Guiding Enumerative Program Synthesis with Large Language Models

0
💬
Sign in to get full access
Overview
- This paper introduces a technique for guiding enumerative program synthesis using large language models.
- The approach aims to improve the efficiency and effectiveness of program synthesis by leveraging the powerful language understanding capabilities of large language models.
- The proposed method integrates a large language model with an enumerative program synthesizer to guide the synthesis process and generate more relevant program candidates.
Plain English Explanation
The paper describes a new way to generate computer programs using large language models, which are powerful AI systems trained on massive amounts of text data. Traditional program synthesis methods often rely on enumerating and testing many possible program candidates, which can be slow and inefficient.
The researchers' key idea is to use a large language model to provide guidance and direction to the program synthesis process. The language model, with its deep understanding of language and concepts, can help identify more promising program candidates and filter out less relevant ones. This allows the program synthesis system to work more efficiently and produce useful programs faster.
The approach combines the strengths of large language models, which excel at language understanding, with the program generation capabilities of enumerative synthesis. By integrating these two components, the researchers aim to create a more powerful and effective program synthesis system that can tackle complex programming tasks.
Technical Explanation
The paper presents a technique for guiding enumerative program synthesis with large language models. The key innovation is the integration of a large language model (LLM) with an enumerative program synthesizer to improve the efficiency and effectiveness of the synthesis process.
The researchers first train an LLM on a large corpus of code and natural language data. They then use this LLM to guide the enumerative search performed by the program synthesizer. Specifically, the LLM is used to score and rank the candidate programs generated by the synthesizer, allowing the system to focus on the most promising candidates.
The paper describes experiments evaluating the proposed approach on a set of programming tasks. The results show that the LLM-guided synthesis outperforms traditional enumerative synthesis, demonstrating the benefits of integrating large language models into program synthesis.
Critical Analysis
The paper presents a novel and promising approach for improving program synthesis by leveraging large language models. The key strength of the proposed method is its ability to guide the synthesis process using the rich language understanding capabilities of the LLM.
However, the paper also acknowledges several limitations and areas for further research. For example, the current approach relies on a context-free LLM, which may not fully capture the complexities of programming language syntax and semantics. Exploring the use of more advanced language models, such as those that can better handle context-dependent program structures, could be a fruitful direction for future work.
Additionally, the paper focuses on enumerative synthesis, which may not be the most efficient approach for all programming tasks. Investigating how the LLM-guided technique could be integrated with other program synthesis paradigms, such as neural program synthesis, could further expand the capabilities and applicability of the proposed method.
Conclusion
This paper presents a novel approach for guiding enumerative program synthesis using large language models. By integrating an LLM with a program synthesizer, the researchers have demonstrated a way to significantly improve the efficiency and effectiveness of program generation.
The results suggest that the synergistic combination of language understanding and program synthesis capabilities can lead to more powerful and versatile program generation systems. As large language models continue to advance, the integration of these models into program synthesis workflows could have far-reaching implications for software development, programming assistance, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Guiding Enumerative Program Synthesis with Large Language Models
Yixuan Li, Julian Parsert, Elizabeth Polgreen
Pre-trained Large Language Models (LLMs) are beginning to dominate the discourse around automatic code generation with natural language specifications. In contrast, the best-performing synthesizers in the domain of formal synthesis with precise logical specifications are still based on enumerative algorithms. In this paper, we evaluate the abilities of LLMs to solve formal synthesis benchmarks by carefully crafting a library of prompts for the domain. When one-shot synthesis fails, we propose a novel enumerative synthesis algorithm, which integrates calls to an LLM into a weighted probabilistic search. This allows the synthesizer to provide the LLM with information about the progress of the enumerator, and the LLM to provide the enumerator with syntactic guidance in an iterative loop. We evaluate our techniques on benchmarks from the Syntax-Guided Synthesis (SyGuS) competition. We find that GPT-3.5 as a stand-alone tool for formal synthesis is easily outperformed by state-of-the-art formal synthesis algorithms, but our approach integrating the LLM into an enumerative synthesis algorithm shows significant performance gains over both the LLM and the enumerative synthesizer alone and the winning SyGuS competition tool.
Read more5/28/2024

0
Large Language Models Synergize with Automated Machine Learning
Jinglue Xu, Jialong Li, Zhen Liu, Nagar Anthel Venkatesh Suryanarayanan, Guoyuan Zhou, Jia Guo, Hitoshi Iba, Kenji Tei
Recently, program synthesis driven by large language models (LLMs) has become increasingly popular. However, program synthesis for machine learning (ML) tasks still poses significant challenges. This paper explores a novel form of program synthesis, targeting ML programs, by combining LLMs and automated machine learning (autoML). Specifically, our goal is to fully automate the generation and optimization of the code of the entire ML workflow, from data preparation to modeling and post-processing, utilizing only textual descriptions of the ML tasks. To manage the length and diversity of ML programs, we propose to break each ML program into smaller, manageable parts. Each part is generated separately by the LLM, with careful consideration of their compatibilities. To ensure compatibilities, we design a testing technique for ML programs. Unlike traditional program synthesis, which typically relies on binary evaluations (i.e., correct or incorrect), evaluating ML programs necessitates more than just binary judgments. Our approach automates the numerical evaluation and optimization of these programs, selecting the best candidates through autoML techniques. In experiments across various ML tasks, our method outperforms existing methods in 10 out of 12 tasks for generating ML programs. In addition, autoML significantly improves the performance of the generated ML programs. In experiments, given the textual task description, our method, Text-to-ML, generates the complete and optimized ML program in a fully autonomous process. The implementation of our method is available at https://github.com/JLX0/llm-automl.
Read more9/10/2024
💬
0
Large Language Models as Evaluators for Scientific Synthesis
Julia Evans, Jennifer D'Souza, Soren Auer
Our study explores how well the state-of-the-art Large Language Models (LLMs), like GPT-4 and Mistral, can assess the quality of scientific summaries or, more fittingly, scientific syntheses, comparing their evaluations to those of human annotators. We used a dataset of 100 research questions and their syntheses made by GPT-4 from abstracts of five related papers, checked against human quality ratings. The study evaluates both the closed-source GPT-4 and the open-source Mistral model's ability to rate these summaries and provide reasons for their judgments. Preliminary results show that LLMs can offer logical explanations that somewhat match the quality ratings, yet a deeper statistical analysis shows a weak correlation between LLM and human ratings, suggesting the potential and current limitations of LLMs in scientific synthesis evaluation.
Read more7/4/2024
0
Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming
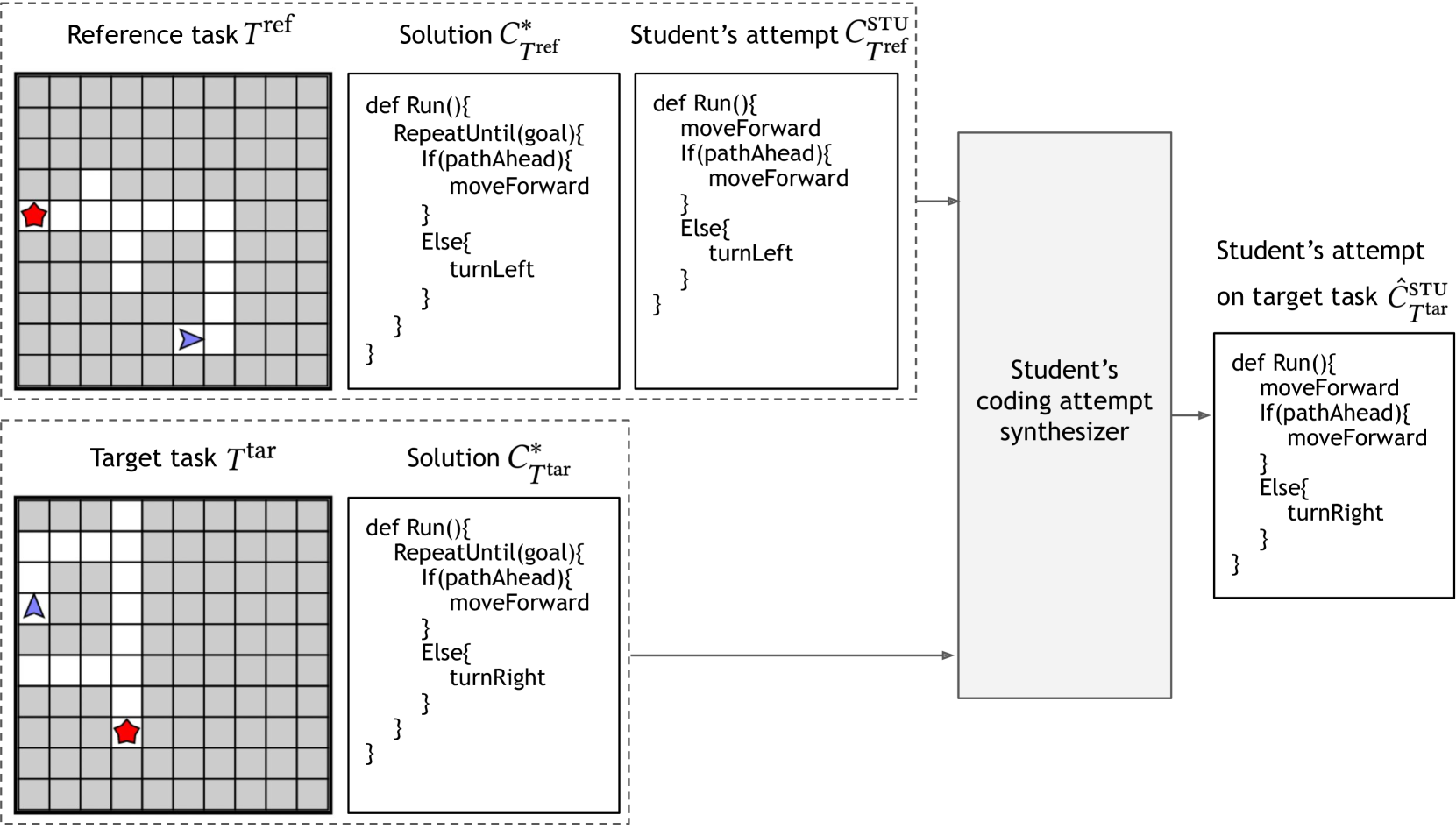
Manh Hung Nguyen, Sebastian Tschiatschek, Adish Singla
Student modeling is central to many educational technologies as it enables predicting future learning outcomes and designing targeted instructional strategies. However, open-ended learning domains pose challenges for accurately modeling students due to the diverse behaviors and a large space of possible misconceptions. To approach these challenges, we explore the application of large language models (LLMs) for in-context student modeling in open-ended learning domains. More concretely, given a particular student's attempt on a reference task as observation, the objective is to synthesize the student's attempt on a target task. We introduce a novel framework, LLM for Student Synthesis (LLM-SS), that leverages LLMs for synthesizing a student's behavior. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs to boost their student modeling capabilities. We instantiate several methods based on LLM-SS framework and evaluate them using an existing benchmark, StudentSyn, for student attempt synthesis in a visual programming domain. Experimental results show that our methods perform significantly better than the baseline method NeurSS provided in the StudentSyn benchmark. Furthermore, our method using a fine-tuned version of the GPT-3.5 model is significantly better than using the base GPT-3.5 model and gets close to human tutors' performance.
Read more5/7/2024