LaneSegNet Design Study

0
Sign in to get full access
Overview
- The paper presents a design study for LaneSegNet, a deep learning model for lane segmentation in autonomous driving applications.
- It was developed by researchers at the Image Processing and Analysis Lab at Purdue University in West Lafayette, Indiana.
- The study was conducted in May 2024 and explores the architecture and performance of LaneSegNet.
Plain English Explanation
LaneSegNet is a machine learning model designed to help self-driving cars detect and identify the lanes on the road. This is an important capability for autonomous vehicles, as it allows them to stay centered in their lane and navigate safely.
The researchers at Purdue University developed LaneSegNet as part of their ongoing work in the field of computer vision and image processing. They wanted to create a model that could accurately segment lane markings from camera images, even in challenging conditions like poor lighting or obstructed views.
To do this, LaneSegNet uses a deep neural network architecture that takes in raw image data and outputs a segmented map of the lane boundaries. The model is trained on a large dataset of real-world driving scenes, allowing it to learn the visual patterns and features that distinguish lanes from other road elements.
The key innovation of LaneSegNet is [its architecture, which builds on previous work in areas like TED-Net, Structure-Aware Lane Graph Transformer, and ENet-21]. By incorporating insights from these related models, the researchers were able to create a lane segmentation system that is both accurate and computationally efficient, making it well-suited for real-time deployment in autonomous vehicles.
Technical Explanation
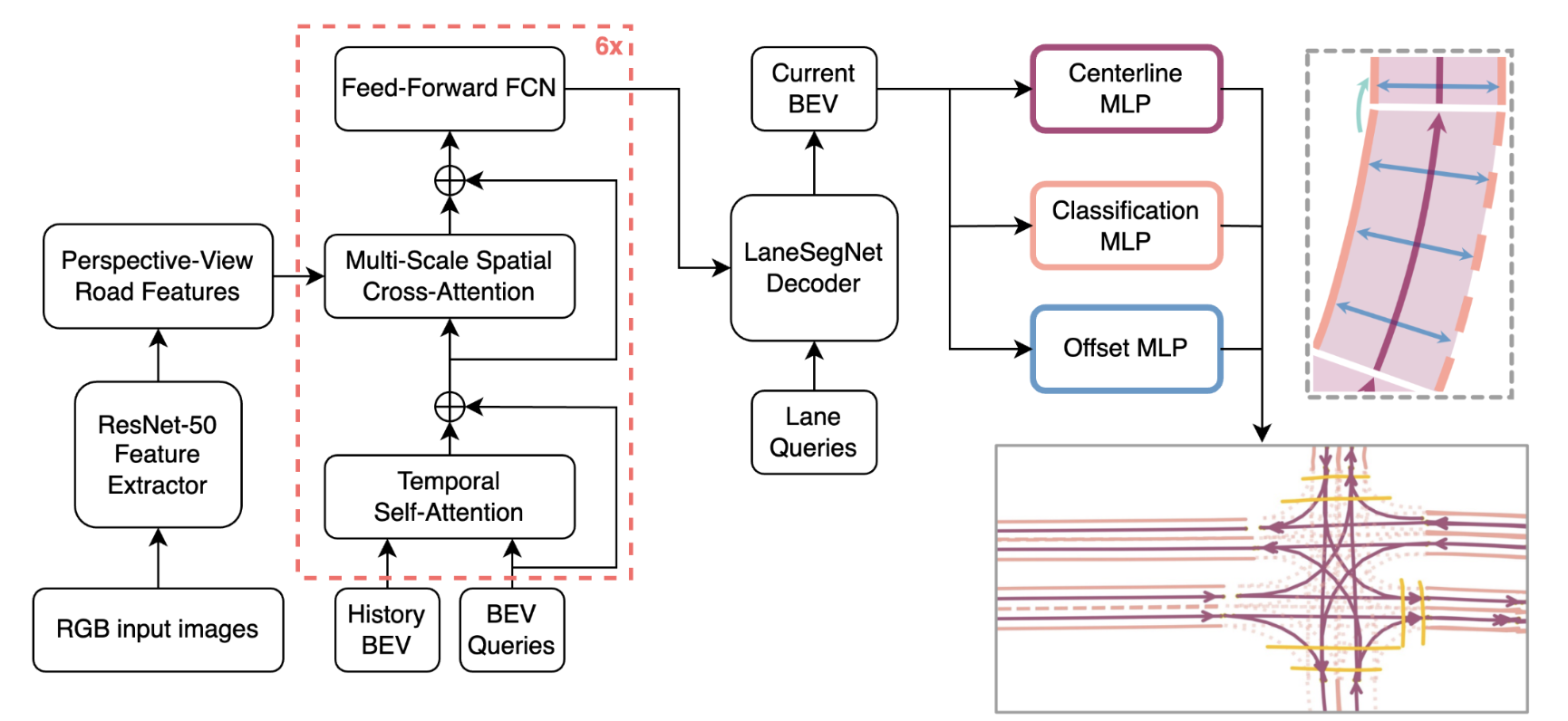
The core of LaneSegNet is a convolutional neural network (CNN) architecture that takes in a raw camera image and outputs a segmented map of the lane boundaries. The network consists of an encoder module that extracts visual features from the input, and a decoder module that translates these features into a lane segmentation map.
To enhance the model's performance, the researchers incorporated several key design elements:
-
Attention Mechanisms: LaneSegNet leverages graph attention networks to selectively focus on the most relevant visual features for lane segmentation, improving the model's ability to handle complex road scenes.
-
Encoder-Decoder Refinement: The network's encoder-decoder structure is further optimized through enhanced encoder-decoder architectures that reduce information loss and improve the quality of the final lane segmentation output.
-
Lightweight Design: To enable real-time inference on embedded systems, the researchers designed LaneSegNet to be computationally efficient, with a focus on reducing the model's parameter count and inference latency.
The researchers evaluated LaneSegNet's performance on several benchmark datasets for lane segmentation, comparing it to state-of-the-art approaches. Their results demonstrated that LaneSegNet achieves high accuracy while maintaining low computational requirements, making it a promising candidate for deployment in autonomous driving systems.
Critical Analysis
The design study on LaneSegNet provides a valuable contribution to the field of lane segmentation for autonomous vehicles. The researchers have clearly put a lot of thought and care into the model's architecture, drawing on the latest advancements in deep learning and computer vision.
One potential limitation of the study is the lack of real-world testing and validation of LaneSegNet. While the model's performance on benchmark datasets is promising, it would be helpful to see how it fares in actual driving scenarios, where environmental factors like weather, lighting, and road conditions can introduce additional challenges.
Additionally, the study does not delve into the model's robustness to adversarial attacks or its ability to generalize to unseen driving conditions. These are important considerations for safety-critical applications like autonomous driving, and further research in these areas could strengthen the case for LaneSegNet's deployment.
Overall, the LaneSegNet design study demonstrates the researchers' deep understanding of the problem and their ability to leverage state-of-the-art techniques to create a highly effective lane segmentation solution. As autonomous driving technology continues to evolve, contributions like this will be crucial in ensuring the safety and reliability of self-driving cars on our roads.
Conclusion
The LaneSegNet design study presents a novel deep learning model for accurate and efficient lane segmentation in autonomous driving applications. By drawing on the latest advancements in computer vision and deep learning, the researchers at Purdue University have developed a system that can accurately detect and identify lane boundaries, even in complex road scenes.
The key innovations of LaneSegNet, such as its attention mechanisms, encoder-decoder refinement, and lightweight design, make it a promising candidate for real-world deployment in self-driving cars. As the field of autonomous driving continues to evolve, research like this will play a crucial role in ensuring the safety and reliability of these systems, ultimately paving the way for a more sustainable and accessible transportation future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LaneSegNet Design Study
William Stevens, Vishal Urs, Karthik Selvaraj, Gabriel Torres, Gaurish Lakhanpal
With the increasing prevalence of autonomous vehicles, it is essential for computer vision algorithms to accurately assess road features in real-time. This study explores the LaneSegNet architecture, a new approach to lane topology prediction which integrates topological information with lane-line data to provide a more contextual understanding of road environments. The LaneSegNet architecture includes a feature extractor, lane encoder, lane decoder, and prediction head, leveraging components from ResNet-50, BEVFormer, and various attention mechanisms. We experimented with optimizations to the LaneSegNet architecture through feature extractor modification and transformer encoder-decoder stack modification. We found that modifying the encoder and decoder stacks offered an interesting tradeoff between training time and prediction accuracy, with certain combinations showing promising results. Our implementation, trained on a single NVIDIA Tesla A100 GPU, found that a 2:4 ratio reduced training time by 22.3% with only a 7.1% drop in mean average precision, while a 4:8 ratio increased training time by only 11.1% but improved mean average precision by a significant 23.7%. These results indicate that strategic hyperparameter tuning can yield substantial improvements depending on the resources of the user. This study provides valuable insights for optimizing LaneSegNet according to available computation power, making it more accessible for users with limited resources and increasing the capabilities for users with more powerful resources.
Read more8/1/2024

0
New!LMT-Net: Lane Model Transformer Network for Automated HD Mapping from Sparse Vehicle Observations
Michael Mink, Thomas Monninger, Steffen Staab
In autonomous driving, High Definition (HD) maps provide a complete lane model that is not limited by sensor range and occlusions. However, the generation and upkeep of HD maps involves periodic data collection and human annotations, limiting scalability. To address this, we investigate automating the lane model generation and the use of sparse vehicle observations instead of dense sensor measurements. For our approach, a pre-processing step generates polylines by aligning and aggregating observed lane boundaries. Aligned driven traces are used as starting points for predicting lane pairs defined by the left and right boundary points. We propose Lane Model Transformer Network (LMT-Net), an encoder-decoder neural network architecture that performs polyline encoding and predicts lane pairs and their connectivity. A lane graph is formed by using predicted lane pairs as nodes and predicted lane connectivity as edges. We evaluate the performance of LMT-Net on an internal dataset that consists of multiple vehicle observations as well as human annotations as Ground Truth (GT). The evaluation shows promising results and demonstrates superior performance compared to the implemented baseline on both highway and non-highway Operational Design Domain (ODD).
Read more9/20/2024

0
TEDNet: Twin Encoder Decoder Neural Network for 2D Camera and LiDAR Road Detection
Mart'in Bay'on-Guti'errez, Mar'ia Teresa Garc'ia-Ord'as, H'ector Alaiz Moret'on, Jose Aveleira-Mata, Sergio Rubio Mart'in, Jos'e Alberto Ben'itez-Andrades
Robust road surface estimation is required for autonomous ground vehicles to navigate safely. Despite it becoming one of the main targets for autonomous mobility researchers in recent years, it is still an open problem in which cameras and LiDAR sensors have demonstrated to be adequate to predict the position, size and shape of the road a vehicle is driving on in different environments. In this work, a novel Convolutional Neural Network model is proposed for the accurate estimation of the roadway surface. Furthermore, an ablation study has been conducted to investigate how different encoding strategies affect model performance, testing 6 slightly different neural network architectures. Our model is based on the use of a Twin Encoder-Decoder Neural Network (TEDNet) for independent camera and LiDAR feature extraction, and has been trained and evaluated on the Kitti-Road dataset. Bird's Eye View projections of the camera and LiDAR data are used in this model to perform semantic segmentation on whether each pixel belongs to the road surface. The proposed method performs among other state-of-the-art methods and operates at the same frame-rate as the LiDAR and cameras, so it is adequate for its use in real-time applications.
Read more5/15/2024
0
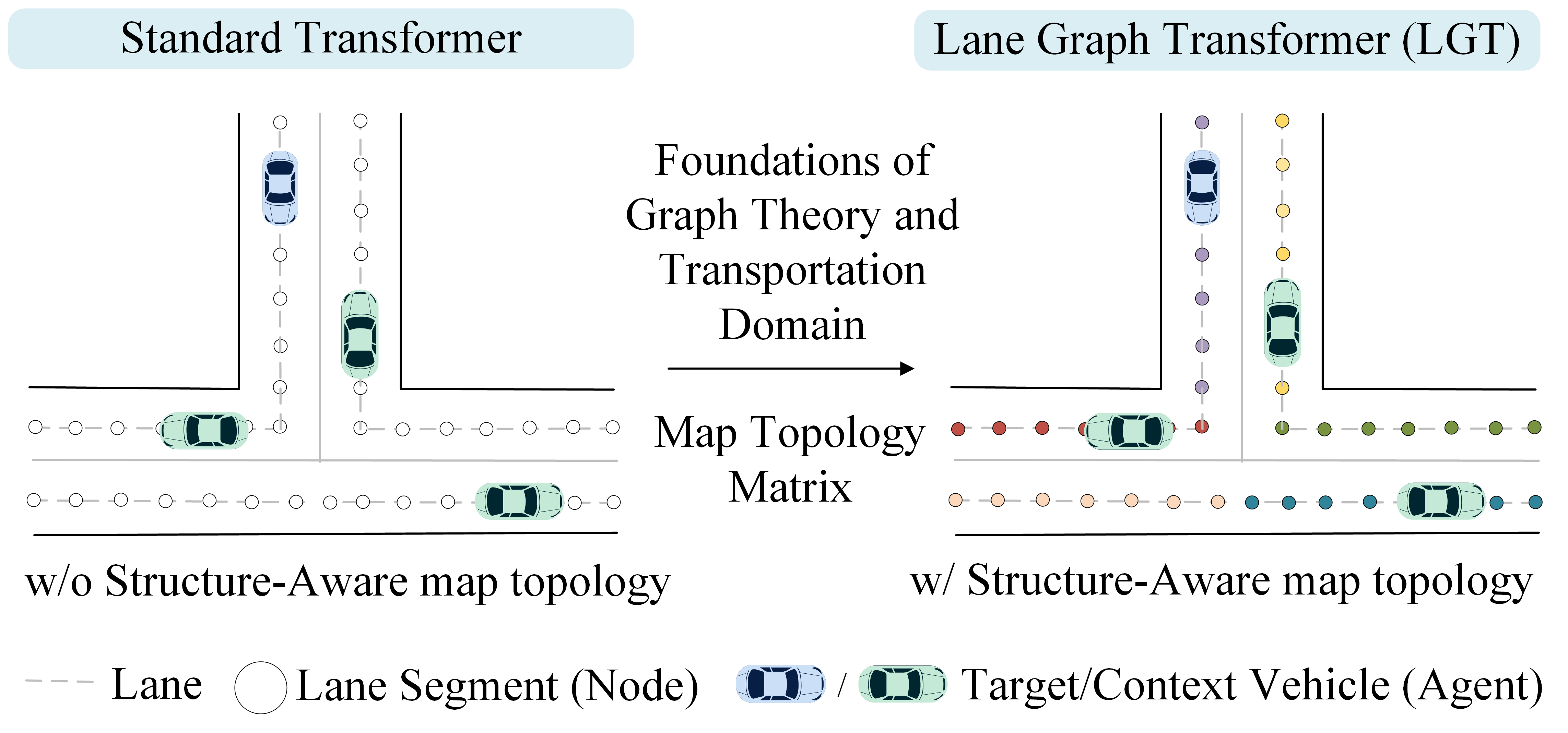
A Structure-Aware Lane Graph Transformer Model for Vehicle Trajectory Prediction
Sun Zhanbo, Dong Caiyin, Ji Ang, Zhao Ruibin, Zhao Yu
Accurate prediction of future trajectories for surrounding vehicles is vital for the safe operation of autonomous vehicles. This study proposes a Lane Graph Transformer (LGT) model with structure-aware capabilities. Its key contribution lies in encoding the map topology structure into the attention mechanism. To address variations in lane information from different directions, four Relative Positional Encoding (RPE) matrices are introduced to capture the local details of the map topology structure. Additionally, two Shortest Path Distance (SPD) matrices are employed to capture distance information between two accessible lanes. Numerical results indicate that the proposed LGT model achieves a significantly higher prediction performance on the Argoverse 2 dataset. Specifically, the minFDE$_6$ metric was decreased by 60.73% compared to the Argoverse 2 baseline model (Nearest Neighbor) and the b-minFDE$_6$ metric was reduced by 2.65% compared to the baseline LaneGCN model. Furthermore, ablation experiments demonstrated that the consideration of map topology structure led to a 4.24% drop in the b-minFDE$_6$ metric, validating the effectiveness of this model.
Read more5/31/2024