Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
2404.08801
167
0
Abstract
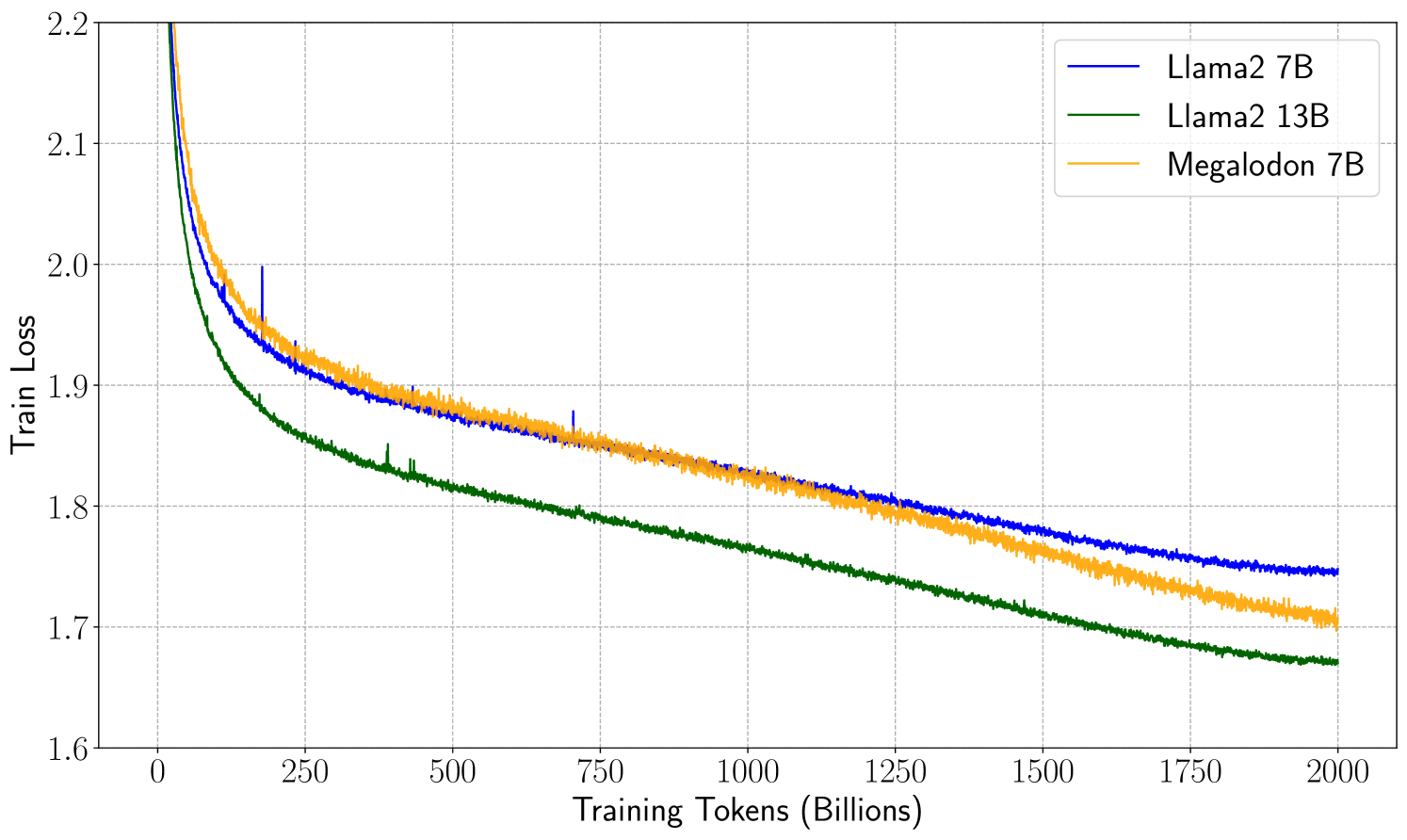
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration. In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. Megalodon reaches a training loss of 1.70, landing mid-way between Llama2-7B (1.75) and 13B (1.67). Code: https://github.com/XuezheMax/megalodon
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a novel architecture called Megalodon, which enables efficient pretraining and inference of large language models (LLMs) with unlimited context length.
- Megalodon builds upon the Moving Average Equipped Gated Attention (Mega) architecture, which addresses the challenges of long-context learning in LLMs.
- The authors demonstrate that Megalodon achieves state-of-the-art performance on a range of long-context tasks, while also being more computationally efficient compared to existing approaches.
Plain English Explanation
Megalodon is a new type of large language model (LLM) that can handle very long input texts, unlike traditional LLMs that struggle with long contexts. LLMs are AI systems that are trained on massive amounts of text data to generate human-like language.
The key innovation in Megalodon is its use of a technique called Moving Average Equipped Gated Attention (Mega). This allows the model to efficiently process long input texts without losing important information.
By using Mega, Megalodon can perform better on tasks that require understanding of long-form content, such as summarizing lengthy documents or answering questions about complex topics. Traditional LLMs often have difficulty maintaining context and coherence over long stretches of text.
The authors show that Megalodon outperforms other state-of-the-art models on various long-context benchmarks, while also being more efficient in terms of computational resources. This means Megalodon can be deployed on a wider range of devices and applications, including those with limited processing power.
Technical Explanation
The paper introduces a new architecture called Megalodon, which builds upon the Moving Average Equipped Gated Attention (Mega) mechanism. Mega is designed to enhance the efficiency of large language models (LLMs) during inference by introducing a moving average operation into the attention mechanism.
Megalodon further extends Mega by incorporating techniques to enable efficient pretraining and inference of LLMs with unlimited context length. The key components of Megalodon include:
-
Mega Attention: The use of Mega attention, which replaces the standard attention mechanism in Transformer-based models. Mega attention maintains a moving average of past attention weights, allowing the model to efficiently aggregate information from long contexts.
-
Chunked Attention: To handle arbitrarily long input sequences, Megalodon splits the input into smaller chunks and processes them in parallel, with attention computed within and across chunks.
-
Efficient Pretraining: The authors propose a pretraining strategy that leverages a combination of masked language modeling and a novel cross-attention objective to enable efficient learning of long-range dependencies.
The paper evaluates Megalodon on a range of long-context benchmarks, including LLOCO, LLM2Vec, and others. The results demonstrate that Megalodon achieves state-of-the-art performance on these tasks while being more computationally efficient compared to previous approaches.
Critical Analysis
The paper presents a promising solution to the challenge of processing long input texts in large language models. By leveraging the Mega attention mechanism and other techniques, Megalodon is able to efficiently handle long-context tasks that traditional LLMs struggle with.
However, the paper does not address some potential limitations of the Megalodon approach:
-
Generalization beyond benchmarks: While Megalodon performs well on the specific long-context benchmarks evaluated, it is unclear how it would generalize to a broader range of real-world applications that may have different characteristics and requirements.
-
Memory and storage overhead: The paper does not provide a detailed analysis of the memory and storage requirements of Megalodon, which could be a concern for deployment on resource-constrained devices.
-
Interpretability and explainability: As with many complex neural network architectures, the inner workings of Megalodon may be difficult to interpret and explain, which could limit its adoption in domains that require high levels of transparency.
Further research and evaluation would be needed to address these potential limitations and to more fully understand the strengths and weaknesses of the Megalodon approach.
Conclusion
The Megalodon architecture presented in this paper represents a significant advancement in the field of large language models, enabling efficient pretraining and inference with unlimited context length. By building upon the Mega attention mechanism, Megalodon achieves state-of-the-art performance on long-context benchmarks while being more computationally efficient than previous approaches.
This research has important implications for a wide range of applications that require understanding and generation of long-form text, such as document summarization, question answering, and knowledge-intensive tasks. As language models continue to grow in size and complexity, innovations like Megalodon will be crucial for ensuring these models can be deployed effectively and efficiently in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
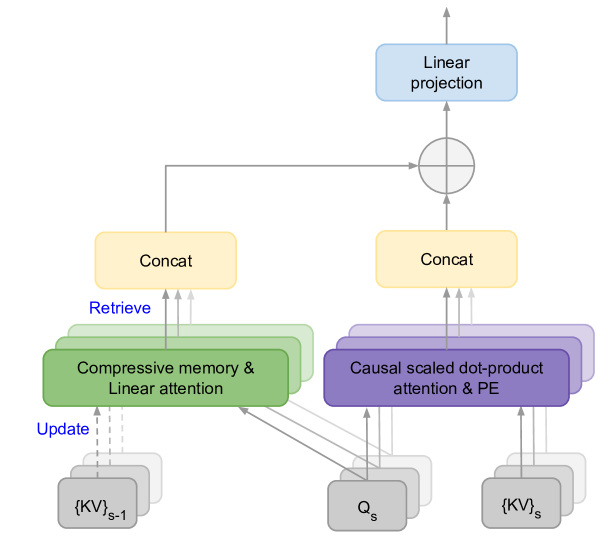
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024
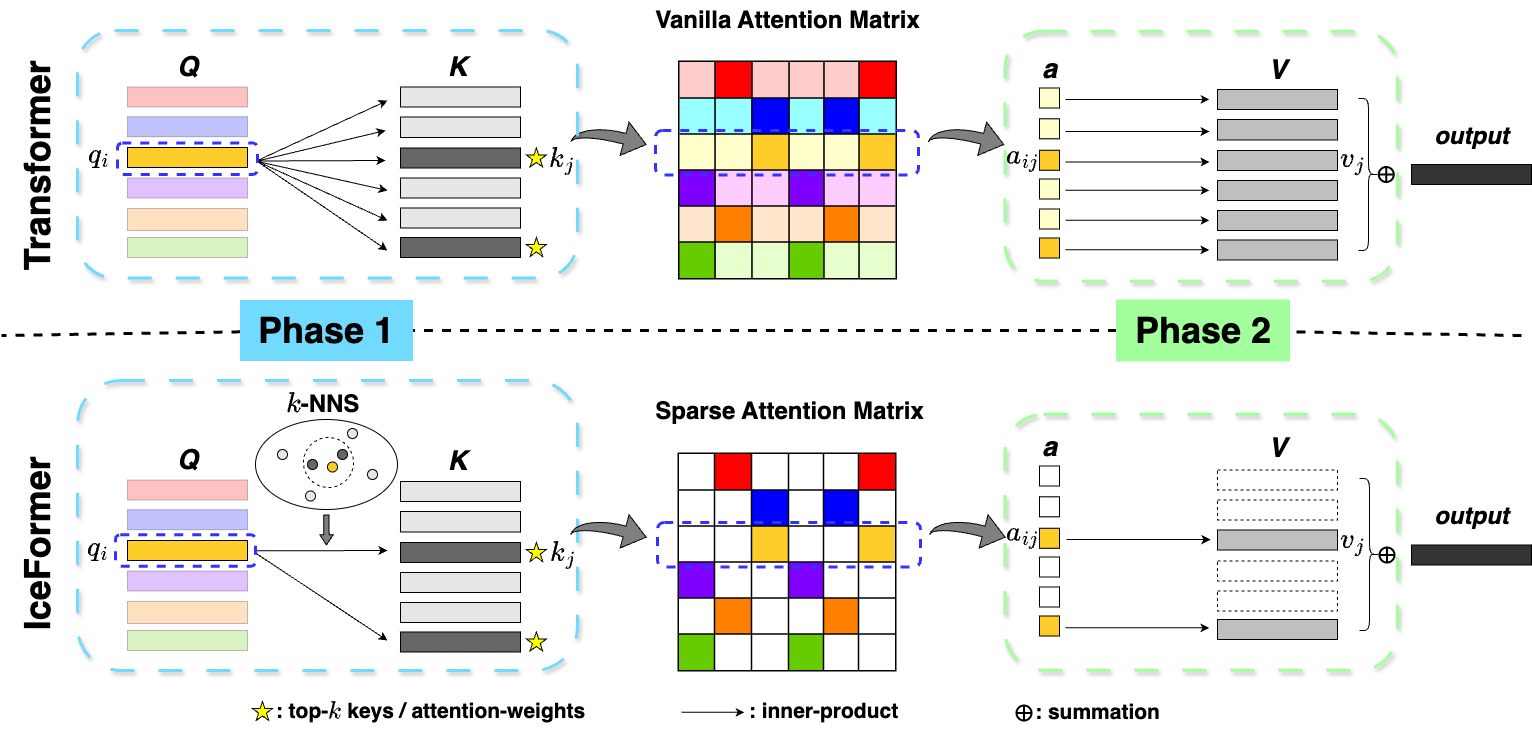
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
Yuzhen Mao, Martin Ester, Ke Li
0
0
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
5/7/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
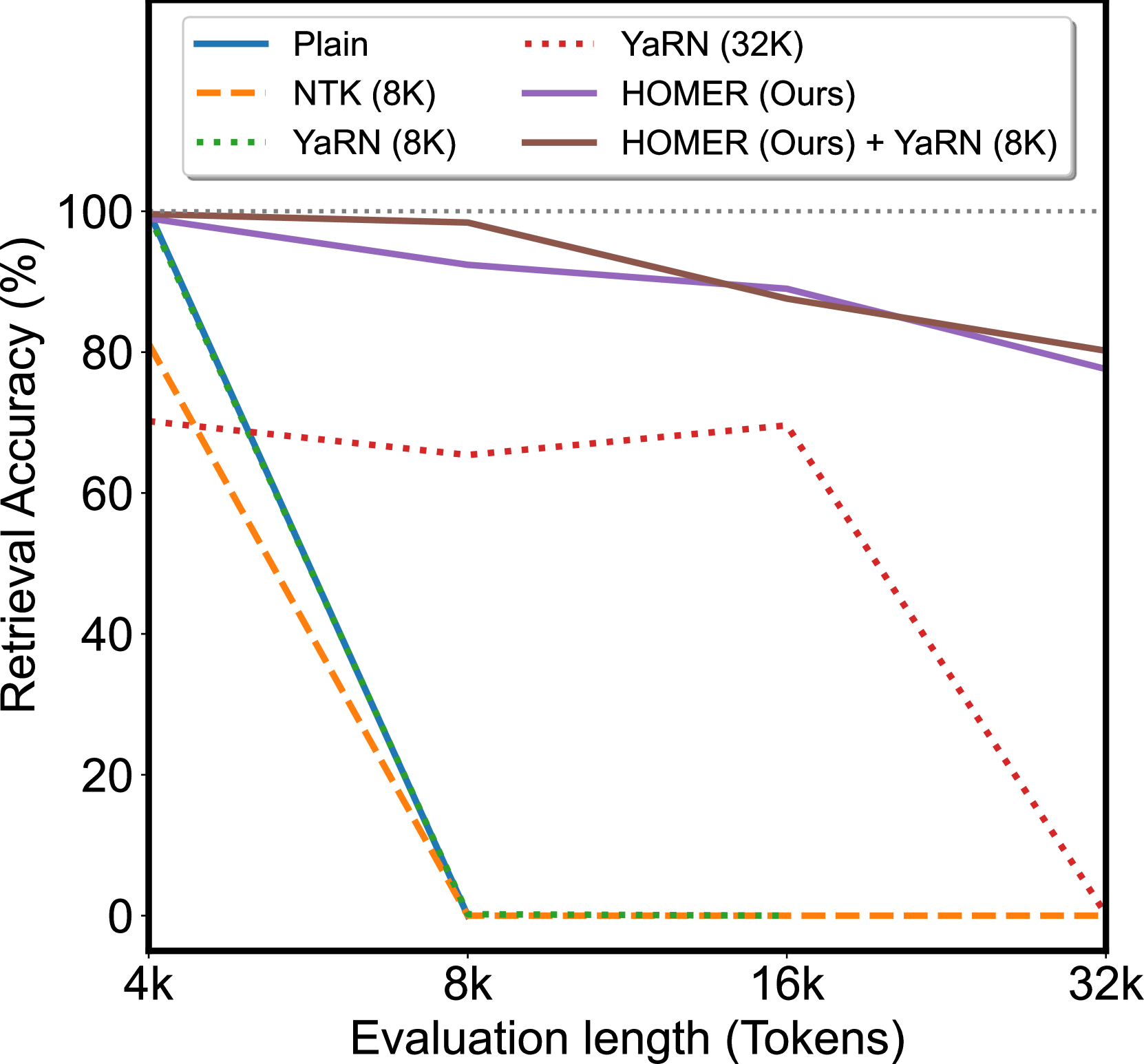
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Woomin Song, Seunghyuk Oh, Sangwoo Mo, Jaehyung Kim, Sukmin Yun, Jung-Woo Ha, Jinwoo Shin
0
0
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.
4/17/2024