Offboard Occupancy Refinement with Hybrid Propagation for Autonomous Driving

0

Sign in to get full access
Overview
- This paper introduces a new method called "OccFiner" for improving the accuracy of 3D occupancy prediction in semantic scene completion tasks.
- The key idea is to use a hybrid propagation approach that combines explicit feature fusion and implicit geometric enhancement to refine the occupancy predictions.
- The method is evaluated on several benchmark datasets and is shown to outperform existing state-of-the-art approaches.
Plain English Explanation
The paper presents a new technique called "OccFiner" for improving the accuracy of 3D scene understanding. The goal is to be able to take sensor data from things like cameras and lidars, and use machine learning to predict what the 3D environment looks like, including what objects are present and where they are located.
The core innovation in OccFiner is a "hybrid propagation" approach that combines two different strategies. The first is explicit feature fusion, where information from different sensors is directly combined to get a more complete picture. The second is implicit geometric enhancement, which uses the underlying 3D structure of the scene to refine the occupancy predictions in a more sophisticated way.
By using this hybrid approach, the authors show that OccFiner is able to outperform existing state-of-the-art methods for 3D semantic scene completion tasks on several benchmark datasets. This means it can more accurately predict the 3D layout and contents of a scene from sensor data.
This type of 3D scene understanding is a critical capability for applications like self-driving cars, robotics, and augmented reality, where having an accurate 3D model of the environment is essential for safe and intelligent operation. The improvements in OccFusion and Real-Time 3D Semantic Occupancy Prediction show the importance of this problem and the potential impact of the research.
Technical Explanation
The paper proposes a new method called "OccFiner" for refining 3D occupancy predictions in semantic scene completion tasks. The key innovation is a hybrid propagation approach that combines explicit feature fusion and implicit geometric enhancement.
In the explicit feature fusion component, information from different sensor modalities (e.g. RGB images, depth maps, lidar scans) is directly combined to get a more comprehensive understanding of the 3D scene. This is similar to the approach used in OccFusion.
The implicit geometric enhancement component uses the underlying 3D structure of the scene to refine the occupancy predictions in a more sophisticated way. This builds on ideas from GeoCCNet and Co-OCC to implicitly capture 3D geometrical constraints.
By combining these two complementary approaches, OccFiner is able to leverage the strengths of both explicit and implicit techniques to produce more accurate 3D occupancy predictions. The authors evaluate the method on several benchmark datasets for 3D semantic scene completion and show that it outperforms existing state-of-the-art approaches.
Critical Analysis
The paper presents a well-designed study with thorough experiments and analysis. The hybrid propagation approach of explicit feature fusion and implicit geometric enhancement is a novel contribution that builds on previous work in this area.
One potential limitation is that the method may be more computationally expensive than some simpler approaches, due to the added complexity of the hybrid propagation mechanism. The authors do not provide detailed runtime or memory usage comparisons, so the practical efficiency of OccFiner is not fully clear.
Additionally, the paper focuses on evaluating the method on standard benchmark datasets, but does not explore how it might perform in more diverse or challenging real-world scenarios. Further testing in more varied environments could help validate the robustness and generalization of the approach.
Overall, the research represents a promising advance in 3D semantic scene understanding, with the potential to significantly improve the accuracy of occupancy prediction for applications like autonomous navigation and robotics. The authors have made a valuable contribution to this important field of study.
Conclusion
The OccFiner method presented in this paper offers a novel hybrid approach to refining 3D occupancy predictions for semantic scene completion tasks. By combining explicit feature fusion and implicit geometric enhancement, the technique is able to outperform existing state-of-the-art methods on several benchmark datasets.
This research is an important step forward in the quest to build accurate 3D models of real-world environments, which is a crucial capability for applications like self-driving cars, robotics, and augmented reality. The hybrid propagation strategy introduced here represents a promising direction for further advancing the state of the art in this domain.
While there are some potential limitations to consider, such as computational efficiency and generalization to diverse real-world scenarios, the overall impact of this work is significant. The insights and techniques developed in this paper can help drive continued progress in the field of 3D scene understanding, with far-reaching implications for how we perceive and interact with the physical world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Offboard Occupancy Refinement with Hybrid Propagation for Autonomous Driving
Hao Shi, Song Wang, Jiaming Zhang, Xiaoting Yin, Zhongdao Wang, Guangming Wang, Jianke Zhu, Kailun Yang, Kaiwei Wang
Vision-based occupancy prediction, also known as 3D Semantic Scene Completion (SSC), presents a significant challenge in computer vision. Previous methods, confined to onboard processing, struggle with simultaneous geometric and semantic estimation, continuity across varying viewpoints, and single-view occlusion. Our paper introduces OccFiner, a novel offboard framework designed to enhance the accuracy of vision-based occupancy predictions. OccFiner operates in two hybrid phases: 1) a multi-to-multi local propagation network that implicitly aligns and processes multiple local frames for correcting onboard model errors and consistently enhancing occupancy accuracy across all distances. 2) the region-centric global propagation, focuses on refining labels using explicit multi-view geometry and integrating sensor bias, especially to increase the accuracy of distant occupied voxels. Extensive experiments demonstrate that OccFiner improves both geometric and semantic accuracy across various types of coarse occupancy, setting a new state-of-the-art performance on the SemanticKITTI dataset. Notably, OccFiner elevates vision-based SSC models to a level even surpassing that of LiDAR-based onboard SSC models. Furthermore, OccFiner is the first to achieve automatic annotation of SSC in a purely vision-based approach. Quantitative experiments prove that OccFiner successfully facilitates occupancy data loop-closure in autonomous driving. Additionally, we quantitatively and qualitatively validate the superiority of the offboard approach on city-level SSC static maps. The source code will be made publicly available at https://github.com/MasterHow/OccFiner.
Read more7/9/2024
0
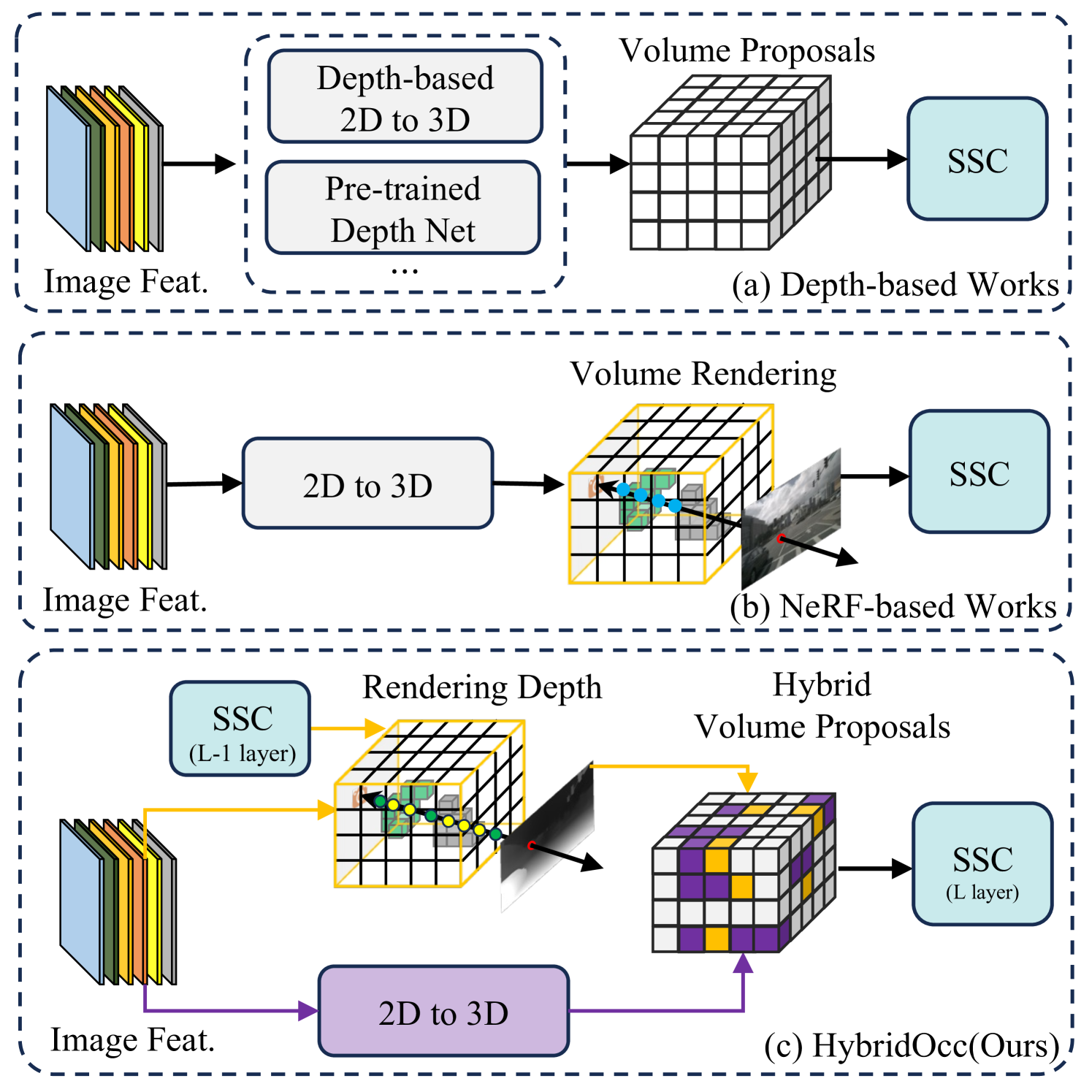
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Xiao Zhao, Bo Chen, Mingyang Sun, Dingkang Yang, Youxing Wang, Xukun Zhang, Mingcheng Li, Dongliang Kou, Xiaoyi Wei, Lihua Zhang
Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.
Read more8/20/2024

0
AdaOcc: Adaptive-Resolution Occupancy Prediction
Chao Chen, Ruoyu Wang, Yuliang Guo, Cheng Zhao, Xinyu Huang, Chen Feng, Liu Ren
Autonomous driving in complex urban scenarios requires 3D perception to be both comprehensive and precise. Traditional 3D perception methods focus on object detection, resulting in sparse representations that lack environmental detail. Recent approaches estimate 3D occupancy around vehicles for a more comprehensive scene representation. However, dense 3D occupancy prediction increases computational demands, challenging the balance between efficiency and resolution. High-resolution occupancy grids offer accuracy but demand substantial computational resources, while low-resolution grids are efficient but lack detail. To address this dilemma, we introduce AdaOcc, a novel adaptive-resolution, multi-modal prediction approach. Our method integrates object-centric 3D reconstruction and holistic occupancy prediction within a single framework, performing highly detailed and precise 3D reconstruction only in regions of interest (ROIs). These high-detailed 3D surfaces are represented in point clouds, thus their precision is not constrained by the predefined grid resolution of the occupancy map. We conducted comprehensive experiments on the nuScenes dataset, demonstrating significant improvements over existing methods. In close-range scenarios, we surpass previous baselines by over 13% in IOU, and over 40% in Hausdorff distance. In summary, AdaOcc offers a more versatile and effective framework for delivering accurate 3D semantic occupancy prediction across diverse driving scenarios.
Read more8/27/2024

0
GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, Lizhuang Ma
3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
Read more5/20/2024