Semantic Stealth: Adversarial Text Attacks on NLP Using Several Methods
2404.05159
0
0
🔮
Abstract
In various real-world applications such as machine translation, sentiment analysis, and question answering, a pivotal role is played by NLP models, facilitating efficient communication and decision-making processes in domains ranging from healthcare to finance. However, a significant challenge is posed to the robustness of these natural language processing models by text adversarial attacks. These attacks involve the deliberate manipulation of input text to mislead the predictions of the model while maintaining human interpretability. Despite the remarkable performance achieved by state-of-the-art models like BERT in various natural language processing tasks, they are found to remain vulnerable to adversarial perturbations in the input text. In addressing the vulnerability of text classifiers to adversarial attacks, three distinct attack mechanisms are explored in this paper using the victim model BERT: BERT-on-BERT attack, PWWS attack, and Fraud Bargain's Attack (FBA). Leveraging the IMDB, AG News, and SST2 datasets, a thorough comparative analysis is conducted to assess the effectiveness of these attacks on the BERT classifier model. It is revealed by the analysis that PWWS emerges as the most potent adversary, consistently outperforming other methods across multiple evaluation scenarios, thereby emphasizing its efficacy in generating adversarial examples for text classification. Through comprehensive experimentation, the performance of these attacks is assessed and the findings indicate that the PWWS attack outperforms others, demonstrating lower runtime, higher accuracy, and favorable semantic similarity scores. The key insight of this paper lies in the assessment of the relative performances of three prevalent state-of-the-art attack mechanisms.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the robustness of natural language processing (NLP) models to text adversarial attacks.
- Three attack mechanisms are investigated using the BERT model as the victim: BERT-on-BERT attack, PWWS attack, and Fraud Bargain's Attack (FBA).
- The effectiveness of these attacks is evaluated on the IMDB, AG News, and SST2 datasets, with a focus on comparing their performance.
Plain English Explanation
NLP models play a crucial role in various real-world applications, such as machine translation, sentiment analysis, and question answering. These models help facilitate efficient communication and decision-making processes in domains ranging from healthcare to finance. However, a significant challenge to the robustness of these NLP models is posed by text adversarial attacks. These attacks involve deliberately manipulating the input text to mislead the model's predictions, while maintaining human interpretability.
Even state-of-the-art models like BERT, which have achieved remarkable performance in various NLP tasks, are found to be vulnerable to these adversarial perturbations in the input text. This paper explores three different attack mechanisms to assess the vulnerability of BERT-based text classifiers: the BERT-on-BERT attack, the PWWS attack, and the Fraud Bargain's Attack (FBA). By leveraging popular datasets like IMDB, AG News, and SST2, the researchers conduct a thorough comparative analysis to evaluate the effectiveness of these attacks.
The key insight from this study is that the PWWS attack emerges as the most potent adversary, consistently outperforming the other methods across multiple evaluation scenarios. This suggests that the PWWS attack is particularly effective in generating adversarial examples that can fool text classification models like BERT.
Technical Explanation
This paper investigates the robustness of natural language processing (NLP) models, specifically the BERT classifier, to three different text adversarial attack mechanisms: the BERT-on-BERT attack, the PWWS attack, and the Fraud Bargain's Attack (FBA).
The researchers leverage three popular datasets - IMDB, AG News, and SST2 - to assess the effectiveness of these attacks. For each attack, they evaluate the performance in terms of metrics like runtime, attack success rate, and semantic similarity between the original and adversarial examples.
The analysis reveals that the PWWS attack consistently outperforms the other methods across the evaluation scenarios. The PWWS attack demonstrates lower runtime, higher accuracy in fooling the BERT classifier, and better preservation of the semantic similarity between the original and adversarial examples.
These findings highlight the potency of the PWWS attack in generating adversarial examples that can effectively mislead BERT-based text classifiers. The paper provides valuable insights into the relative performance of these state-of-the-art attack mechanisms, which can inform the development of more robust NLP models and defensive strategies against adversarial attacks.
Critical Analysis
The paper provides a comprehensive assessment of the performance of three prominent text adversarial attack mechanisms against the BERT classifier. The researchers have carefully designed their experiments and provided a thorough analysis of the results.
One potential limitation of the study is the focus on a single victim model, BERT. While BERT is a widely used and influential NLP model, it would be valuable to extend the analysis to other popular models, such as GPT-3 or RoBERTa, to gain a more comprehensive understanding of the robustness of text classifiers to adversarial attacks.
Additionally, the paper does not delve into the underlying reasons why the PWWS attack outperforms the other methods. It would be insightful to explore the specific characteristics or mechanisms of the PWWS attack that contribute to its superior performance, as this could provide valuable insights for developing more effective defensive strategies.
Furthermore, the paper could have addressed the practical implications of these attacks and their potential real-world impact. Exploring how these adversarial examples might be used in malicious scenarios, such as spreading misinformation or evading content moderation systems, could further highlight the importance of this research.
Overall, this paper provides a valuable contribution to the understanding of text adversarial attacks and the relative performance of different attack mechanisms. However, additional research and analysis could enhance the scope and impact of the findings.
Conclusion
This paper presents a comparative analysis of three text adversarial attack mechanisms - BERT-on-BERT, PWWS, and Fraud Bargain's Attack - against the BERT classifier model. The key finding is that the PWWS attack emerges as the most potent adversary, consistently outperforming the other methods across multiple evaluation scenarios.
The study's insights underscore the need for continued research and development of robust NLP models that can withstand sophisticated adversarial attacks. As NLP systems become increasingly ubiquitous in various applications, understanding and mitigating their vulnerabilities to text-based adversarial attacks is crucial for ensuring the reliability and trustworthiness of these systems.
The paper's exploration of these attack mechanisms contributes to the broader field of adversarial machine learning, providing valuable insights that can inform the design of more effective defensive strategies and the development of more secure NLP models. By addressing the challenges posed by text adversarial attacks, researchers and practitioners can work towards building NLP systems that are resilient, reliable, and capable of maintaining their performance in the face of malicious attempts to mislead them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
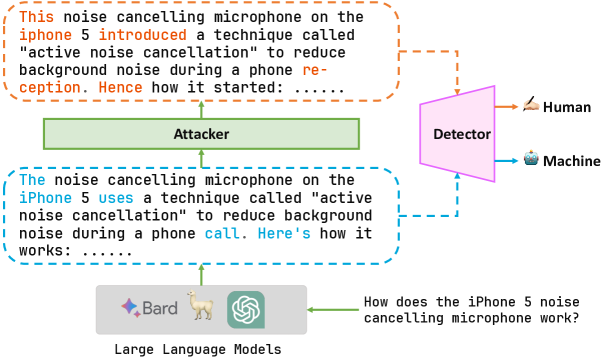
Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
Ying Zhou, Ben He, Le Sun
0
0
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
4/3/2024
🔄
Adversarial Attacks and Defense for Conversation Entailment Task
Zhenning Yang, Ryan Krawec, Liang-Yuan Wu
0
0
As the deployment of NLP systems in critical applications grows, ensuring the robustness of large language models (LLMs) against adversarial attacks becomes increasingly important. Large language models excel in various NLP tasks but remain vulnerable to low-cost adversarial attacks. Focusing on the domain of conversation entailment, where multi-turn dialogues serve as premises to verify hypotheses, we fine-tune a transformer model to accurately discern the truthfulness of these hypotheses. Adversaries manipulate hypotheses through synonym swapping, aiming to deceive the model into making incorrect predictions. To counteract these attacks, we implemented innovative fine-tuning techniques and introduced an embedding perturbation loss method to significantly bolster the model's robustness. Our findings not only emphasize the importance of defending against adversarial attacks in NLP but also highlight the real-world implications, suggesting that enhancing model robustness is critical for reliable NLP applications.
5/3/2024
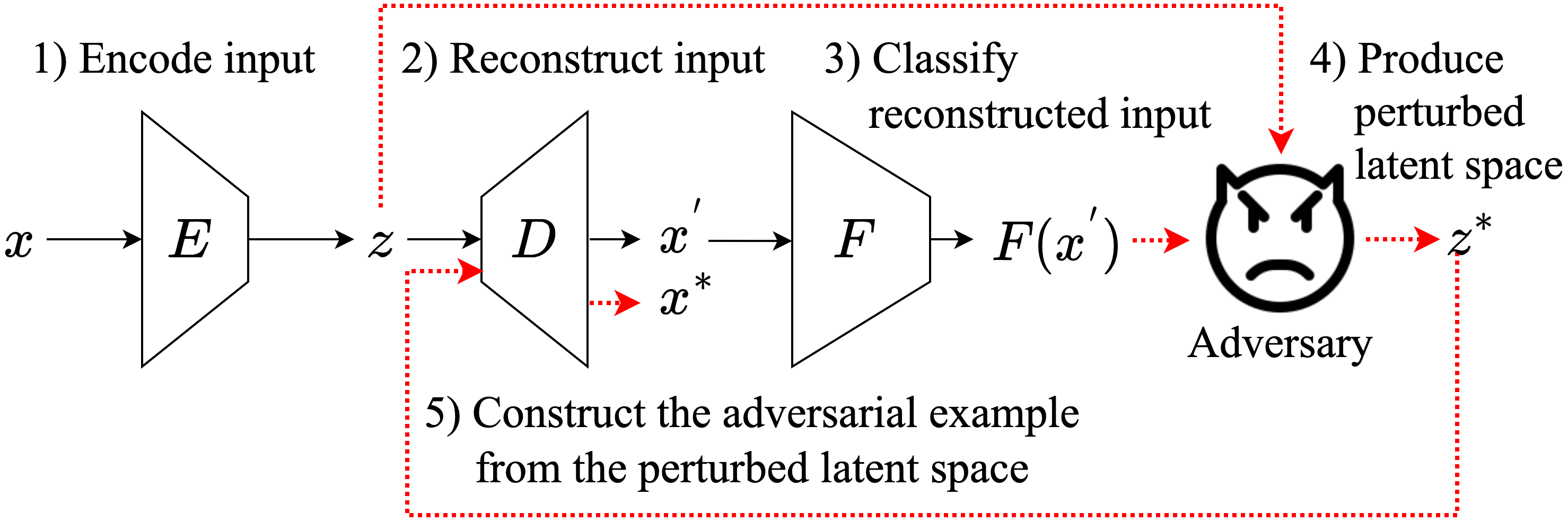
On Adversarial Examples for Text Classification by Perturbing Latent Representations
Korn Sooksatra, Bikram Khanal, Pablo Rivas
0
0
Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust. Fortunately, the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, we transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, we convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, we create a framework that measures the robustness of a text classifier by using the gradients of the classifier.
5/8/2024

Adversarial Attacks and Dimensionality in Text Classifiers
Nandish Chattopadhyay, Atreya Goswami, Anupam Chattopadhyay
0
0
Adversarial attacks on machine learning algorithms have been a key deterrent to the adoption of AI in many real-world use cases. They significantly undermine the ability of high-performance neural networks by forcing misclassifications. These attacks introduce minute and structured perturbations or alterations in the test samples, imperceptible to human annotators in general, but trained neural networks and other models are sensitive to it. Historically, adversarial attacks have been first identified and studied in the domain of image processing. In this paper, we study adversarial examples in the field of natural language processing, specifically text classification tasks. We investigate the reasons for adversarial vulnerability, particularly in relation to the inherent dimensionality of the model. Our key finding is that there is a very strong correlation between the embedding dimensionality of the adversarial samples and their effectiveness on models tuned with input samples with same embedding dimension. We utilize this sensitivity to design an adversarial defense mechanism. We use ensemble models of varying inherent dimensionality to thwart the attacks. This is tested on multiple datasets for its efficacy in providing robustness. We also study the problem of measuring adversarial perturbation using different distance metrics. For all of the aforementioned studies, we have run tests on multiple models with varying dimensionality and used a word-vector level adversarial attack to substantiate the findings.
4/4/2024