Human-artificial intelligence teaming for scientific information extraction from data-driven additive manufacturing research using large language models

0
⛏️
Sign in to get full access
Overview
- Data-driven research in Additive Manufacturing (AM) has grown significantly in recent years, leading to a large amount of scientific literature.
- This knowledge consists of AM and Artificial Intelligence (AI) contexts that have not been integrated and organized in a comprehensive way.
- Extracting relevant information from these works requires substantial effort and time.
- AM domain experts have written review papers, but information specific to AM and AI still requires manual effort to extract.
- Recent success of large language models like BERT and GPT on textual data has opened the possibility of expediting scientific information extraction.
Plain English Explanation
Additive Manufacturing (AM) is a type of manufacturing that creates objects by building them up layer by layer, rather than subtracting material. It has become an important area of research in recent years, with a lot of new studies and papers being published.
However, the knowledge contained in these papers has not been well organized or integrated, especially when it comes to the intersection of AM and Artificial Intelligence (AI). Extracting the key information from these papers requires a lot of time and effort.
Experts in the AM field have tried to summarize the research in review papers, but even then, the specific details about how AM and AI relate to each other still need to be manually extracted.
Fortunately, the impressive performance of large language models like BERT and GPT on processing and understanding textual data has opened up new possibilities. These models could potentially be used to quickly extract the relevant information from the AM research papers, saving time and effort.
Technical Explanation
The paper proposes a framework that enables collaboration between AM and AI experts to continuously extract scientific information from data-driven AM literature. A demonstration tool is implemented based on this framework, and a case study is conducted to extract information relevant to datasets, modeling, sensing, and AM system categories.
The researchers show that large language models (LLMs) have the ability to expedite the extraction of relevant information from data-driven AM literature. The framework can be used to extract information not only from AM literature, but also from the broader design and manufacturing literature in the engineering discipline.
Critical Analysis
The paper presents a promising approach to addressing the challenge of efficiently extracting relevant information from the growing body of data-driven AM research. By leveraging the capabilities of large language models, the proposed framework has the potential to save significant time and effort for AM and AI experts.
However, the paper does not provide a detailed evaluation of the framework's performance or accuracy in information extraction. It would be helpful to understand the specific metrics used to assess the framework's effectiveness, as well as any limitations or potential sources of error.
Additionally, the paper does not discuss the computational resources and training required to deploy the framework, which could be an important consideration for its practical implementation. Further research may be needed to address these aspects and ensure the framework's scalability and robustness.
Conclusion
This paper presents a novel framework that combines the expertise of AM and AI researchers to streamline the process of extracting relevant information from the growing body of data-driven AM literature. By leveraging the capabilities of large language models, the framework has the potential to significantly reduce the time and effort required to synthesize and apply the knowledge contained in these scientific works.
While the paper provides a promising proof-of-concept, further research and evaluation are needed to fully assess the framework's performance and practical implications. Nevertheless, this work represents an important step towards enhancing the efficiency and impact of data-driven research in the field of Additive Manufacturing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
Human-artificial intelligence teaming for scientific information extraction from data-driven additive manufacturing research using large language models
Mutahar Safdar, Jiarui Xie, Andrei Mircea, Yaoyao Fiona Zhao
Data-driven research in Additive Manufacturing (AM) has gained significant success in recent years. This has led to a plethora of scientific literature to emerge. The knowledge in these works consists of AM and Artificial Intelligence (AI) contexts that have not been mined and formalized in an integrated way. It requires substantial effort and time to extract scientific information from these works. AM domain experts have contributed over two dozen review papers to summarize these works. However, information specific to AM and AI contexts still requires manual effort to extract. The recent success of foundation models such as BERT (Bidirectional Encoder Representations for Transformers) or GPT (Generative Pre-trained Transformers) on textual data has opened the possibility of expediting scientific information extraction. We propose a framework that enables collaboration between AM and AI experts to continuously extract scientific information from data-driven AM literature. A demonstration tool is implemented based on the proposed framework and a case study is conducted to extract information relevant to the datasets, modeling, sensing, and AM system categories. We show the ability of LLMs (Large Language Models) to expedite the extraction of relevant information from data-driven AM literature. In the future, the framework can be used to extract information from the broader design and manufacturing literature in the engineering discipline.
Read more7/29/2024

0
Knowledge AI: Fine-tuning NLP Models for Facilitating Scientific Knowledge Extraction and Understanding
Balaji Muralidharan, Hayden Beadles, Reza Marzban, Kalyan Sashank Mupparaju
This project investigates the efficacy of Large Language Models (LLMs) in understanding and extracting scientific knowledge across specific domains and to create a deep learning framework: Knowledge AI. As a part of this framework, we employ pre-trained models and fine-tune them on datasets in the scientific domain. The models are adapted for four key Natural Language Processing (NLP) tasks: summarization, text generation, question answering, and named entity recognition. Our results indicate that domain-specific fine-tuning significantly enhances model performance in each of these tasks, thereby improving their applicability for scientific contexts. This adaptation enables non-experts to efficiently query and extract information within targeted scientific fields, demonstrating the potential of fine-tuned LLMs as a tool for knowledge discovery in the sciences.
Read more8/12/2024
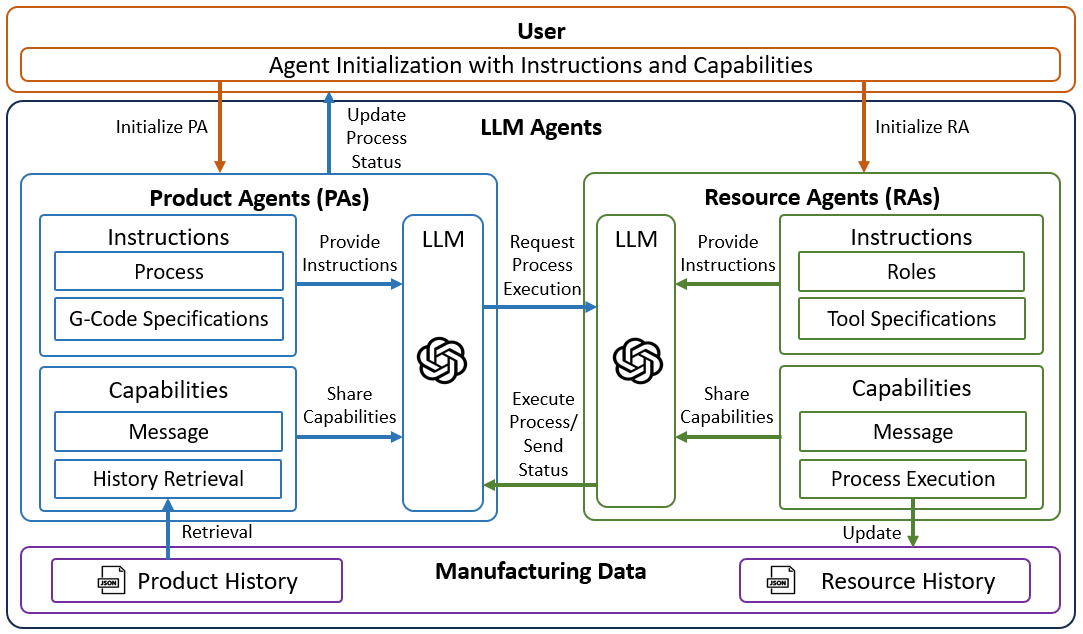
0
Large Language Model-Enabled Multi-Agent Manufacturing Systems
Jonghan Lim, Birgit Vogel-Heuser, Ilya Kovalenko
Traditional manufacturing faces challenges adapting to dynamic environments and quickly responding to manufacturing changes. The use of multi-agent systems has improved adaptability and coordination but requires further advancements in rapid human instruction comprehension, operational adaptability, and coordination through natural language integration. Large language models like GPT-3.5 and GPT-4 enhance multi-agent manufacturing systems by enabling agents to communicate in natural language and interpret human instructions for decision-making. This research introduces a novel framework where large language models enhance the capabilities of agents in manufacturing, making them more adaptable, and capable of processing context-specific instructions. A case study demonstrates the practical application of this framework, showing how agents can effectively communicate, understand tasks, and execute manufacturing processes, including precise G-code allocation among agents. The findings highlight the importance of continuous large language model integration into multi-agent manufacturing systems and the development of sophisticated agent communication protocols for a more flexible manufacturing system.
Read more6/24/2024
💬
0
The emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review
Dmitry Scherbakov, Nina Hubig, Vinita Jansari, Alexander Bakumenko, Leslie A. Lenert
Objective: This study aims to summarize the usage of Large Language Models (LLMs) in the process of creating a scientific review. We look at the range of stages in a review that can be automated and assess the current state-of-the-art research projects in the field. Materials and Methods: The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar databases by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on which uses OpenAI gpt-4o model. ChatGPT was used to clean extracted data and generate code for figures in this manuscript, ChatGPT and Scite.ai were used in drafting all components of the manuscript, except the methods and discussion sections. Results: 3,788 articles were retrieved, and 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n=126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n=26, 15.1%) were actual reviews that used LLM during their creation. Most citations focused on automation of a particular stage of review, such as Searching for publications (n=60, 34.9%), and Data extraction (n=54, 31.4%). When comparing pooled performance of GPT-based and BERT-based models, the former were better in data extraction with mean precision 83.0% (SD=10.4), and recall 86.0% (SD=9.8), while being slightly less accurate in title and abstract screening stage (Maccuracy=77.3%, SD=13.0). Discussion/Conclusion: Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. The results looked promising, and we anticipate that LLMs will change in the near future the way the scientific reviews are conducted.
Read more9/10/2024