A Human-in-the-Loop Approach to Improving Cross-Text Prosody Transfer
2406.06601
0
0

Abstract
Text-To-Speech (TTS) prosody transfer models can generate varied prosodic renditions, for the same text, by conditioning on a reference utterance. These models are trained with a reference that is identical to the target utterance. But when the reference utterance differs from the target text, as in cross-text prosody transfer, these models struggle to separate prosody from text, resulting in reduced perceived naturalness. To address this, we propose a Human-in-the-Loop (HitL) approach. HitL users adjust salient correlates of prosody to make the prosody more appropriate for the target text, while maintaining the overall reference prosodic effect. Human adjusted renditions maintain the reference prosody while being rated as more appropriate for the target text $57.8%$ of the time. Our analysis suggests that limited user effort suffices for these improvements, and that closeness in the latent reference space is not a reliable prosodic similarity metric for the cross-text condition.
Create account to get full access
Overview
- This paper presents a human-in-the-loop approach to improving cross-text prosody transfer, a task in text-to-speech synthesis where the prosody (i.e., rhythm, stress, and intonation) from one speech sample is transferred to another text input.
- The authors argue that current prosody transfer models struggle with maintaining consistent prosody across different text inputs, and propose a system that allows human annotators to provide feedback to iteratively refine the model's performance.
- The paper explores the use of contrastive learning and multi-modal pre-training techniques to enhance the model's ability to capture and transfer prosodic features.
Plain English Explanation
The paper focuses on a problem in text-to-speech (TTS) synthesis called "cross-text prosody transfer." This means taking the way a person speaks (their "prosody" - things like rhythm, stress, and intonation) and applying it to a different piece of text.
Current TTS models often struggle to maintain consistent prosody when transferring it across different text inputs. To address this, the researchers developed a system that allows human annotators to provide feedback to the model, helping it learn how to better capture and transfer prosodic features.
The key ideas are:
-
Use "contrastive learning" - training the model to not only learn the target prosody, but also learn what the prosody is not, by comparing positive and negative examples.
-
Use "multi-modal pre-training" - train the model on not just text, but also audio and other related data, to help it better understand prosody.
-
Get human feedback to iteratively improve the model's performance, rather than just relying on the model to learn on its own.
By incorporating these techniques, the researchers aimed to create a TTS system that can more reliably apply a person's speaking style to different text inputs, which could be useful for applications like audiobook narration or voice cloning.
Technical Explanation
The paper presents a "human-in-the-loop" approach to improving cross-text prosody transfer, a task in text-to-speech (TTS) synthesis where the prosodic features (rhythm, stress, intonation) from one speech sample are transferred to a different text input.
The key elements of the proposed system are:
-
Contrastive learning: The model is trained not just on positive examples of the target prosody, but also on negative examples where the prosody does not match. This helps the model learn a more robust representation of prosodic features.
-
Multi-modal pre-training: In addition to text data, the model is pre-trained on audio data and other related modalities, to better capture the relationship between linguistic and acoustic prosodic features.
-
Human-in-the-loop refinement: The model's output is presented to human annotators, who provide feedback on the prosody transfer quality. This feedback is then used to fine-tune the model, iteratively improving its performance.
The authors evaluate their approach on both objective prosody transfer metrics and subjective human evaluations, demonstrating improvements over prior state-of-the-art models. They also analyze the impact of the different components (contrastive learning, multi-modal pre-training, human feedback) on the model's performance.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of maintaining consistent prosody transfer in TTS systems. The incorporation of contrastive learning and multi-modal pre-training techniques is a thoughtful way to enhance the model's ability to capture and apply prosodic features.
However, the paper does not delve into some potential limitations or areas for further research. For example, the human feedback process is not described in detail, and it's unclear how scalable or practical this approach would be for real-world deployment. Additionally, the paper does not address potential biases or fairness issues that could arise from relying on human annotators to guide the model's learning.
Further research could explore ways to make the human-in-the-loop process more efficient and automated, or to incorporate techniques like active learning to better target the model's weaknesses. Investigating the cross-lingual or cross-cultural applicability of the approach could also be valuable, as prosody can vary significantly across different languages and speaking styles.
Overall, this paper presents an interesting and promising direction for improving prosody transfer in TTS, but there are still opportunities to further refine and expand upon the proposed techniques.
Conclusion
This paper introduces a human-in-the-loop approach to improving cross-text prosody transfer in text-to-speech synthesis. By incorporating contrastive learning, multi-modal pre-training, and iterative refinement based on human feedback, the authors demonstrate improvements over prior state-of-the-art models.
The key ideas of this work could have significant implications for the development of more natural and expressive TTS systems, which could in turn enhance applications like audiobook narration, voice cloning, and conversational interfaces. However, further research is needed to address potential limitations and scaling challenges.
Overall, this paper represents an important step forward in the quest to create TTS systems that can more reliably and consistently apply a speaker's unique prosodic patterns to different text inputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Controllable Prosody Generation With Partial Inputs
Dan Andrei Iliescu, Devang Savita Ram Mohan, Tian Huey Teh, Zack Hodari
0
0
We address the problem of human-in-the-loop control for generating prosody in the context of text-to-speech synthesis. Controlling prosody is challenging because existing generative models lack an efficient interface through which users can modify the output quickly and precisely. To solve this, we introduce a novel framework whereby the user provides partial inputs and the generative model generates the missing features. We propose a model that is specifically designed to encode partial prosodic features and output complete audio. We show empirically that our model displays two essential qualities of a human-in-the-loop control mechanism: efficiency and robustness. With even a very small number of input values (~4), our model enables users to improve the quality of the output significantly in terms of listener preference (4:1).
4/17/2024
Multilingual Prosody Transfer: Comparing Supervised & Transfer Learning
Arnav Goel, Medha Hira, Anubha Gupta
0
0
The field of prosody transfer in speech synthesis systems is rapidly advancing. This research is focused on evaluating learning methods for adapting pre-trained monolingual text-to-speech (TTS) models to multilingual conditions, i.e., Supervised Fine-Tuning (SFT) and Transfer Learning (TL). This comparison utilizes three distinct metrics: Mean Opinion Score (MOS), Recognition Accuracy (RA), and Mel Cepstral Distortion (MCD). Results demonstrate that, in comparison to SFT, TL leads to significantly enhanced performance, with an average MOS higher by 1.53 points, a 37.5% increase in RA, and approximately a 7.8-point improvement in MCD. These findings are instrumental in helping build TTS models for low-resource languages.
6/19/2024
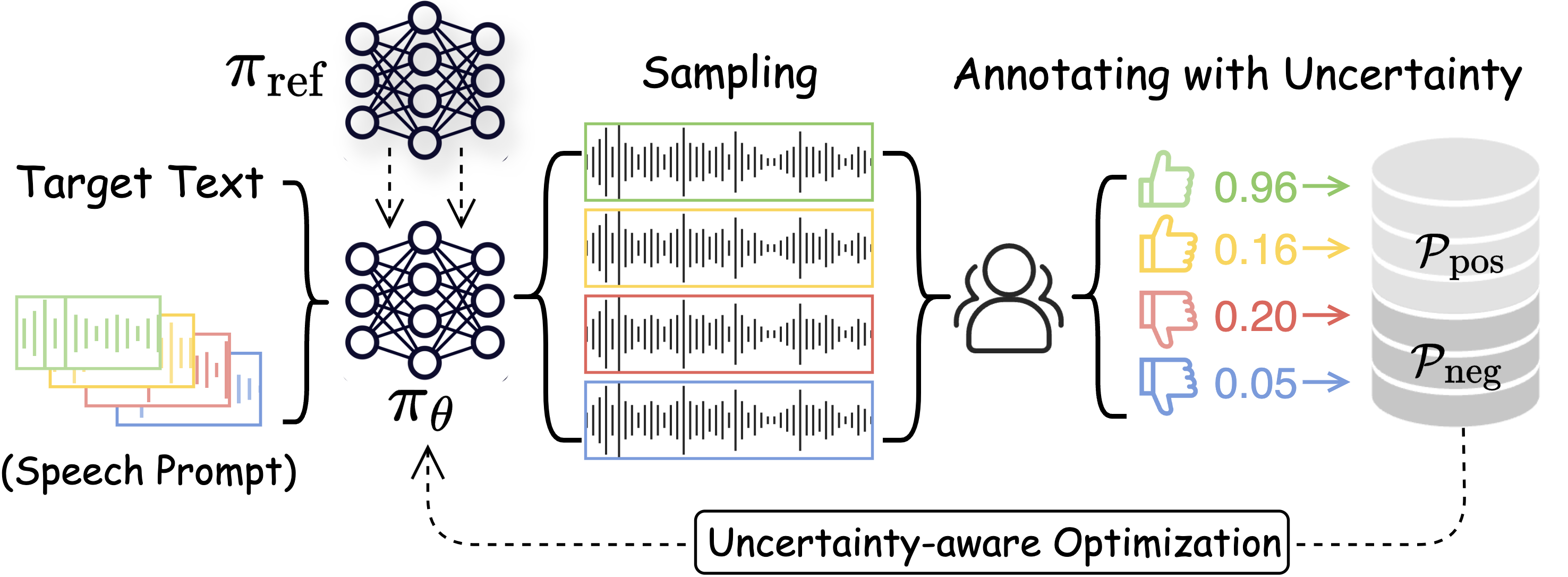
Enhancing Zero-shot Text-to-Speech Synthesis with Human Feedback
Chen Chen, Yuchen Hu, Wen Wu, Helin Wang, Eng Siong Chng, Chao Zhang
0
0
In recent years, text-to-speech (TTS) technology has witnessed impressive advancements, particularly with large-scale training datasets, showcasing human-level speech quality and impressive zero-shot capabilities on unseen speakers. However, despite human subjective evaluations, such as the mean opinion score (MOS), remaining the gold standard for assessing the quality of synthetic speech, even state-of-the-art TTS approaches have kept human feedback isolated from training that resulted in mismatched training objectives and evaluation metrics. In this work, we investigate a novel topic of integrating subjective human evaluation into the TTS training loop. Inspired by the recent success of reinforcement learning from human feedback, we propose a comprehensive sampling-annotating-learning framework tailored to TTS optimization, namely uncertainty-aware optimization (UNO). Specifically, UNO eliminates the need for a reward model or preference data by directly maximizing the utility of speech generations while considering the uncertainty that lies in the inherent variability in subjective human speech perception and evaluations. Experimental results of both subjective and objective evaluations demonstrate that UNO considerably improves the zero-shot performance of TTS models in terms of MOS, word error rate, and speaker similarity. Additionally, we present a remarkable ability of UNO that it can adapt to the desired speaking style in emotional TTS seamlessly and flexibly.
6/4/2024
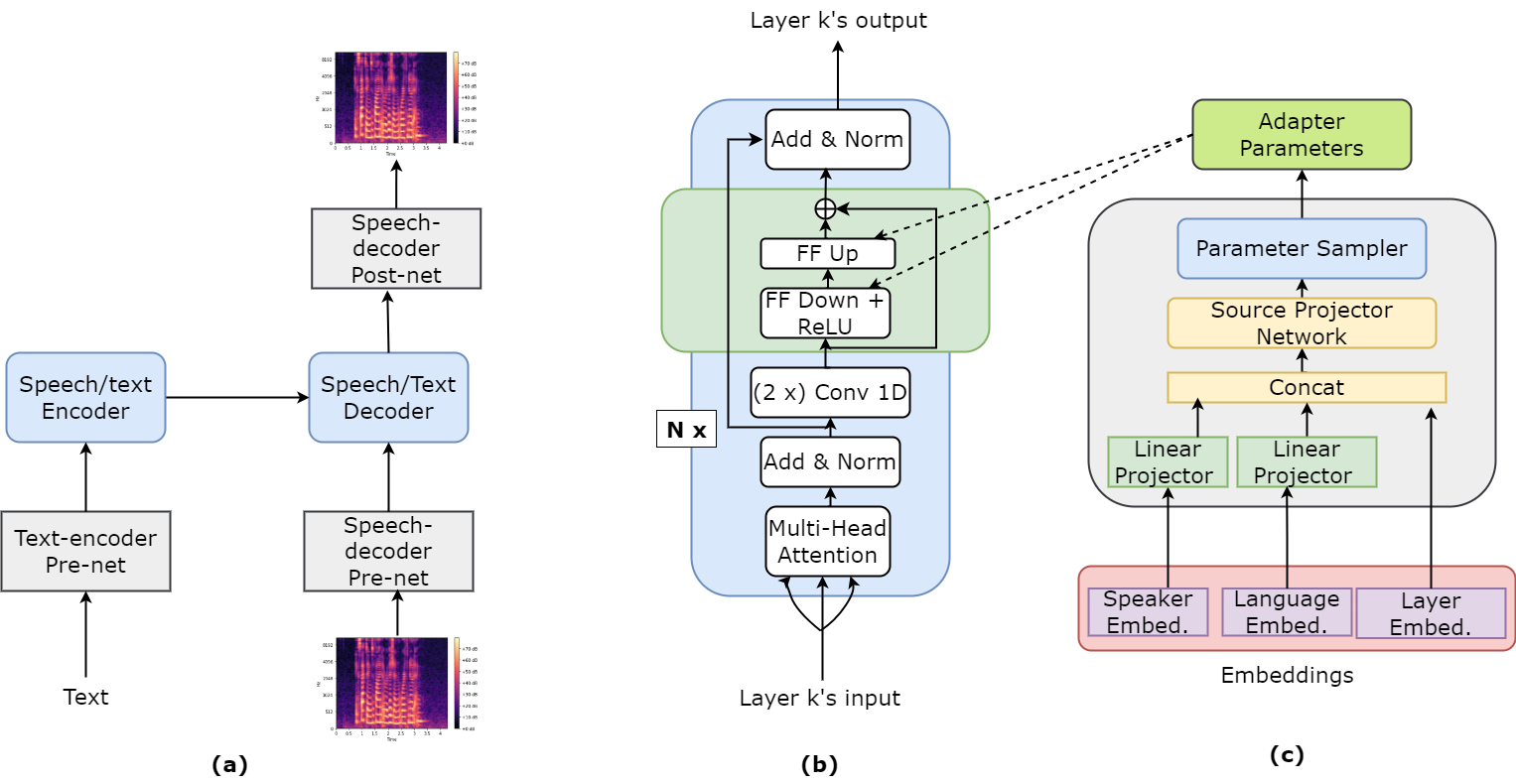
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
0
0
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
6/26/2024