Hydragen: High-Throughput LLM Inference with Shared Prefixes
2402.05099
1
0
🤯
Abstract
Transformer-based large language models (LLMs) are now deployed to hundreds of millions of users. LLM inference is commonly performed on batches of sequences that share a prefix, such as few-shot examples or a chatbot system prompt. Decoding in this large-batch setting can be bottlenecked by the attention operation, which reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch. In this work, we introduce Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications. Our method can improve end-to-end CodeLlama-13b throughput by up to 32x against competitive baselines, with speedup growing with the batch size and shared prefix length. Hydragen also enables the use of very long shared contexts: with a large batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%. Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing us to further reduce inference time on competitive programming problems by 55%.
Create account to get full access
Overview
- Transformer-based large language models (LLMs) are now widely used, deployed to hundreds of millions of users.
- LLM inference is often performed on batches of sequences that share a prefix, such as few-shot examples or a chatbot system prompt.
- The attention operation during decoding can be a bottleneck, as it reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch.
Plain English Explanation
The paper introduces Hydragen, a new way to perform attention calculations in large language models (LLMs) that are used by hundreds of millions of people. Attention is a key part of how LLMs work, but it can be slow, especially when processing multiple sequences at once that have some parts in common (like a shared prompt).
Hydragen solves this by separating the attention calculation into two parts - one for the shared prefix (the common part) and one for the unique suffix (the different part) of each sequence. This allows Hydragen to batch the attention calculations for the shared prefix, which is more efficient. It also enables the use of hardware-friendly matrix multiplications, further boosting performance.
The paper shows that Hydragen can improve the end-to-end throughput of a large language model called CodeLlama-13b by up to 32 times compared to other approaches. The speedup increases as the batch size and shared prefix length gets larger. Hydragen also allows for using very long shared contexts, which is important for applications like Megalodon that need to handle large amounts of context.
Beyond simple prefix-suffix decomposition, Hydragen can also be applied to more complex tree-based prompt sharing patterns, further reducing inference time on tasks like competitive programming.
Technical Explanation
The paper introduces Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications.
The authors evaluate Hydragen on the task of CodeLlama-13b inference, where they show it can improve end-to-end throughput by up to 32x against competitive baselines. The speedup grows with the batch size and shared prefix length. Hydragen also enables the use of very long shared contexts: with a large batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%.
Furthermore, the paper demonstrates that Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing for an additional 55% reduction in inference time on competitive programming problems compared to other methods.
Critical Analysis
The paper provides a thorough technical explanation of the Hydragen approach and demonstrates its significant performance benefits for large language model inference. However, the authors do not discuss any potential limitations or caveats of their method.
One area that could be explored further is the impact of Hydragen on model accuracy. While the paper focuses on improving inference throughput, it does not investigate whether the proposed decomposition of attention computations has any effect on the model's predictive performance. This would be an important consideration, as any loss in accuracy could limit the practical usefulness of the technique.
Additionally, the paper does not address the computational and memory requirements of Hydragen compared to other attention implementations. Understanding the trade-offs in terms of resource usage could help determine the most appropriate scenarios for deploying the proposed method.
Finally, the authors do not discuss any potential issues or challenges that may arise when applying Hydragen to a broader range of language modeling tasks or datasets. Exploring the generalizability of the technique would help assess its overall significance and impact on the field.
Conclusion
The Hydragen paper presents a significant advancement in improving the efficiency of attention computations for large language model inference, particularly in the common scenario of processing batches of sequences with shared prefixes. The proposed method can provide substantial throughput improvements of up to 32x, with the benefits increasing as the batch size and shared prefix length grow.
This breakthrough has important implications for the practical deployment of large language models, as it enables more economical and scalable inference while preserving the ability to handle long-range contexts, as demonstrated by the Megalodon and hierarchical context merging approaches. By addressing a key bottleneck in attention computations, Hydragen represents a significant step forward in making large language models more accessible and efficient for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024
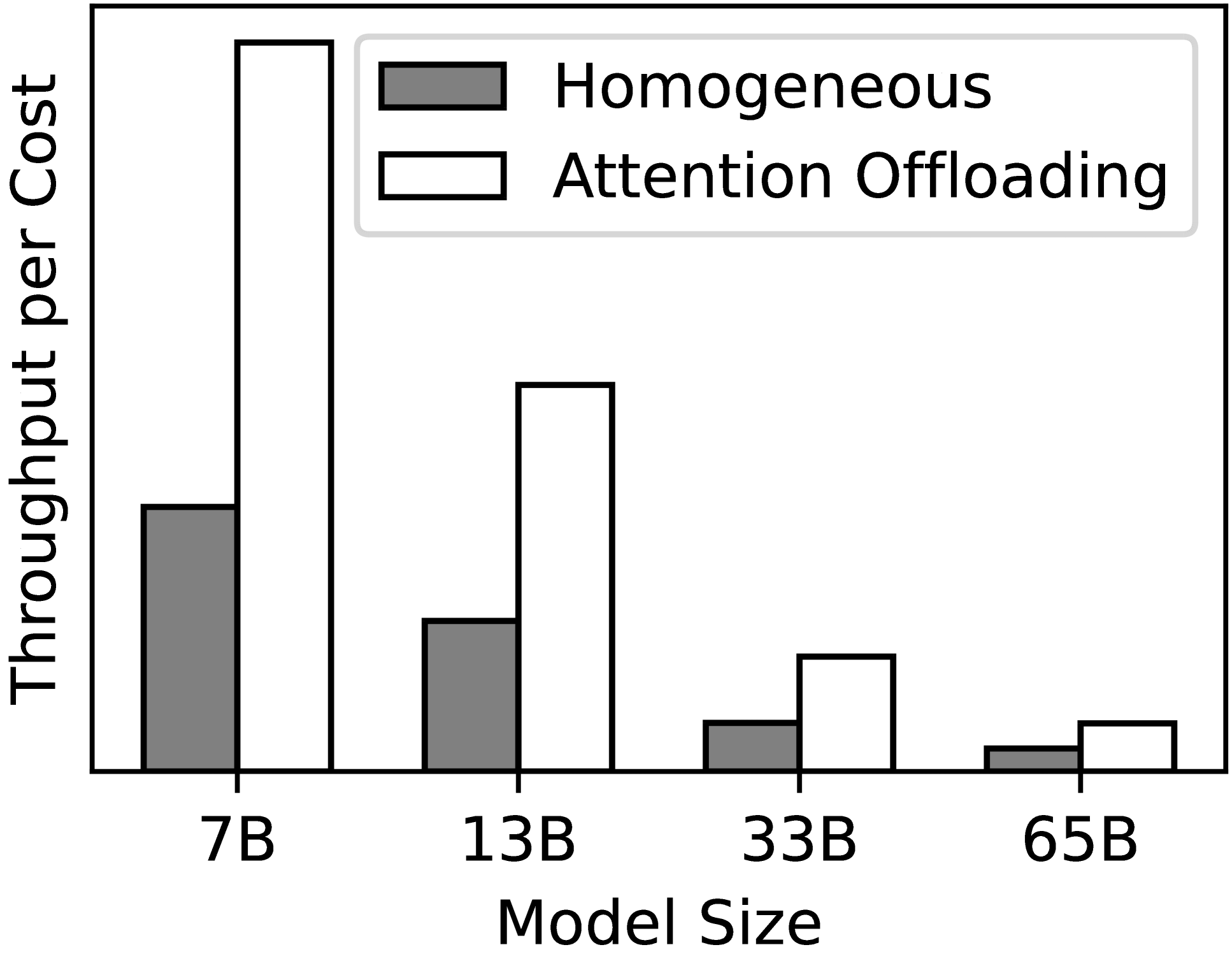
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024

HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Heejun Lee, Geon Park, Youngwan Lee, Jina Kim, Wonyoung Jeong, Myeongjae Jeon, Sung Ju Hwang
0
0
In modern large language models (LLMs), increasing sequence lengths is a crucial challenge for enhancing their comprehension and coherence in handling complex tasks such as multi-modal question answering. However, handling long context sequences with LLMs is prohibitively costly due to the conventional attention mechanism's quadratic time and space complexity, and the context window size is limited by the GPU memory. Although recent works have proposed linear and sparse attention mechanisms to address this issue, their real-world applicability is often limited by the need to re-train pre-trained models. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which simultaneously reduces the training and inference time complexity from $O(T^2)$ to $O(T log T)$ and the space complexity from $O(T^2)$ to $O(T)$. To this end, we devise a dynamic sparse attention mechanism that generates an attention mask through a novel tree-search-like algorithm for a given query on the fly. HiP is training-free as it only utilizes the pre-trained attention scores to spot the positions of the top-$k$ most significant elements for each query. Moreover, it ensures that no token is overlooked, unlike the sliding window-based sub-quadratic attention methods, such as StreamingLLM. Extensive experiments on diverse real-world benchmarks demonstrate that HiP significantly reduces prompt (i.e., prefill) and decoding latency and memory usage while maintaining high generation performance with little or no degradation. As HiP allows pretrained LLMs to scale to millions of tokens on commodity GPUs with no additional engineering due to its easy plug-and-play deployment, we believe that our work will have a large practical impact, opening up the possibility to many long-context LLM applications previously infeasible.
6/17/2024
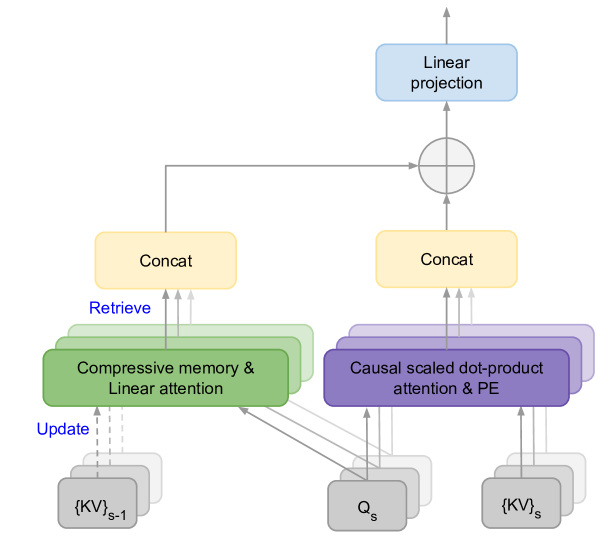
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024