Controllable Prosody Generation With Partial Inputs
2303.09446
0
0
🛸
Abstract
We address the problem of human-in-the-loop control for generating prosody in the context of text-to-speech synthesis. Controlling prosody is challenging because existing generative models lack an efficient interface through which users can modify the output quickly and precisely. To solve this, we introduce a novel framework whereby the user provides partial inputs and the generative model generates the missing features. We propose a model that is specifically designed to encode partial prosodic features and output complete audio. We show empirically that our model displays two essential qualities of a human-in-the-loop control mechanism: efficiency and robustness. With even a very small number of input values (~4), our model enables users to improve the quality of the output significantly in terms of listener preference (4:1).
Create account to get full access
Overview
- Addresses the challenge of human-in-the-loop control for generating prosody in text-to-speech synthesis
- Proposes a novel framework where the user provides partial inputs and the generative model generates the missing features
- Demonstrates the model's efficiency and robustness in enabling users to significantly improve output quality with minimal input
Plain English Explanation
Controlling the rhythm, stress, and intonation (prosody) of synthesized speech is a difficult task. Existing models struggle to provide an efficient way for users to quickly and precisely modify the output. This paper introduces a new approach to solve this problem.
The key idea is to let users provide partial information about the desired prosody, and then have the model fill in the missing details. For example, the user might specify the overall rhythm and stress pattern, and the model would generate the corresponding audio.
The researchers show that their model has two important qualities for human-in-the-loop control: efficiency and robustness. Even with just a small amount of user input (around 4 values), the model can significantly improve the quality of the synthesized speech, as measured by listener preference.
This work represents an important step towards giving users more control over the expressive qualities of text-to-speech systems, which could lead to more natural and personalized speech synthesis.
Technical Explanation
The researchers propose a novel framework for human-in-the-loop control of prosody in text-to-speech synthesis. The key innovation is a model that can encode partial prosodic features provided by the user and generate the corresponding complete audio output.
Specifically, the model takes as input a set of prosodic features (e.g., rhythm, stress, intonation) where some values are specified by the user and others are left unspecified. The model is trained to learn the relationships between these prosodic features and the resulting audio, allowing it to fill in the missing values.
Through experiments, the researchers demonstrate that their model displays two essential qualities of an effective human-in-the-loop system: efficiency and robustness. Even with a very small number of user-provided inputs (around 4), the model can significantly improve the quality of the synthesized speech, as measured by listener preference.
This work represents an important step towards giving users more granular control over the expressive qualities of text-to-speech systems, which could lead to more natural and personalized speech synthesis.
Critical Analysis
The paper presents a promising approach to human-in-the-loop prosody control, but there are a few caveats and areas for further research:
-
The experiments were conducted on a relatively small dataset, so it would be important to validate the model's performance on a larger and more diverse set of speech samples.
-
The paper does not provide much detail on the model architecture or training process, making it difficult to fully assess the technical merits of the approach.
-
The evaluation focused on listener preference, but it would be valuable to also examine more objective measures of prosody quality, such as voice naturalness or intelligibility.
-
The paper does not address the potential challenges of scaling this approach to larger language models or integrating it with other prosody control techniques.
Overall, this research represents an interesting step forward, but further work is needed to fully assess the practicality and generalizability of the proposed framework.
Conclusion
This paper addresses the important challenge of enabling users to efficiently control the prosody of synthesized speech. The proposed framework allows users to provide partial inputs, which the model then uses to generate complete and high-quality audio output. The researchers demonstrate the efficiency and robustness of their approach, showing that even minimal user input can significantly improve the listener preference of the synthesized speech.
While the paper has some limitations, this work represents an important step towards giving users more fine-grained control over the expressive qualities of text-to-speech systems, which could lead to more natural and personalized speech synthesis. Further research in this direction could have significant implications for a wide range of applications, from assistive technology to audio production and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
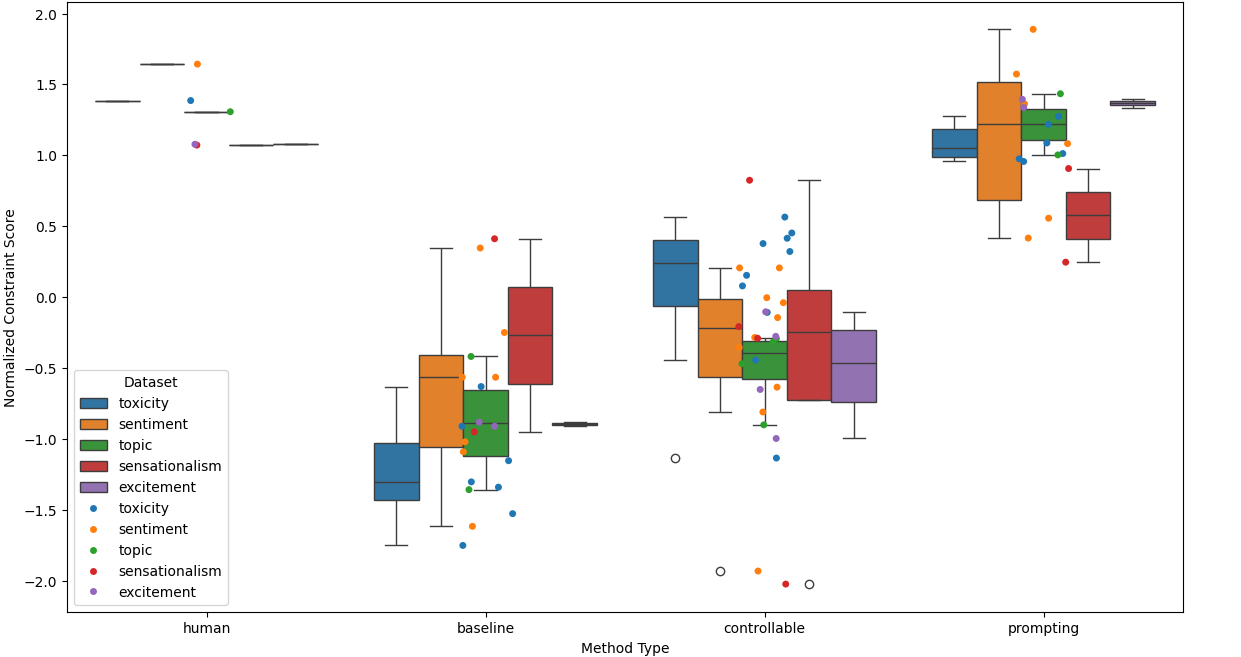
Controllable Text Generation in the Instruction-Tuning Era
Dhananjay Ashok, Barnabas Poczos
0
0
While most research on controllable text generation has focused on steering base Language Models, the emerging instruction-tuning and prompting paradigm offers an alternate approach to controllability. We compile and release ConGenBench, a testbed of 17 different controllable generation tasks, using a subset of it to benchmark the performance of 9 different baselines and methods on Instruction-tuned Language Models. To our surprise, we find that prompting-based approaches outperform controllable text generation methods on most datasets and tasks, highlighting a need for research on controllable text generation with Instruction-tuned Language Models in specific. Prompt-based approaches match human performance on most stylistic tasks while lagging on structural tasks, foregrounding a need to study more varied constraints and more challenging stylistic tasks. To facilitate such research, we provide an algorithm that uses only a task dataset and a Large Language Model with in-context capabilities to automatically generate a constraint dataset. This method eliminates the fields dependence on pre-curated constraint datasets, hence vastly expanding the range of constraints that can be studied in the future.
5/3/2024

A Human-in-the-Loop Approach to Improving Cross-Text Prosody Transfer
Himanshu Maurya, Atli Sigurgeirsson
0
0
Text-To-Speech (TTS) prosody transfer models can generate varied prosodic renditions, for the same text, by conditioning on a reference utterance. These models are trained with a reference that is identical to the target utterance. But when the reference utterance differs from the target text, as in cross-text prosody transfer, these models struggle to separate prosody from text, resulting in reduced perceived naturalness. To address this, we propose a Human-in-the-Loop (HitL) approach. HitL users adjust salient correlates of prosody to make the prosody more appropriate for the target text, while maintaining the overall reference prosodic effect. Human adjusted renditions maintain the reference prosody while being rated as more appropriate for the target text $57.8%$ of the time. Our analysis suggests that limited user effort suffices for these improvements, and that closeness in the latent reference space is not a reliable prosodic similarity metric for the cross-text condition.
6/12/2024

Controllable Talking Face Generation by Implicit Facial Keypoints Editing
Dong Zhao, Jiaying Shi, Wenjun Li, Shudong Wang, Shenghui Xu, Zhaoming Pan
0
0
Audio-driven talking face generation has garnered significant interest within the domain of digital human research. Existing methods are encumbered by intricate model architectures that are intricately dependent on each other, complicating the process of re-editing image or video inputs. In this work, we present ControlTalk, a talking face generation method to control face expression deformation based on driven audio, which can construct the head pose and facial expression including lip motion for both single image or sequential video inputs in a unified manner. By utilizing a pre-trained video synthesis renderer and proposing the lightweight adaptation, ControlTalk achieves precise and naturalistic lip synchronization while enabling quantitative control over mouth opening shape. Our experiments show that our method is superior to state-of-the-art performance on widely used benchmarks, including HDTF and MEAD. The parameterized adaptation demonstrates remarkable generalization capabilities, effectively handling expression deformation across same-ID and cross-ID scenarios, and extending its utility to out-of-domain portraits, regardless of languages.
6/6/2024

ControlSpeech: Towards Simultaneous Zero-shot Speaker Cloning and Zero-shot Language Style Control With Decoupled Codec
Shengpeng Ji, Jialong Zuo, Minghui Fang, Siqi Zheng, Qian Chen, Wen Wang, Ziyue Jiang, Hai Huang, Xize Cheng, Rongjie Huang, Zhou Zhao
0
0
In this paper, we present ControlSpeech, a text-to-speech (TTS) system capable of fully cloning the speaker's voice and enabling arbitrary control and adjustment of speaking style, merely based on a few seconds of audio prompt and a simple textual style description prompt. Prior zero-shot TTS models and controllable TTS models either could only mimic the speaker's voice without further control and adjustment capabilities or were unrelated to speaker-specific voice generation. Therefore, ControlSpeech focuses on a more challenging new task-a TTS system with controllable timbre, content, and style at the same time. ControlSpeech takes speech prompts, content prompts, and style prompts as inputs and utilizes bidirectional attention and mask-based parallel decoding to capture corresponding codec representations in a discrete decoupling codec space. Moreover, we discovered the issue of text style controllability in a many-to-many mapping fashion and proposed the Style Mixture Semantic Density (SMSD) model to resolve this problem. SMSD module which is based on Gaussian mixture density networks, is designed to enhance the fine-grained partitioning and sampling capabilities of style semantic information and generate speech with more diverse styles. In terms of experiments, we make available a controllable model toolkit called ControlToolkit with a new style controllable dataset, some replicated baseline models and propose new metrics to evaluate both the control capability and the quality of generated audio in ControlSpeech. The relevant ablation studies validate the necessity of each component in ControlSpeech is necessary. We hope that ControlSpeech can establish the next foundation paradigm of controllable speech synthesis. The relevant code and demo are available at https://github.com/jishengpeng/ControlSpeech .
6/4/2024