Human Insights Driven Latent Space for Different Driving Perspectives: A Unified Encoder for Efficient Multi-Task Inference

0

Sign in to get full access
Overview
- Presents a unified encoder model for efficient multi-task inference in autonomous driving
- Leverages human insights to learn a latent space that captures different driving perspectives
- Enables simultaneous prediction of diverse driving-related tasks from a shared backbone
Plain English Explanation
This research paper introduces a new approach for autonomous driving systems that aims to improve their efficiency and performance. The key idea is to use a unified encoder that can simultaneously handle multiple driving-related tasks, rather than having separate models for each task.
The researchers recognized that human drivers often consider different perspectives when navigating a scene, such as the road layout, nearby vehicles, pedestrians, and traffic signs. Their model learns to capture these diverse viewpoints in a shared "latent space" - a compact representation that encodes all the relevant information.
By optimizing this latent space to support various driving tasks, the researchers were able to create a single, efficient encoder that can predict things like lane segmentation, object detection, and traffic light recognition all at once. This multi-task approach reduces the overall complexity of the system and allows for faster, more accurate decision-making in autonomous vehicles.
Technical Explanation
The key contribution of this work is the development of a unified encoder that can efficiently handle multiple driving-related tasks simultaneously. The authors observed that human drivers consider different perspectives when navigating a scene, such as the road layout, nearby vehicles, pedestrians, and traffic signals.
To capture these diverse viewpoints, the researchers propose learning a latent space that encodes the relevant information. By optimizing this latent space to support various driving tasks, they were able to create a single, efficient encoder that can predict things like lane segmentation, object detection, and traffic light recognition all at once.
The multi-task approach reduces the overall complexity of the system and allows for faster, more accurate decision-making in autonomous vehicles. The researchers demonstrate the effectiveness of their approach through extensive experiments on several benchmark datasets.
Critical Analysis
The paper presents a novel and promising approach for improving the efficiency and performance of autonomous driving systems. By learning a unified encoder that can handle multiple tasks simultaneously, the authors have addressed a key challenge in the field - the complexity and computational burden of deploying separate models for each task.
However, the paper does not provide a detailed analysis of the potential limitations or caveats of their approach. For example, it would be valuable to understand how the model's performance compares to state-of-the-art task-specific models, and whether there are any trade-offs in terms of accuracy or robustness when using a shared encoder.
Additionally, the paper does not discuss the implications of their work for real-world deployment in autonomous vehicles. It would be helpful to understand how the model might perform in diverse and dynamic driving scenarios, and what further research or engineering would be needed to translate these laboratory findings into practical solutions.
Conclusion
This research paper presents a novel approach for autonomous driving systems that leverages human insights to learn a unified encoder capable of efficiently handling multiple driving-related tasks. By optimizing a latent space to capture diverse driving perspectives, the authors have developed a multi-task model that can predict things like lane segmentation, object detection, and traffic light recognition simultaneously.
This innovative approach has the potential to significantly improve the efficiency and performance of autonomous driving systems, ultimately leading to safer and more reliable self-driving vehicles. While the paper raises some questions about the practical limitations and deployment challenges, the core ideas presented here represent an important step forward in the field of autonomous driving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Human Insights Driven Latent Space for Different Driving Perspectives: A Unified Encoder for Efficient Multi-Task Inference
Huy-Dung Nguyen, Anass Bairouk, Mirjana Maras, Wei Xiao, Tsun-Hsuan Wang, Patrick Chareyre, Ramin Hasani, Marc Blanchon, Daniela Rus
Autonomous driving holds great potential to transform road safety and traffic efficiency by minimizing human error and reducing congestion. A key challenge in realizing this potential is the accurate estimation of steering angles, which is essential for effective vehicle navigation and control. Recent breakthroughs in deep learning have made it possible to estimate steering angles directly from raw camera inputs. However, the limited available navigation data can hinder optimal feature learning, impacting the system's performance in complex driving scenarios. In this paper, we propose a shared encoder trained on multiple computer vision tasks critical for urban navigation, such as depth, pose, and 3D scene flow estimation, as well as semantic, instance, panoptic, and motion segmentation. By incorporating diverse visual information used by humans during navigation, this unified encoder might enhance steering angle estimation. To achieve effective multi-task learning within a single encoder, we introduce a multi-scale feature network for pose estimation to improve depth learning. Additionally, we employ knowledge distillation from a multi-backbone model pretrained on these navigation tasks to stabilize training and boost performance. Our findings demonstrate that a shared backbone trained on diverse visual tasks is capable of providing overall perception capabilities. While our performance in steering angle estimation is comparable to existing methods, the integration of human-like perception through multi-task learning holds significant potential for advancing autonomous driving systems. More details and the pretrained model are available at https://hi-computervision.github.io/uni-encoder/.
Read more9/17/2024

0
HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
Zhongyu Xia, ZhiWei Lin, Xinhao Wang, Yongtao Wang, Yun Xing, Shengxiang Qi, Nan Dong, Ming-Hsuan Yang
Three-dimensional perception from multi-view cameras is a crucial component in autonomous driving systems, which involves multiple tasks like 3D object detection and bird's-eye-view (BEV) semantic segmentation. To improve perception precision, large image encoders, high-resolution images, and long-term temporal inputs have been adopted in recent 3D perception models, bringing remarkable performance gains. However, these techniques are often incompatible in training and inference scenarios due to computational resource constraints. Besides, modern autonomous driving systems prefer to adopt an end-to-end framework for multi-task 3D perception, which can simplify the overall system architecture and reduce the implementation complexity. However, conflict between tasks often arises when optimizing multiple tasks jointly within an end-to-end 3D perception model. To alleviate these issues, we present an end-to-end framework named HENet for multi-task 3D perception in this paper. Specifically, we propose a hybrid image encoding network, using a large image encoder for short-term frames and a small image encoder for long-term temporal frames. Then, we introduce a temporal feature integration module based on the attention mechanism to fuse the features of different frames extracted by the two aforementioned hybrid image encoders. Finally, according to the characteristics of each perception task, we utilize BEV features of different grid sizes, independent BEV encoders, and task decoders for different tasks. Experimental results show that HENet achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, including 3D object detection and BEV semantic segmentation. The source code and models will be released at https://github.com/VDIGPKU/HENet.
Read more5/21/2024

0
Exploring Camera Encoder Designs for Autonomous Driving Perception
Barath Lakshmanan, Joshua Chen, Shiyi Lan, Maying Shen, Zhiding Yu, Jose M. Alvarez
The cornerstone of autonomous vehicles (AV) is a solid perception system, where camera encoders play a crucial role. Existing works usually leverage pre-trained Convolutional Neural Networks (CNN) or Vision Transformers (ViTs) designed for general vision tasks, such as image classification, segmentation, and 2D detection. Although those well-known architectures have achieved state-of-the-art accuracy in AV-related tasks, e.g., 3D Object Detection, there remains significant potential for improvement in network design due to the nuanced complexities of industrial-level AV dataset. Moreover, existing public AV benchmarks usually contain insufficient data, which might lead to inaccurate evaluation of those architectures.To reveal the AV-specific model insights, we start from a standard general-purpose encoder, ConvNeXt and progressively transform the design. We adjust different design parameters including width and depth of the model, stage compute ratio, attention mechanisms, and input resolution, supported by systematic analysis to each modifications. This customization yields an architecture optimized for AV camera encoder achieving 8.79% mAP improvement over the baseline. We believe our effort could become a sweet cookbook of image encoders for AV and pave the way to the next-level drive system.
Read more7/11/2024
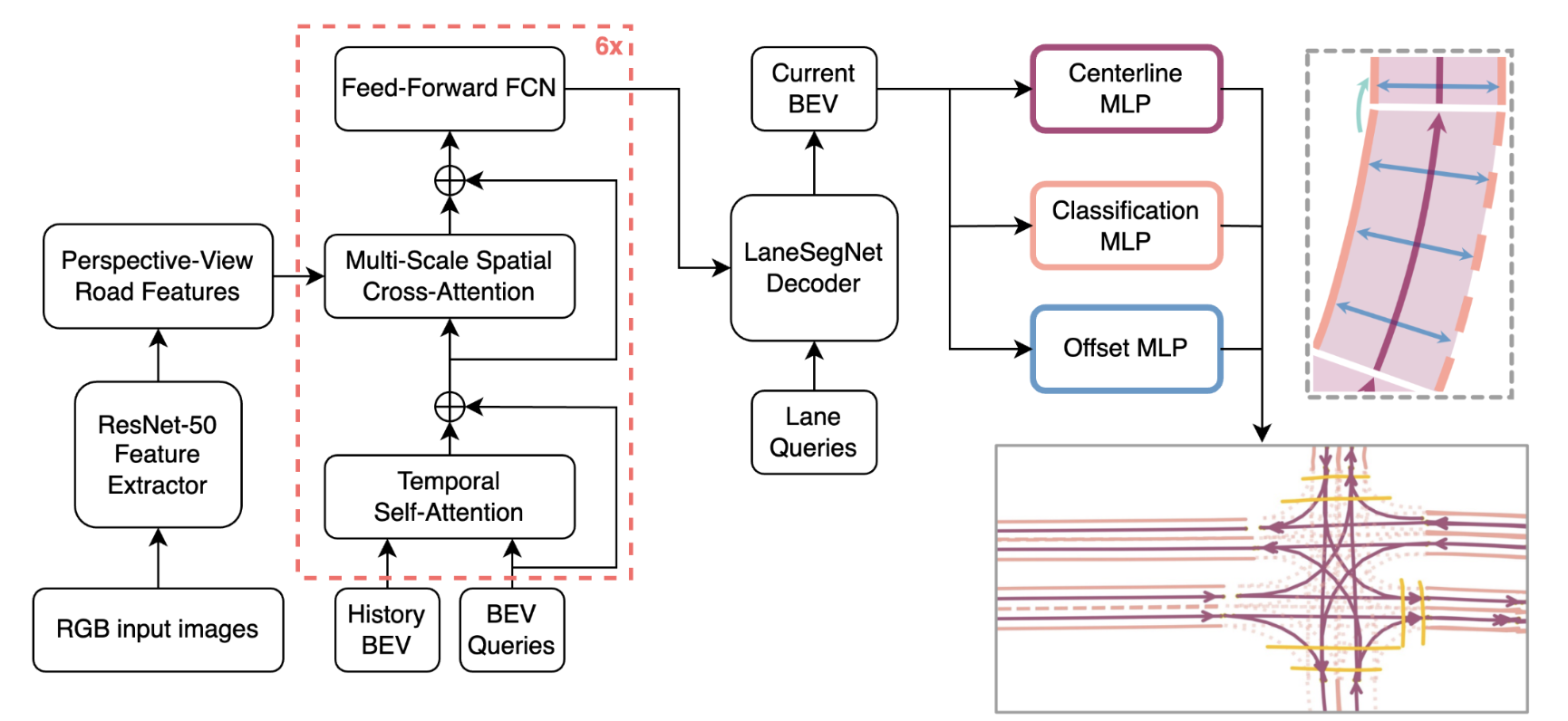
0
LaneSegNet Design Study
William Stevens, Vishal Urs, Karthik Selvaraj, Gabriel Torres, Gaurish Lakhanpal
With the increasing prevalence of autonomous vehicles, it is essential for computer vision algorithms to accurately assess road features in real-time. This study explores the LaneSegNet architecture, a new approach to lane topology prediction which integrates topological information with lane-line data to provide a more contextual understanding of road environments. The LaneSegNet architecture includes a feature extractor, lane encoder, lane decoder, and prediction head, leveraging components from ResNet-50, BEVFormer, and various attention mechanisms. We experimented with optimizations to the LaneSegNet architecture through feature extractor modification and transformer encoder-decoder stack modification. We found that modifying the encoder and decoder stacks offered an interesting tradeoff between training time and prediction accuracy, with certain combinations showing promising results. Our implementation, trained on a single NVIDIA Tesla A100 GPU, found that a 2:4 ratio reduced training time by 22.3% with only a 7.1% drop in mean average precision, while a 4:8 ratio increased training time by only 11.1% but improved mean average precision by a significant 23.7%. These results indicate that strategic hyperparameter tuning can yield substantial improvements depending on the resources of the user. This study provides valuable insights for optimizing LaneSegNet according to available computation power, making it more accessible for users with limited resources and increasing the capabilities for users with more powerful resources.
Read more8/1/2024