Multilingual Prosody Transfer: Comparing Supervised & Transfer Learning
2406.00022
0
0
Abstract
The field of prosody transfer in speech synthesis systems is rapidly advancing. This research is focused on evaluating learning methods for adapting pre-trained monolingual text-to-speech (TTS) models to multilingual conditions, i.e., Supervised Fine-Tuning (SFT) and Transfer Learning (TL). This comparison utilizes three distinct metrics: Mean Opinion Score (MOS), Recognition Accuracy (RA), and Mel Cepstral Distortion (MCD). Results demonstrate that, in comparison to SFT, TL leads to significantly enhanced performance, with an average MOS higher by 1.53 points, a 37.5% increase in RA, and approximately a 7.8-point improvement in MCD. These findings are instrumental in helping build TTS models for low-resource languages.
Create account to get full access
Overview
- This paper explores and compares two approaches for transferring prosody (the rhythm, stress, and intonation of speech) from one language to another in a text-to-speech (TTS) system.
- The first approach uses supervised learning, where the model is trained directly on paired source-target language audio data.
- The second approach uses transfer learning, where the model is first trained on a high-resource language and then fine-tuned on the target language.
- The researchers evaluate the performance of these two methods on several languages and examine the trade-offs between them.
Plain English Explanation
The paper is about how to make text-to-speech (TTS) systems that can preserve the prosody, or rhythm and intonation, of speech when translating between languages. The researchers tested two different approaches:
-
Supervised Learning: Training the model directly on pairs of audio recordings in the source and target languages. This allows the model to learn the specific prosody patterns for each language.
-
Transfer Learning: First training the model on a high-resource language (like English) with lots of data, and then fine-tuning it on the target language. This leverages the model's general understanding of prosody from the high-resource language.
The researchers compared the performance of these two approaches across multiple languages. They looked at the trade-offs, such as the amount of training data required and the quality of the resulting prosody transfer.
Technical Explanation
The paper explores two approaches for [object Object]:
-
Supervised Learning: The model is trained directly on paired source-target language audio data using a multilingual prosody prediction network. This allows the model to learn the specific prosody patterns for each language.
-
Transfer Learning: The model is first trained on a high-resource language (like English) using a [object Object] approach to learn general prosody representations. It is then fine-tuned on the target language data.
The researchers evaluate these approaches on [object Object] and analyze the trade-offs in terms of [object Object]. They also explore the use of [object Object] to further improve the prosody transfer.
Critical Analysis
The paper provides a comprehensive evaluation of the two approaches for multilingual prosody transfer, highlighting their respective strengths and weaknesses. However, the authors acknowledge that the performance of these methods may be influenced by the availability and quality of the training data, as well as the linguistic similarities between the source and target languages.
Additionally, the paper does not explore the potential impact of using different neural network architectures or training techniques beyond the two approaches presented. Further research could investigate the use of more advanced models or training strategies to enhance the prosody transfer capabilities.
The authors also note that the evaluation focuses on objective metrics, such as prosody similarity scores, but does not extensively cover the subjective user experience or perceived naturalness of the generated speech. Incorporating more human-centric evaluations could provide valuable insights into the practical applications of these techniques.
Conclusion
This paper provides a detailed comparison of supervised learning and transfer learning approaches for [object Object]. The findings suggest that both methods have their merits, with the transfer learning approach offering more efficient use of training data, while the supervised learning approach can potentially achieve better prosody transfer quality.
The insights from this research could inform the development of more robust and versatile TTS systems that can effectively preserve the natural rhythm and intonation of speech when translating between languages. This could have significant implications for improving the user experience and accessibility of multilingual voice-based applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
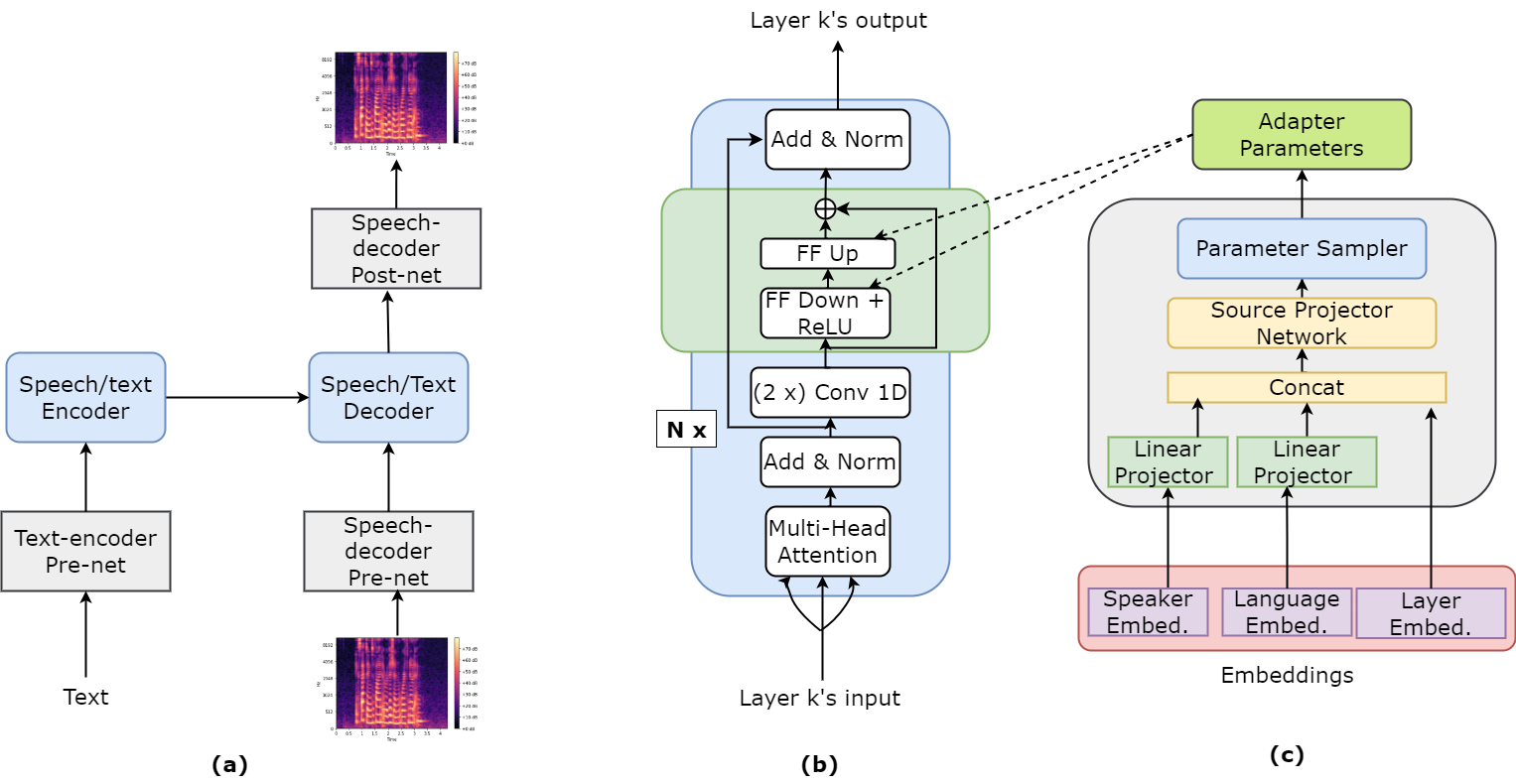
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
0
0
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
6/26/2024
CrossVoice: Crosslingual Prosody Preserving Cascade-S2ST using Transfer Learning
Medha Hira, Arnav Goel, Anubha Gupta
0
0
This paper presents CrossVoice, a novel cascade-based Speech-to-Speech Translation (S2ST) system employing advanced ASR, MT, and TTS technologies with cross-lingual prosody preservation through transfer learning. We conducted comprehensive experiments comparing CrossVoice with direct-S2ST systems, showing improved BLEU scores on tasks such as Fisher Es-En, VoxPopuli Fr-En and prosody preservation on benchmark datasets CVSS-T and IndicTTS. With an average mean opinion score of 3.75 out of 4, speech synthesized by CrossVoice closely rivals human speech on the benchmark, highlighting the efficacy of cascade-based systems and transfer learning in multilingual S2ST with prosody transfer.
6/19/2024
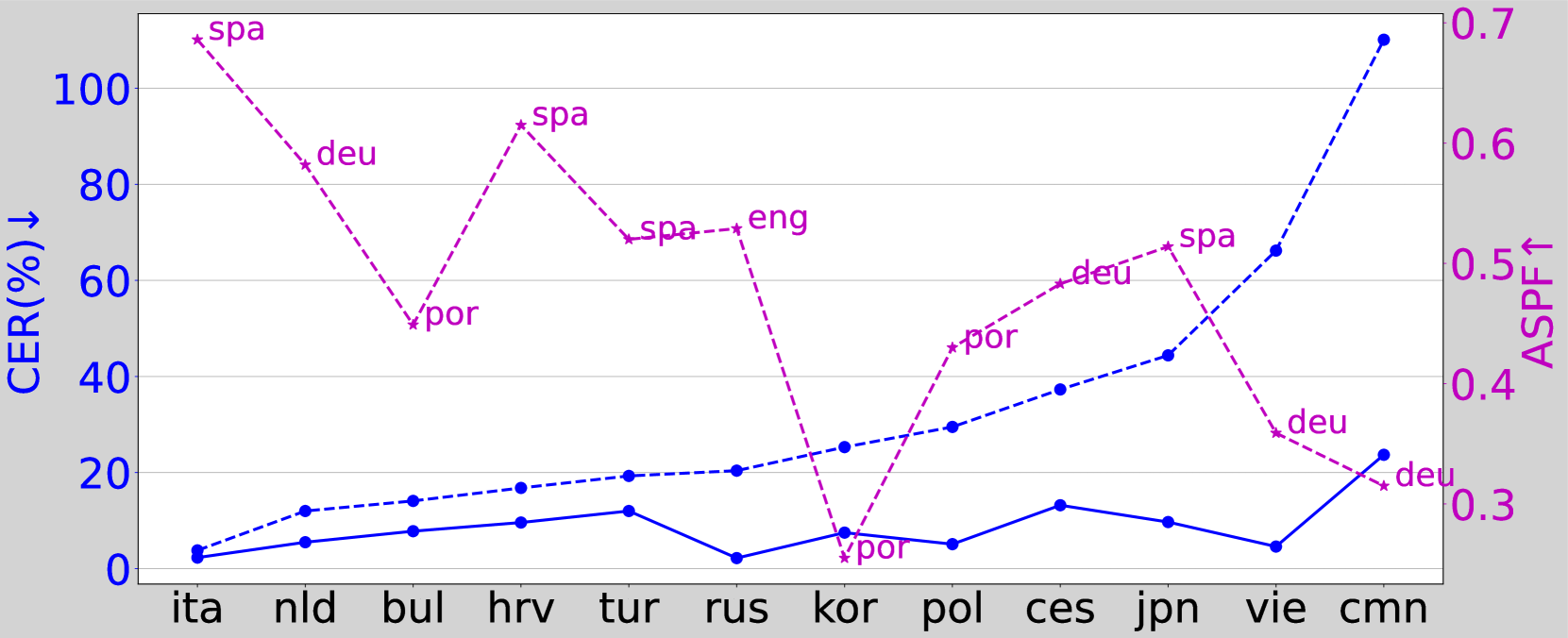
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Cheng Gong, Erica Cooper, Xin Wang, Chunyu Qiang, Mengzhe Geng, Dan Wells, Longbiao Wang, Jianwu Dang, Marc Tessier, Aidan Pine, Korin Richmond, Junichi Yamagishi
0
0
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
6/14/2024
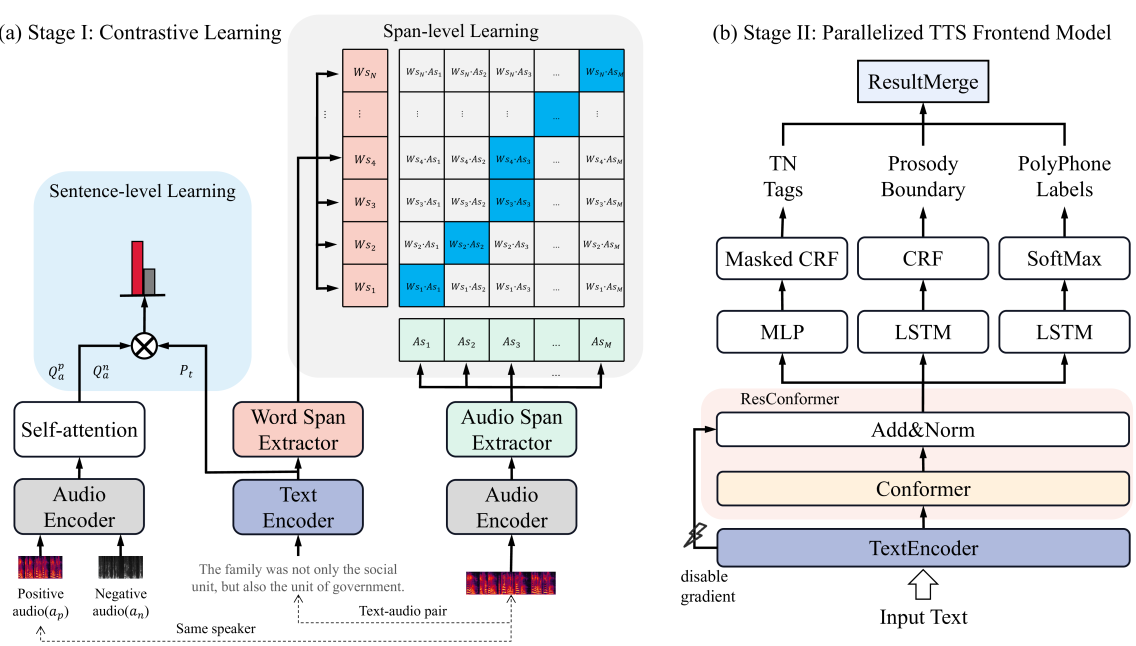
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Quanxiu Wang, Hui Huang, Mingjie Wang, Yong Dai, Jinzuomu Zhong, Benlai Tang
0
0
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
4/16/2024