Human Mesh Recovery from Arbitrary Multi-view Images
2403.12434
0
0

Abstract
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper presents a method for recovering 3D human mesh models from arbitrary multi-view images.
- The proposed approach uses a divide-and-conquer strategy to overcome the challenges of recovering 3D human mesh from diverse camera viewpoints.
- The method aims to be more robust and generalizable compared to previous work, which often relied on constrained camera setups or required additional information like 2D keypoints.
Plain English Explanation
The paper describes a way to create 3D models of people's bodies from a collection of regular photos taken from different angles. This is a challenging problem because people can be photographed from all sorts of viewpoints, and previous methods often required special cameras or extra information to work well.
The key idea in this paper is to break the problem down into smaller, more manageable pieces. Instead of trying to solve the whole 3D reconstruction task at once, the method divides it up and tackles each part separately. This "divide-and-conquer" strategy makes the problem easier to solve and leads to more accurate and robust 3D models.
The method starts by estimating the 3D pose of the person in each input image. It then uses that information to guide the reconstruction of the full 3D mesh of the person's body. By tackling the problem in this stepwise fashion, the approach is able to handle a wide variety of camera angles and viewpoints, without needing any special equipment or extra data beyond the input images.
This is an important advancement, as being able to capture accurate 3D models of people from everyday photos has many potential applications, such as virtual reality, fashion, and healthcare. The divide-and-conquer strategy introduced in this paper represents a promising step towards making this technology more practical and widely applicable.
Technical Explanation
The proposed method follows a divide-and-conquer strategy to recover 3D human mesh from arbitrary multi-view images. It first estimates the 3D pose of the person in each input image using a self-learning canonical space multi-view 3D approach. This provides an initial 3D pose estimate that is then used to guide the reconstruction of the full 3D mesh.
To reconstruct the 3D mesh, the method employs a self-supervised multi-person multi-view approach that leverages the estimated 3D poses. This allows the system to handle a wide range of camera viewpoints without requiring additional 2D keypoint annotations or constrained camera setups.
The 3D mesh reconstruction also draws inspiration from learning topology-uniformed face mesh by volume and generalizable 3D scene reconstruction via divide-and-conquer techniques. By breaking down the problem and tackling each part separately, the method is able to produce accurate and robust 3D human mesh models from diverse multi-view inputs.
The paper also explores semi-supervised unconstrained head pose estimation in the wild, which can further improve the 3D pose estimation and mesh reconstruction accuracy.
Critical Analysis
The paper presents a promising approach for 3D human mesh recovery from arbitrary multi-view images. The key strength of the method is its ability to handle diverse camera viewpoints and settings, which is a common challenge in this domain.
One potential limitation is that the method still requires 3D pose estimation as an initial step, which could introduce errors that propagate through the rest of the reconstruction process. Further research could explore ways to tightly integrate the pose estimation and mesh reconstruction components to mitigate this issue.
Additionally, the paper does not provide a comprehensive evaluation of the method's performance on a wide range of real-world datasets, which could reveal other practical limitations or areas for improvement. Expanding the experimental validation would help better understand the method's strengths, weaknesses, and broader applicability.
Overall, the divide-and-conquer strategy introduced in this paper represents an interesting and potentially impactful contribution to the field of 3D human mesh recovery. Further refinement and validation of the approach could lead to more robust and practical solutions for this challenging problem.
Conclusion
This research paper presents a novel method for recovering 3D human mesh models from arbitrary multi-view images. The key innovation is the use of a divide-and-conquer strategy, which breaks down the problem into more manageable sub-tasks and allows the system to handle diverse camera viewpoints without relying on specialized equipment or additional annotations.
The proposed approach demonstrates promising results and represents an important step towards making 3D human mesh reconstruction more practical and widely applicable. With further refinement and validation, this technology could have significant implications for a wide range of applications, such as virtual reality, fashion, and healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
0
0
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
4/10/2024
🖼️
3D Hand Mesh Recovery from Monocular RGB in Camera Space
Haonan Li, Patrick P. K. Chen, Yitong Zhou
0
0
With the rapid advancement of technologies such as virtual reality, augmented reality, and gesture control, users expect interactions with computer interfaces to be more natural and intuitive. Existing visual algorithms often struggle to accomplish advanced human-computer interaction tasks, necessitating accurate and reliable absolute spatial prediction methods. Moreover, dealing with complex scenes and occlusions in monocular images poses entirely new challenges. This study proposes a network model that performs parallel processing of root-relative grids and root recovery tasks. The model enables the recovery of 3D hand meshes in camera space from monocular RGB images. To facilitate end-to-end training, we utilize an implicit learning approach for 2D heatmaps, enhancing the compatibility of 2D cues across different subtasks. Incorporate the Inception concept into spectral graph convolutional network to explore relative mesh of root, and integrate it with the locally detailed and globally attentive method designed for root recovery exploration. This approach improves the model's predictive performance in complex environments and self-occluded scenes. Through evaluation on the large-scale hand dataset FreiHAND, we have demonstrated that our proposed model is comparable with state-of-the-art models. This study contributes to the advancement of techniques for accurate and reliable absolute spatial prediction in various human-computer interaction applications.
5/14/2024
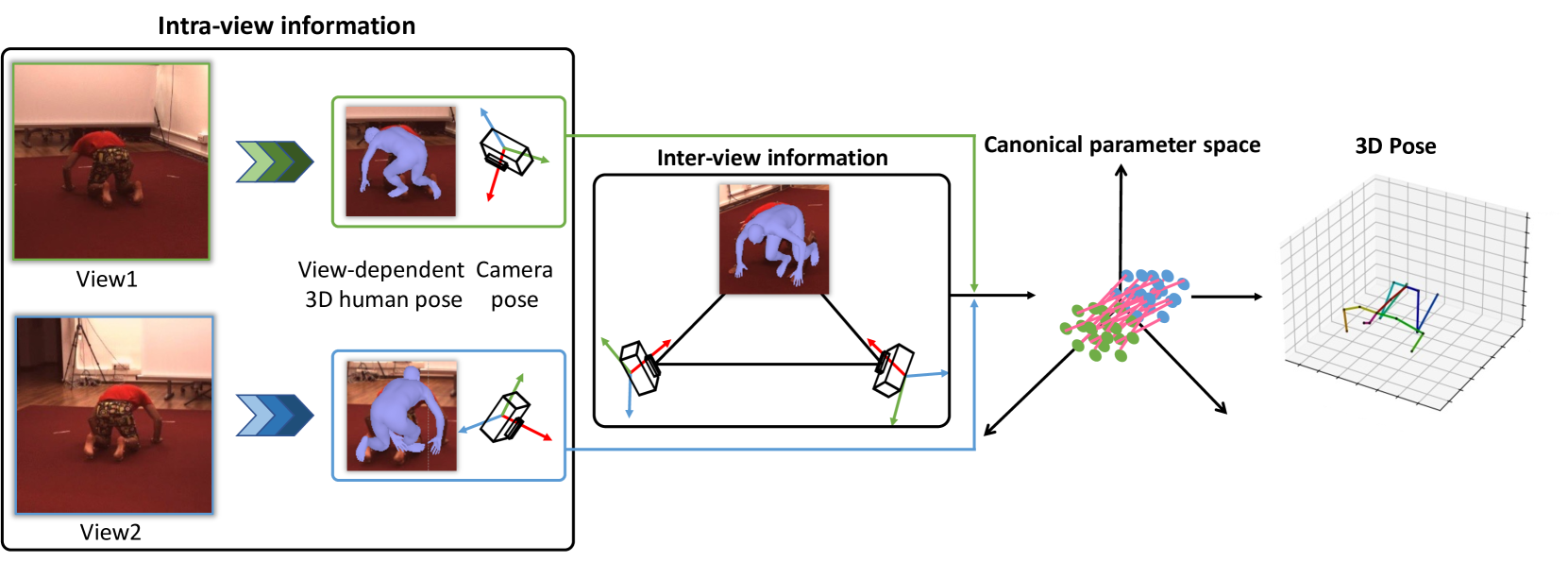
Self-learning Canonical Space for Multi-view 3D Human Pose Estimation
Xiaoben Li, Mancheng Meng, Ziyan Wu, Terrence Chen, Fan Yang, Dinggang Shen
0
0
Multi-view 3D human pose estimation is naturally superior to single view one, benefiting from more comprehensive information provided by images of multiple views. The information includes camera poses, 2D/3D human poses, and 3D geometry. However, the accurate annotation of these information is hard to obtain, making it challenging to predict accurate 3D human pose from multi-view images. To deal with this issue, we propose a fully self-supervised framework, named cascaded multi-view aggregating network (CMANet), to construct a canonical parameter space to holistically integrate and exploit multi-view information. In our framework, the multi-view information is grouped into two categories: 1) intra-view information , 2) inter-view information. Accordingly, CMANet consists of two components: intra-view module (IRV) and inter-view module (IEV). IRV is used for extracting initial camera pose and 3D human pose of each view; IEV is to fuse complementary pose information and cross-view 3D geometry for a final 3D human pose. To facilitate the aggregation of the intra- and inter-view, we define a canonical parameter space, depicted by per-view camera pose and human pose and shape parameters ($theta$ and $beta$) of SMPL model, and propose a two-stage learning procedure. At first stage, IRV learns to estimate camera pose and view-dependent 3D human pose supervised by confident output of an off-the-shelf 2D keypoint detector. At second stage, IRV is frozen and IEV further refines the camera pose and optimizes the 3D human pose by implicitly encoding the cross-view complement and 3D geometry constraint, achieved by jointly fitting predicted multi-view 2D keypoints. The proposed framework, modules, and learning strategy are demonstrated to be effective by comprehensive experiments and CMANet is superior to state-of-the-art methods in extensive quantitative and qualitative analysis.
4/1/2024
❗
3D Human Scan With A Moving Event Camera
Kai Kohyama, Shintaro Shiba, Yoshimitsu Aoki
0
0
Capturing a 3D human body is one of the important tasks in computer vision with a wide range of applications such as virtual reality and sports analysis. However, conventional frame cameras are limited by their temporal resolution and dynamic range, which imposes constraints in real-world application setups. Event cameras have the advantages of high temporal resolution and high dynamic range (HDR), but the development of event-based methods is necessary to handle data with different characteristics. This paper proposes a novel event-based method for 3D pose estimation and human mesh recovery. Prior work on event-based human mesh recovery require frames (images) as well as event data. The proposed method solely relies on events; it carves 3D voxels by moving the event camera around a stationary body, reconstructs the human pose and mesh by attenuated rays, and fit statistical body models, preserving high-frequency details. The experimental results show that the proposed method outperforms conventional frame-based methods in the estimation accuracy of both pose and body mesh. We also demonstrate results in challenging situations where a conventional camera has motion blur. This is the first to demonstrate event-only human mesh recovery, and we hope that it is the first step toward achieving robust and accurate 3D human body scanning from vision sensors. https://florpeng.github.io/event-based-human-scan/
4/17/2024