-VT is the use of a vision transformer architecture. Vision transformers are a type of deep learning model that have been shown to be effective for various computer vision tasks, such as image classification. The researchers in this paper hypothesized that the strengths of vision transformers, like their ability to capture long-range dependencies, could also be beneficial for handwritten text recognition.
To evaluate the performance of HTR-VT, the researchers tested it on several benchmark datasets for handwritten text recognition. The results showed that HTR-VT outperformed previous state-of-the-art models on these datasets, demonstrating the effectiveness of the vision transformer approach for this problem.
Technical Explanation
The HTR-VT model is built upon the vision transformer (ViT) architecture, which has been successful in various computer vision tasks. The key components of the HTR-VT model include:
- Input Preprocessing: The handwritten text images are first preprocessed by resizing and normalizing the pixel values.
- Vision Transformer Encoder: The preprocessed images are then fed into a vision transformer encoder, which consists of a series of transformer blocks. Each block applies self-attention and feed-forward neural network layers to extract visual features from the input.
- Sequence Decoder: The output of the vision transformer encoder is used as input to a sequence decoder, which generates the transcribed text character by character using an autoregressive approach.
- Training Objective: The model is trained to minimize the cross-entropy loss between the predicted and ground truth character sequences.
The researchers conducted experiments on several benchmark datasets for handwritten text recognition, including IAM, RIMES, and CVL. The results showed that HTR-VT outperformed previous state-of-the-art models, such as those based on convolutional neural networks and recurrent neural networks, in terms of transcription accuracy.
Critical Analysis
The paper provides a compelling demonstration of the effectiveness of vision transformers for the task of handwritten text recognition. The authors thoroughly evaluate the performance of HTR-VT on multiple benchmark datasets and compare it to previous state-of-the-art approaches.
One potential limitation of the study is that it does not explore the impact of different architectural choices or hyperparameter settings on the model's performance. While the authors do provide some details on the model configuration, a more comprehensive ablation study could have shed light on the critical design decisions that contributed to the model's success.
Additionally, the paper does not delve into the interpretability or explainability of the HTR-VT model. Understanding the internal representations and decision-making processes of the vision transformer could be valuable for gaining insights into the strengths and weaknesses of the approach, as well as potentially improving the model's performance or robustness.
Overall, the research presented in this paper represents a significant advancement in the field of handwritten text recognition and demonstrates the potential of vision transformers for this and other challenging computer vision tasks.
Conclusion
The HTR-VT paper introduces a novel approach to handwritten text recognition using a vision transformer architecture. The proposed model, HTR-VT, outperforms previous state-of-the-art methods on multiple benchmark datasets, showcasing the effectiveness of vision transformers for this important task.
The success of HTR-VT highlights the potential of transformer-based models, which have revolutionized various domains, including natural language processing and computer vision. The ability of vision transformers to capture long-range dependencies and their scalability to larger input sizes make them a promising direction for advancing the state-of-the-art in handwritten text recognition and other areas of document analysis.
As the field of deep learning continues to evolve, research like this on HTR-VT can inspire further innovations and applications of transformer-based architectures, ultimately contributing to the development of more robust and capable document understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!HTR-VT: Handwritten Text Recognition with Vision Transformer
Yuting Li, Dexiong Chen, Tinglong Tang, Xi Shen
We explore the application of Vision Transformer (ViT) for handwritten text recognition. The limited availability of labeled data in this domain poses challenges for achieving high performance solely relying on ViT. Previous transformer-based models required external data or extensive pre-training on large datasets to excel. To address this limitation, we introduce a data-efficient ViT method that uses only the encoder of the standard transformer. We find that incorporating a Convolutional Neural Network (CNN) for feature extraction instead of the original patch embedding and employ Sharpness-Aware Minimization (SAM) optimizer to ensure that the model can converge towards flatter minima and yield notable enhancements. Furthermore, our introduction of the span mask technique, which masks interconnected features in the feature map, acts as an effective regularizer. Empirically, our approach competes favorably with traditional CNN-based models on small datasets like IAM and READ2016. Additionally, it establishes a new benchmark on the LAM dataset, currently the largest dataset with 19,830 training text lines. The code is publicly available at: https://github.com/YutingLi0606/HTR-VT.
Read more9/16/2024

0
Self-Supervised Vision Transformers for Writer Retrieval
Tim Raven, Arthur Matei, Gernot A. Fink
While methods based on Vision Transformers (ViT) have achieved state-of-the-art performance in many domains, they have not yet been applied successfully in the domain of writer retrieval. The field is dominated by methods using handcrafted features or features extracted from Convolutional Neural Networks. In this work, we bridge this gap and present a novel method that extracts features from a ViT and aggregates them using VLAD encoding. The model is trained in a self-supervised fashion without any need for labels. We show that extracting local foreground features is superior to using the ViT's class token in the context of writer retrieval. We evaluate our method on two historical document collections. We set a new state-at-of-art performance on the Historical-WI dataset (83.1% mAP), and the HisIR19 dataset (95.0% mAP). Additionally, we demonstrate that our ViT feature extractor can be directly applied to modern datasets such as the CVL database (98.6% mAP) without any fine-tuning.
Read more9/4/2024
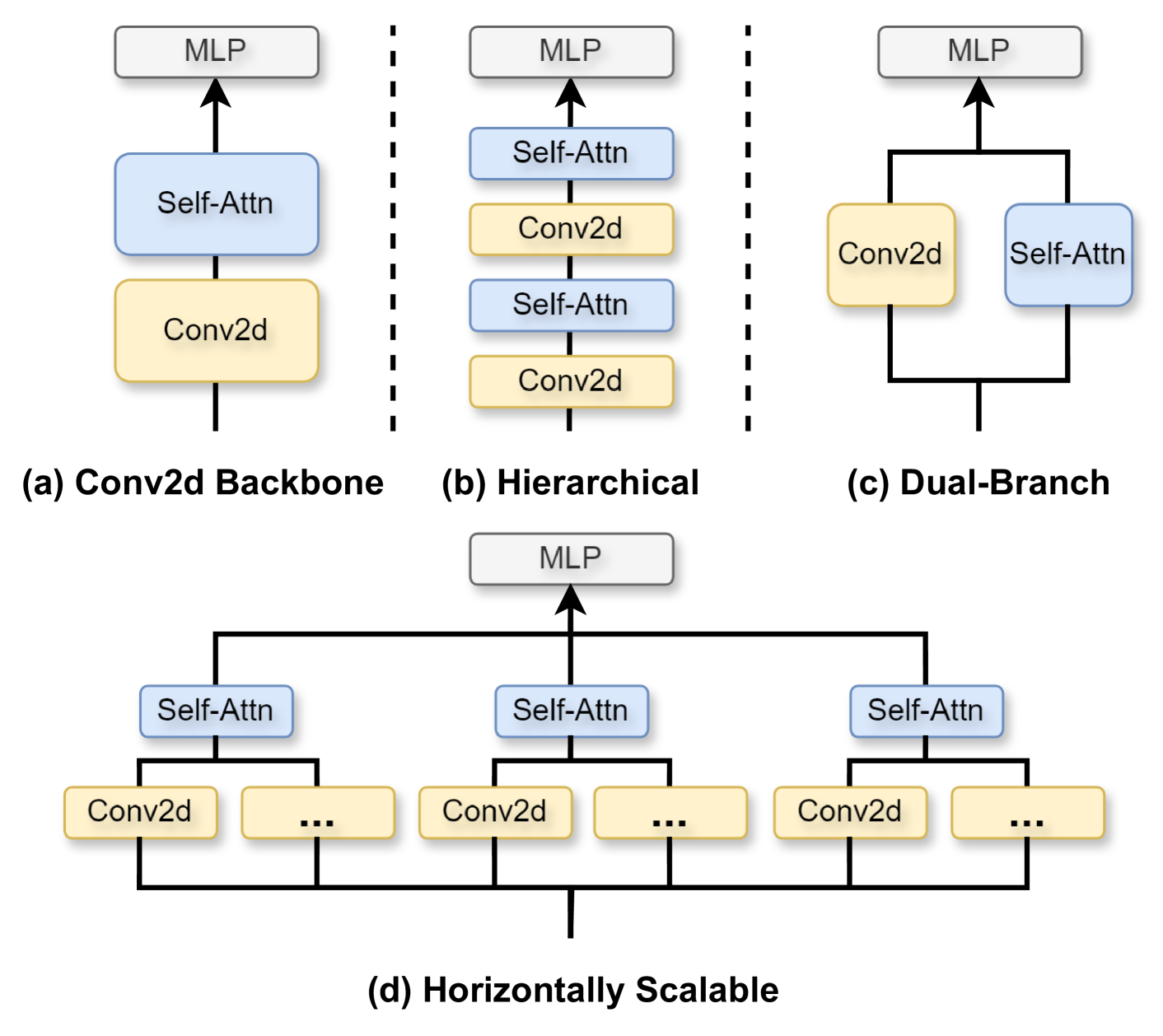
0
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
Due to its deficiency in prior knowledge (inductive bias), Vision Transformer (ViT) requires pre-training on large-scale datasets to perform well. Moreover, the growing layers and parameters in ViT models impede their applicability to devices with limited computing resources. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT) scheme. Specifically, a novel image-level feature embedding is introduced to ViT, where the preserved inductive bias allows the model to eliminate the need for pre-training while outperforming on small datasets. Besides, a novel horizontally scalable architecture is designed, facilitating collaborative model training and inference across multiple computing devices. The experimental results depict that, without pre-training, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes on small datasets, while providing existing CNN backbones up to 3.1% improvement in top-1 accuracy on ImageNet. The code is available at https://github.com/xuchenhao001/HSViT.
Read more7/17/2024
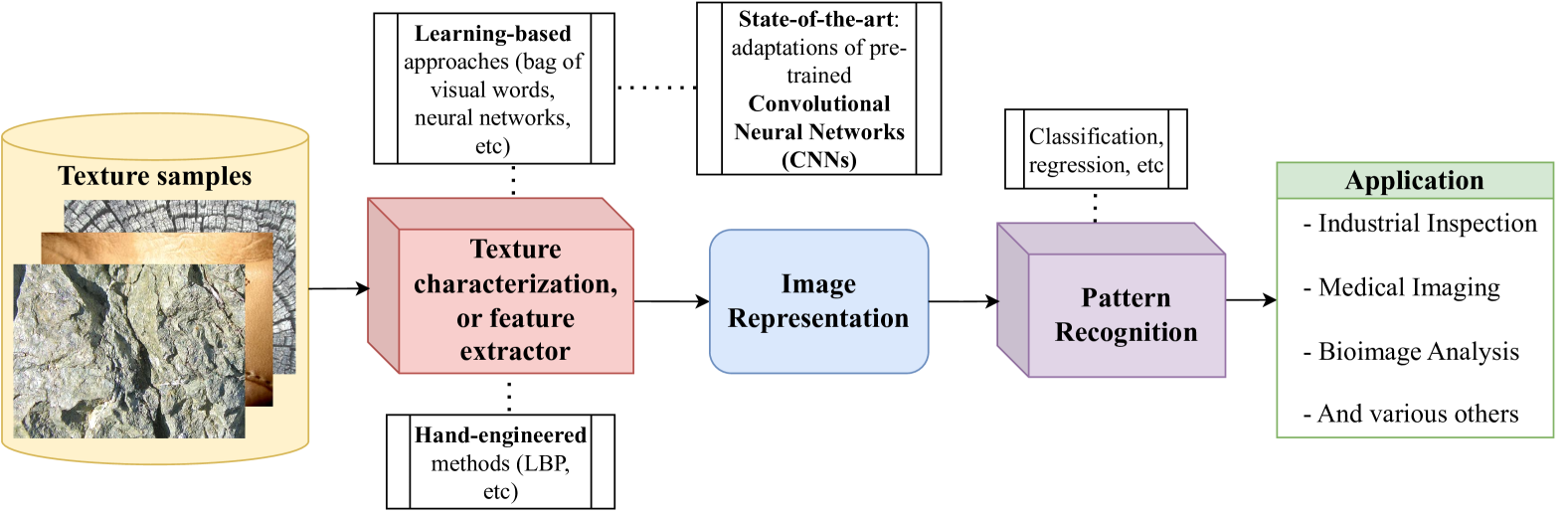
0
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
Read more6/11/2024