HYSYNTH: Context-Free LLM Approximation for Guiding Program Synthesis

0

Sign in to get full access
Overview
- This paper introduces \tool, a novel approach that harnesses the power of large language models (LLMs) to guide program synthesis.
- The key idea is to use an LLM to generate a context-free approximation of the target program, which can then be used to steer the program synthesis process.
- This approach aims to address the challenges of leveraging LLMs for program-by-example (PBE) tasks, where LLMs have struggled to generate code that satisfies complex input-output examples.
Plain English Explanation
The paper presents a technique called \tool that uses large language models (LLMs) to help create computer programs more efficiently. LLMs are powerful AI models that can understand and generate human-like text, but they have struggled when it comes to generating code that matches specific input-output examples in program-by-example (PBE) tasks.
To address this, the researchers developed \tool, which uses the LLM to generate a simplified, "context-free" approximation of the target program. This approximation acts as a guide, helping the program synthesis process converge more quickly on the desired program. By leveraging the LLM's natural language understanding capabilities in this way, \tool aims to harness the power of LLMs to make program synthesis more effective.
The key insight is that while LLMs may struggle to generate the exact program needed, they can still provide a useful high-level sketch or template that captures the overall structure and logic of the program. This "context-free" approximation can then be used to steer the program synthesis process towards the right solution, even if the LLM can't produce the complete, final program on its own.
Technical Explanation
The paper introduces \tool, a novel approach that leverages large language models (LLMs) to guide the program synthesis process. The key idea is to use an LLM to generate a context-free approximation of the target program, which can then be used to inform and steer the program synthesis process.
This approach addresses the challenges of using LLMs for program-by-example (PBE) tasks, where LLMs have struggled to generate code that satisfies complex input-output examples. The researchers hypothesize that while LLMs may not be able to directly produce the complete, final program, they can still provide a useful high-level sketch or template that captures the overall structure and logic of the program.
To implement \tool, the authors use a two-stage process. First, the LLM is prompted to generate a context-free approximation of the target program, which takes the form of a sequence of abstract tokens that represent the program's structure and control flow, but without any specific variable names or values. This approximation is then used to guide a program synthesis module, which searches for a concrete program that matches the provided input-output examples and is consistent with the LLM's high-level sketch.
The authors evaluate \tool on a range of PBE benchmarks and find that it outperforms state-of-the-art program synthesis approaches, particularly on more complex tasks. They attribute this improvement to the ability of the LLM-generated approximation to effectively steer the synthesis process towards the desired program.
Critical Analysis
The paper presents a promising approach to leveraging large language models for program synthesis tasks, but it also acknowledges several limitations and areas for further research.
One key limitation is that the quality of the LLM-generated approximation is critical to the success of the \tool approach. If the LLM fails to capture the essential structure and logic of the target program, the program synthesis module may still struggle to find the correct solution. The authors note that further research is needed to improve the accuracy and robustness of the LLM approximation generation.
Additionally, the current \tool implementation is limited to a relatively small domain of program synthesis tasks, and it's unclear how well the approach would scale to more complex, real-world programming problems. Extending \tool to handle a wider range of program synthesis scenarios, including tasks that require more sophisticated reasoning or longer-term planning, would be an important area for future work.
Another potential issue is the interpretability and explainability of the \tool system. While the LLM-generated approximation provides a useful high-level guide, it may not be transparent or easily understandable to human users. Developing techniques to better explain and justify the system's decisions could be valuable for building trust and enabling effective human-AI collaboration in program synthesis tasks.
Despite these limitations, the \tool approach represents an interesting and promising step forward in the effort to harness the power of large language models for program synthesis. By blending the strengths of LLMs and traditional program synthesis techniques, the researchers have demonstrated the potential for significant performance improvements on challenging PBE tasks.
Conclusion
The \tool paper introduces a novel approach to leveraging large language models for program synthesis, addressing the challenges of using LLMs in program-by-example tasks. By generating a context-free approximation of the target program, \tool is able to effectively guide the program synthesis process, leading to improved performance on a range of benchmarks.
While the paper acknowledges several limitations and areas for further research, the \tool approach represents an important step forward in the ongoing effort to integrate the capabilities of large language models with traditional program synthesis techniques. As LLMs continue to advance and become more widely adopted, approaches like \tool may play a key role in unlocking the full potential of these powerful AI models for a wide range of programming and software engineering tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HYSYNTH: Context-Free LLM Approximation for Guiding Program Synthesis
Shraddha Barke, Emmanuel Anaya Gonzalez, Saketh Ram Kasibatla, Taylor Berg-Kirkpatrick, Nadia Polikarpova
Many structured prediction and reasoning tasks can be framed as program synthesis problems, where the goal is to generate a program in a domain-specific language (DSL) that transforms input data into the desired output. Unfortunately, purely neural approaches, such as large language models (LLMs), often fail to produce fully correct programs in unfamiliar DSLs, while purely symbolic methods based on combinatorial search scale poorly to complex problems. Motivated by these limitations, we introduce a hybrid approach, where LLM completions for a given task are used to learn a task-specific, context-free surrogate model, which is then used to guide program synthesis. We evaluate this hybrid approach on three domains, and show that it outperforms both unguided search and direct sampling from LLMs, as well as existing program synthesizers.
Read more5/28/2024
💬
0
Guiding Enumerative Program Synthesis with Large Language Models
Yixuan Li, Julian Parsert, Elizabeth Polgreen
Pre-trained Large Language Models (LLMs) are beginning to dominate the discourse around automatic code generation with natural language specifications. In contrast, the best-performing synthesizers in the domain of formal synthesis with precise logical specifications are still based on enumerative algorithms. In this paper, we evaluate the abilities of LLMs to solve formal synthesis benchmarks by carefully crafting a library of prompts for the domain. When one-shot synthesis fails, we propose a novel enumerative synthesis algorithm, which integrates calls to an LLM into a weighted probabilistic search. This allows the synthesizer to provide the LLM with information about the progress of the enumerator, and the LLM to provide the enumerator with syntactic guidance in an iterative loop. We evaluate our techniques on benchmarks from the Syntax-Guided Synthesis (SyGuS) competition. We find that GPT-3.5 as a stand-alone tool for formal synthesis is easily outperformed by state-of-the-art formal synthesis algorithms, but our approach integrating the LLM into an enumerative synthesis algorithm shows significant performance gains over both the LLM and the enumerative synthesizer alone and the winning SyGuS competition tool.
Read more5/28/2024

0
SELF-GUIDE: Better Task-Specific Instruction Following via Self-Synthetic Finetuning
Chenyang Zhao, Xueying Jia, Vijay Viswanathan, Tongshuang Wu, Graham Neubig
Large language models (LLMs) hold the promise of solving diverse tasks when provided with appropriate natural language prompts. However, prompting often leads models to make predictions with lower accuracy compared to finetuning a model with ample training data. On the other hand, while finetuning LLMs on task-specific data generally improves their performance, abundant annotated datasets are not available for all tasks. Previous work has explored generating task-specific data from state-of-the-art LLMs and using this data to finetune smaller models, but this approach requires access to a language model other than the one being trained, which introduces cost, scalability challenges, and legal hurdles associated with continuously relying on more powerful LLMs. In response to these, we propose SELF-GUIDE, a multi-stage mechanism in which we synthesize task-specific input-output pairs from the student LLM, then use these input-output pairs to finetune the student LLM itself. In our empirical evaluation of the Natural Instructions V2 benchmark, we find that SELF-GUIDE improves the performance of LLM by a substantial margin. Specifically, we report an absolute improvement of approximately 15% for classification tasks and 18% for generation tasks in the benchmark's metrics. This sheds light on the promise of self-synthesized data guiding LLMs towards becoming task-specific experts without any external learning signals.
Read more8/13/2024
0
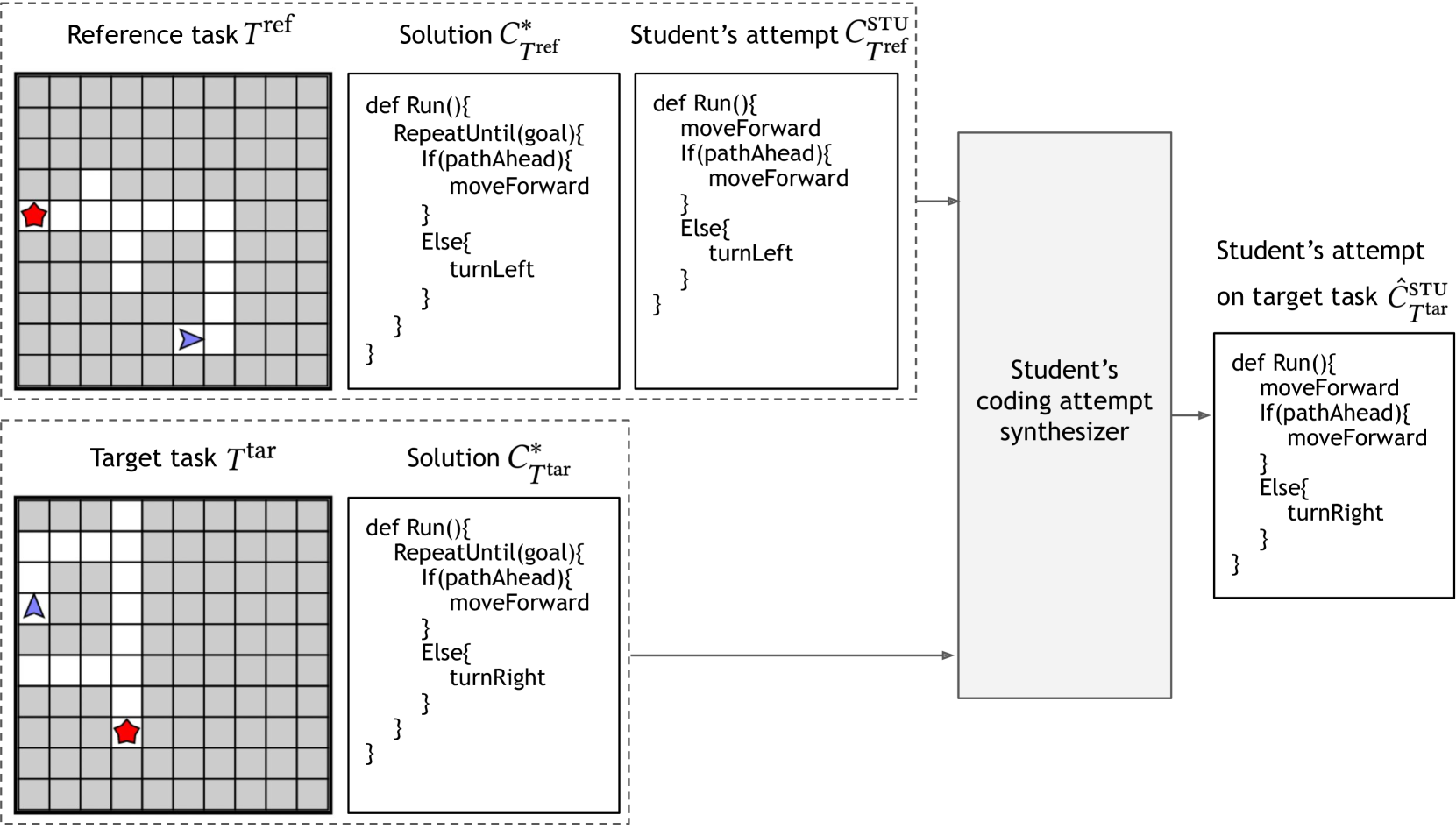
Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming
Manh Hung Nguyen, Sebastian Tschiatschek, Adish Singla
Student modeling is central to many educational technologies as it enables predicting future learning outcomes and designing targeted instructional strategies. However, open-ended learning domains pose challenges for accurately modeling students due to the diverse behaviors and a large space of possible misconceptions. To approach these challenges, we explore the application of large language models (LLMs) for in-context student modeling in open-ended learning domains. More concretely, given a particular student's attempt on a reference task as observation, the objective is to synthesize the student's attempt on a target task. We introduce a novel framework, LLM for Student Synthesis (LLM-SS), that leverages LLMs for synthesizing a student's behavior. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs to boost their student modeling capabilities. We instantiate several methods based on LLM-SS framework and evaluate them using an existing benchmark, StudentSyn, for student attempt synthesis in a visual programming domain. Experimental results show that our methods perform significantly better than the baseline method NeurSS provided in the StudentSyn benchmark. Furthermore, our method using a fine-tuned version of the GPT-3.5 model is significantly better than using the base GPT-3.5 model and gets close to human tutors' performance.
Read more5/7/2024