HTVM: Efficient Neural Network Deployment On Heterogeneous TinyML Platforms

0

Sign in to get full access
Overview
- This paper, "HTVM: Efficient Neural Network Deployment On Heterogeneous TinyML Platforms," presents a framework for deploying neural networks on diverse low-power embedded devices.
- The project has been funded by the Fund for Scientific Research Flanders (FWO Vlaanderen), the EU Horizon 2020 programme, and the Flanders AI Research Program (FAIR).
Plain English Explanation
The paper focuses on the challenge of running complex machine learning models, like convolutional neural networks, on small, low-power devices, which are often used in "edge computing" applications close to the data source. These devices, such as microcontrollers, have limited processing power and memory compared to powerful desktop or server-class hardware.
The researchers developed a system called HTVM (Heterogeneous TinyML Virtual Machine) that can efficiently deploy neural networks on a variety of these tiny, resource-constrained platforms. HTVM acts as an intermediary between the neural network model and the target hardware, optimizing the model to run well on the device's specific capabilities.
This is important because it allows developers to use advanced machine learning techniques, like deep learning, in a wider range of real-world applications, like optimizing deployment of tiny transformers on low-power MCUs, distributed training across heterogeneous clusters, online learning and semantic management of TinyML systems, and co-designing algorithms and hardware for neural networks. This can enable a wide range of "smart" devices and sensors with enhanced capabilities.
Technical Explanation
The HTVM framework consists of several key components:
- Compiler: Translates the neural network model into an intermediate representation that can be optimized for different target hardware platforms.
- Runtime: Manages the execution of the neural network model on the target device, handling tasks like memory management and scheduling.
- Hardware Abstraction Layer: Provides a common interface for interacting with the diverse hardware capabilities of different TinyML platforms, hiding the underlying complexity.
The researchers evaluated HTVM on a range of TinyML devices, including microcontrollers from ARM, RISC-V, and Tensilica architectures. They demonstrated that HTVM can efficiently deploy neural networks, achieving performance and energy efficiency comparable to hand-optimized implementations, while providing a unified programming model across the heterogeneous hardware.
Critical Analysis
The paper provides a comprehensive solution for deploying neural networks on resource-constrained edge devices, addressing an important challenge in the field of tiny shared blocks for efficient DNN deployment. The HTVM framework is designed to be flexible and extensible, supporting a variety of target hardware platforms.
However, the paper does not delve into the specific optimizations and trade-offs made in the compiler and runtime components of HTVM. Additionally, the evaluation could be expanded to include a wider range of neural network architectures and real-world applications to further demonstrate the system's capabilities and limitations.
Researchers may also want to explore ways to improve the portability and ease of use of the HTVM framework, potentially through the development of automated tools or integration with popular machine learning frameworks.
Conclusion
The HTVM framework presented in this paper represents a significant advancement in the field of efficient neural network deployment on heterogeneous TinyML platforms. By providing a unified, optimized solution for running complex machine learning models on resource-constrained devices, HTVM enables the development of a new generation of smart, connected devices with enhanced sensing and processing capabilities. This work has important implications for the continued growth of edge computing and the broader Internet of Things ecosystem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HTVM: Efficient Neural Network Deployment On Heterogeneous TinyML Platforms
Josse Van Delm, Maarten Vandersteegen, Alessio Burrello, Giuseppe Maria Sarda, Francesco Conti, Daniele Jahier Pagliari, Luca Benini, Marian Verhelst
Optimal deployment of deep neural networks (DNNs) on state-of-the-art Systems-on-Chips (SoCs) is crucial for tiny machine learning (TinyML) at the edge. The complexity of these SoCs makes deployment non-trivial, as they typically contain multiple heterogeneous compute cores with limited, programmer-managed memory to optimize latency and energy efficiency. We propose HTVM - a compiler that merges TVM with DORY to maximize the utilization of heterogeneous accelerators and minimize data movements. HTVM allows deploying the MLPerf(TM) Tiny suite on DIANA, an SoC with a RISC-V CPU, and digital and analog compute-in-memory AI accelerators, at 120x improved performance over plain TVM deployment.
Read more6/12/2024
0
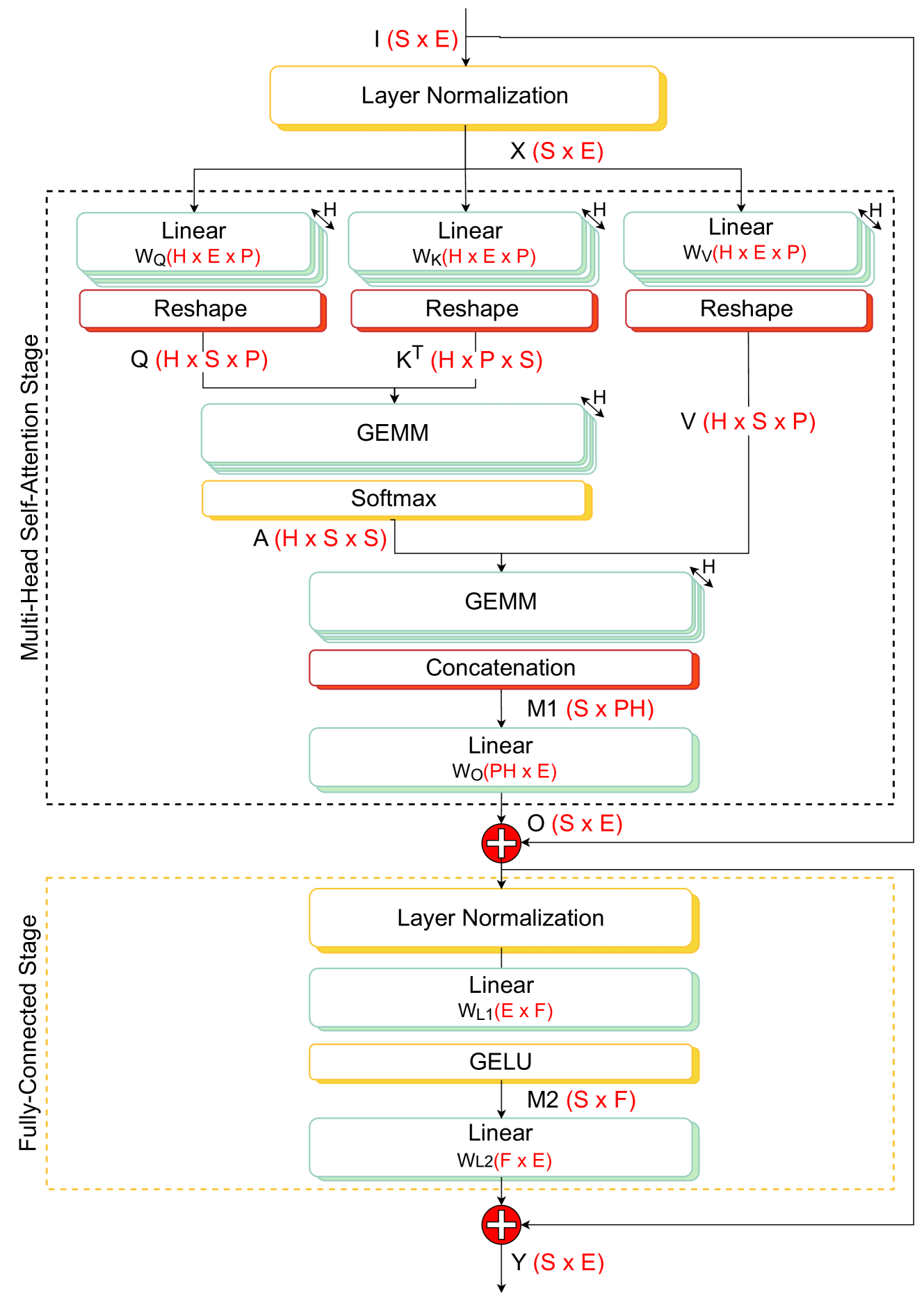
Optimizing the Deployment of Tiny Transformers on Low-Power MCUs
Victor J. B. Jung, Alessio Burrello, Moritz Scherer, Francesco Conti, Luca Benini
Transformer networks are rapidly becoming SotA in many fields, such as NLP and CV. Similarly to CNN, there is a strong push for deploying Transformer models at the extreme edge, ultimately fitting the tiny power budget and memory footprint of MCUs. However, the early approaches in this direction are mostly ad-hoc, platform, and model-specific. This work aims to enable and optimize the flexible, multi-platform deployment of encoder Tiny Transformers on commercial MCUs. We propose a complete framework to perform end-to-end deployment of Transformer models onto single and multi-core MCUs. Our framework provides an optimized library of kernels to maximize data reuse and avoid unnecessary data marshaling operations into the crucial attention block. A novel MHSA inference schedule, named Fused-Weight Self-Attention, is introduced, fusing the linear projection weights offline to further reduce the number of operations and parameters. Furthermore, to mitigate the memory peak reached by the computation of the attention map, we present a Depth-First Tiling scheme for MHSA. We evaluate our framework on three different MCU classes exploiting ARM and RISC-V ISA, namely the STM32H7, the STM32L4, and GAP9 (RV32IMC-XpulpV2). We reach an average of 4.79x and 2.0x lower latency compared to SotA libraries CMSIS-NN (ARM) and PULP-NN (RISC-V), respectively. Moreover, we show that our MHSA depth-first tiling scheme reduces the memory peak by up to 6.19x, while the fused-weight attention can reduce the runtime by 1.53x, and number of parameters by 25%. We report significant improvements across several Tiny Transformers: for instance, when executing a transformer block for the task of radar-based hand-gesture recognition on GAP9, we achieve a latency of 0.14ms and energy consumption of 4.92 micro-joules, 2.32x lower than the SotA PULP-NN library on the same platform.
Read more4/5/2024
0
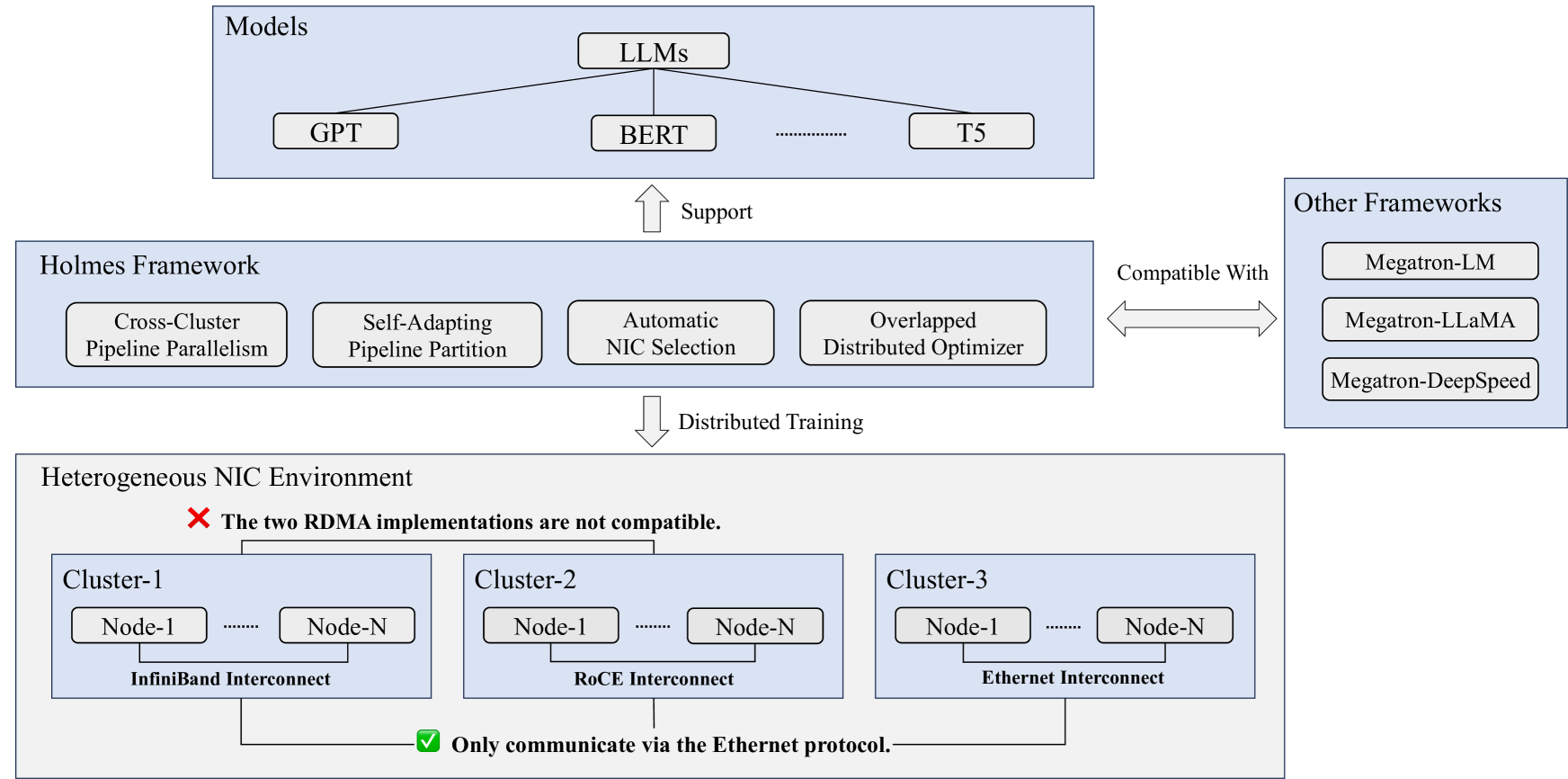
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Fei Yang, Shuang Peng, Ning Sun, Fangyu Wang, Yuanyuan Wang, Fu Wu, Jiezhong Qiu, Aimin Pan
Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Read more4/30/2024
🤷
0
On-device Online Learning and Semantic Management of TinyML Systems
Haoyu Ren, Xue Li, Darko Anicic, Thomas A. Runkler
Recent advances in Tiny Machine Learning (TinyML) empower low-footprint embedded devices for real-time on-device Machine Learning. While many acknowledge the potential benefits of TinyML, its practical implementation presents unique challenges. This study aims to bridge the gap between prototyping single TinyML models and developing reliable TinyML systems in production: (1) Embedded devices operate in dynamically changing conditions. Existing TinyML solutions primarily focus on inference, with models trained offline on powerful machines and deployed as static objects. However, static models may underperform in the real world due to evolving input data distributions. We propose online learning to enable training on constrained devices, adapting local models towards the latest field conditions. (2) Nevertheless, current on-device learning methods struggle with heterogeneous deployment conditions and the scarcity of labeled data when applied across numerous devices. We introduce federated meta-learning incorporating online learning to enhance model generalization, facilitating rapid learning. This approach ensures optimal performance among distributed devices by knowledge sharing. (3) Moreover, TinyML's pivotal advantage is widespread adoption. Embedded devices and TinyML models prioritize extreme efficiency, leading to diverse characteristics ranging from memory and sensors to model architectures. Given their diversity and non-standardized representations, managing these resources becomes challenging as TinyML systems scale up. We present semantic management for the joint management of models and devices at scale. We demonstrate our methods through a basic regression example and then assess them in three real-world TinyML applications: handwritten character image classification, keyword audio classification, and smart building presence detection, confirming our approaches' effectiveness.
Read more5/17/2024