HyperMAML: Few-Shot Adaptation of Deep Models with Hypernetworks

0
🤿
Sign in to get full access
Overview
- The paper introduces HyperMAML, a novel approach to few-shot learning that builds on the popular Model-Agnostic Meta-Learning (MAML) technique.
- The key idea is to use a trainable Hypernetwork to generate the weight updates, rather than relying on gradient descent.
- This allows the model to make more significant updates in fewer steps, overcoming a key limitation of MAML.
- Experiments show HyperMAML outperforms MAML and is competitive with other state-of-the-art few-shot learning methods.
Plain English Explanation
The main challenge in few-shot learning is to train models that can quickly adapt to new tasks, even when only a small amount of data is available. Model-Agnostic Meta-Learning (MAML) is a popular approach that tries to learn general, adaptable model parameters. However, MAML's reliance on gradient-based optimization means it can struggle to make the necessary weight changes in just a few update steps.
The new HyperMAML method solves this by using a Hypernetwork - a type of neural network that can generate the weight updates itself, rather than relying on gradient descent. This allows HyperMAML to make more significant updates in fewer steps, improving its ability to adapt quickly to new tasks with limited data.
Imagine you're teaching a child to play a new game. With MAML, you'd give the child a set of general strategies and have them gradually refine their play through many rounds of practice and feedback. With HyperMAML, you'd give the child a more powerful "meta-strategy generator" that can quickly produce customized strategies tailored to each new game situation, allowing the child to learn much faster.
Technical Explanation
The core idea behind HyperMAML is to replace the gradient-based weight update procedure in MAML with a Hypernetwork that can generate the updates directly. Specifically, the Hypernetwork takes in the current model weights and the task-specific data, and outputs the updates that should be applied to those weights.
This Hypernetwork is itself part of the overall HyperMAML model, and is trained end-to-end along with the base model parameters. The advantage is that the Hypernetwork can learn to produce weight updates that are much more significant than what a few gradient steps could achieve, overcoming a key limitation of MAML.
The authors evaluate HyperMAML on several standard few-shot learning benchmarks, comparing it to MAML as well as other meta-learning approaches like Cooperative Meta-Learning and Agnostic Sharpness-Aware Minimization. The results show HyperMAML consistently outperforms MAML and performs comparably to the other state-of-the-art techniques.
Critical Analysis
While HyperMAML offers an elegant solution to the limitations of MAML, the authors acknowledge that the additional complexity of the Hypernetwork may make the overall model more challenging to train in practice. There are also open questions around the generalization capabilities of the Hypernetwork - its ability to produce effective updates for tasks and data distributions that differ significantly from what it was trained on.
Additionally, the paper does not deeply explore the inner workings and learned behaviors of the Hypernetwork. Further analysis of how it generates the updates, and what types of update strategies it discovers, could provide valuable insights into the strengths and weaknesses of the approach.
Overall, HyperMAML represents an intriguing and promising direction for few-shot learning research, building on the foundations laid by MAML and other meta-learning techniques. As the field continues to evolve, it will be interesting to see how this line of work develops and addresses the remaining challenges.
Conclusion
The HyperMAML approach offers an innovative solution to the limitations of MAML, a popular few-shot learning technique. By using a trainable Hypernetwork to generate the weight updates, rather than relying on gradient descent, HyperMAML can make more significant updates in fewer steps, improving its ability to quickly adapt to new tasks with limited data.
Experimental results show HyperMAML consistently outperforms MAML and is competitive with other state-of-the-art few-shot learning methods. While the additional complexity of the Hypernetwork may present training challenges, the potential benefits of this approach make it an intriguing area for further research and development in the field of meta-learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
HyperMAML: Few-Shot Adaptation of Deep Models with Hypernetworks
M. Przewik{e}'zlikowski, P. Przybysz, J. Tabor, M. Zik{e}ba, P. Spurek
The aim of Few-Shot learning methods is to train models which can easily adapt to previously unseen tasks, based on small amounts of data. One of the most popular and elegant Few-Shot learning approaches is Model-Agnostic Meta-Learning (MAML). The main idea behind this method is to learn the general weights of the meta-model, which are further adapted to specific problems in a small number of gradient steps. However, the model's main limitation lies in the fact that the update procedure is realized by gradient-based optimisation. In consequence, MAML cannot always modify weights to the essential level in one or even a few gradient iterations. On the other hand, using many gradient steps results in a complex and time-consuming optimization procedure, which is hard to train in practice, and may lead to overfitting. In this paper, we propose HyperMAML, a novel generalization of MAML, where the training of the update procedure is also part of the model. Namely, in HyperMAML, instead of updating the weights with gradient descent, we use for this purpose a trainable Hypernetwork. Consequently, in this framework, the model can generate significant updates whose range is not limited to a fixed number of gradient steps. Experiments show that HyperMAML consistently outperforms MAML and performs comparably to other state-of-the-art techniques in a number of standard Few-Shot learning benchmarks.
Read more7/9/2024
✨
0
MAC: A Meta-Learning Approach for Feature Learning and Recombination
S. Tiwari, M. Gogoi, S. Verma, K. P. Singh
Optimization-based meta-learning aims to learn an initialization so that a new unseen task can be learned within a few gradient updates. Model Agnostic Meta-Learning (MAML) is a benchmark algorithm comprising two optimization loops. The inner loop is dedicated to learning a new task and the outer loop leads to meta-initialization. However, ANIL (almost no inner loop) algorithm shows that feature reuse is an alternative to rapid learning in MAML. Thus, the meta-initialization phase makes MAML primed for feature reuse and obviates the need for rapid learning. Contrary to ANIL, we hypothesize that there may be a need to learn new features during meta-testing. A new unseen task from non-similar distribution would necessitate rapid learning in addition reuse and recombination of existing features. In this paper, we invoke the width-depth duality of neural networks, wherein, we increase the width of the network by adding extra computational units (ACU). The ACUs enable the learning of new atomic features in the meta-testing task, and the associated increased width facilitates information propagation in the forwarding pass. The newly learnt features combine with existing features in the last layer for meta-learning. Experimental results show that our proposed MAC method outperformed existing ANIL algorithm for non-similar task distribution by approximately 13% (5-shot task setting)
Read more5/28/2024
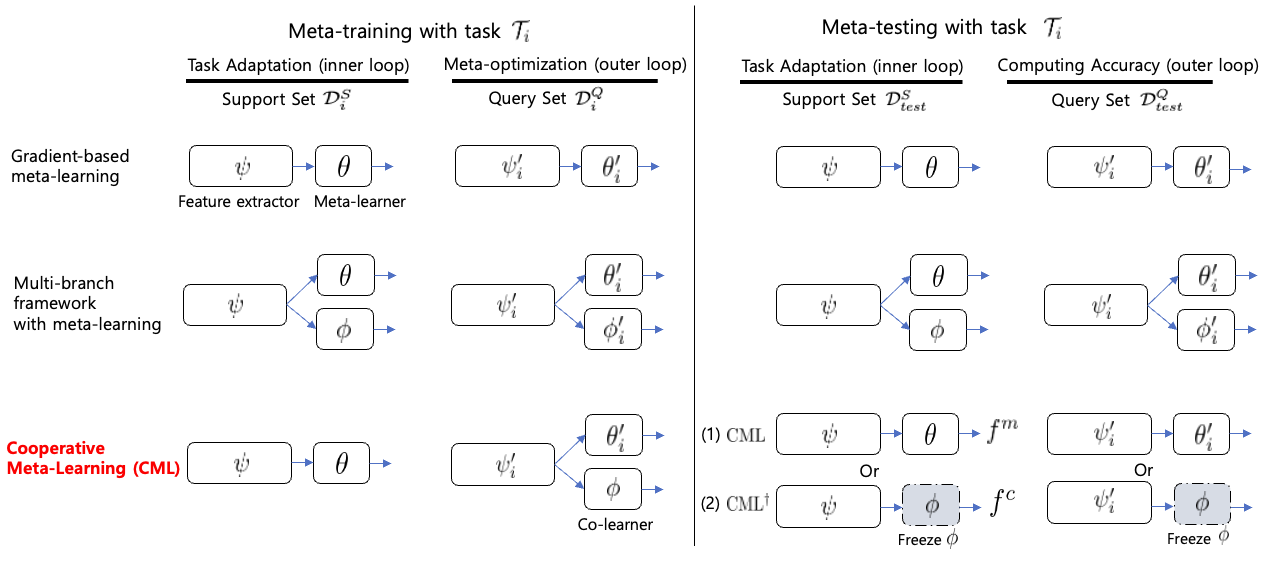
0
Cooperative Meta-Learning with Gradient Augmentation
Jongyun Shin, Seunjin Han, Jangho Kim
Model agnostic meta-learning (MAML) is one of the most widely used gradient-based meta-learning, consisting of two optimization loops: an inner loop and outer loop. MAML learns the new task from meta-initialization parameters with an inner update and finds the meta-initialization parameters in the outer loop. In general, the injection of noise into the gradient of the model for augmenting the gradient is one of the widely used regularization methods. In this work, we propose a novel cooperative meta-learning framework dubbed CML which leverages gradient-level regularization with gradient augmentation. We inject learnable noise into the gradient of the model for the model generalization. The key idea of CML is introducing the co-learner which has no inner update but the outer loop update to augment gradients for finding better meta-initialization parameters. Since the co-learner does not update in the inner loop, it can be easily deleted after meta-training. Therefore, CML infers with only meta-learner without additional cost and performance degradation. We demonstrate that CML is easily applicable to gradient-based meta-learning methods and CML leads to increased performance in few-shot regression, few-shot image classification and few-shot node classification tasks. Our codes are at https://github.com/JJongyn/CML.
Read more6/10/2024

0
MAML-en-LLM: Model Agnostic Meta-Training of LLMs for Improved In-Context Learning
Sanchit Sinha, Yuguang Yue, Victor Soto, Mayank Kulkarni, Jianhua Lu, Aidong Zhang
Adapting large language models (LLMs) to unseen tasks with in-context training samples without fine-tuning remains an important research problem. To learn a robust LLM that adapts well to unseen tasks, multiple meta-training approaches have been proposed such as MetaICL and MetaICT, which involve meta-training pre-trained LLMs on a wide variety of diverse tasks. These meta-training approaches essentially perform in-context multi-task fine-tuning and evaluate on a disjointed test set of tasks. Even though they achieve impressive performance, their goal is never to compute a truly general set of parameters. In this paper, we propose MAML-en-LLM, a novel method for meta-training LLMs, which can learn truly generalizable parameters that not only perform well on disjointed tasks but also adapts to unseen tasks. We see an average increase of 2% on unseen domains in the performance while a massive 4% improvement on adaptation performance. Furthermore, we demonstrate that MAML-en-LLM outperforms baselines in settings with limited amount of training data on both seen and unseen domains by an average of 2%. Finally, we discuss the effects of type of tasks, optimizers and task complexity, an avenue barely explored in meta-training literature. Exhaustive experiments across 7 task settings along with two data settings demonstrate that models trained with MAML-en-LLM outperform SOTA meta-training approaches.
Read more5/21/2024