I understand why I got this grade: Automatic Short Answer Grading with Feedback

0

Sign in to get full access
Overview
This paper presents an approach for automatically grading short-answer responses with accompanying feedback. The researchers developed a model that can assess the quality of student answers and provide personalized explanations for the grades. This could help students better understand their performance and learn from their mistakes.
Plain English Explanation
The researchers created an AI system that can grade short written responses, like those given in classroom assignments or exams. This system not only assigns a grade, but also provides feedback to explain why the student received that particular grade.
The key idea is to give students more insight into their performance. Rather than just seeing a number or letter grade, they get detailed comments on what they did well and what they could improve. This allows students to understand the reasoning behind their scores, rather than just accepting them at face value.
The paper on automated long-answer grading and the research on explainable AI grading models are related to this work, as they also explore ways to make grading more transparent and informative for students.
Technical Explanation
The researchers developed a deep learning model that can assess the quality of short-answer responses and generate accompanying feedback. They used a novel architecture that combines language models with scoring and explanation modules.
The model first encodes the student's answer and the reference answer into vector representations. It then passes these through scoring and explanation networks to generate a grade and feedback text. The scoring network predicts an overall score, while the explanation network identifies specific strengths and weaknesses in the student's response.
The researchers trained and evaluated their model on a dataset of short-answer questions from an online course. They found that it was able to provide accurate grades and generate feedback that aligned well with human-provided explanations.
Critical Analysis
One limitation of this work is that the feedback generated by the model may not always be fully accurate or insightful. While the researchers showed that the feedback aligned with human raters on average, there may still be cases where the model misunderstands the student's response or provides suboptimal guidance.
Additionally, the dataset used for training and evaluation was relatively small, so the model's performance may not generalize as well to larger-scale, real-world applications. Further research would be needed to assess the model's scalability and robustness.
Another potential issue is the interpretability of the model's inner workings. While the researchers aimed to make the grading process more transparent, the neural network architecture may still be opaque in some ways. Auditing techniques for automatic grading models could help address this concern.
Conclusion
This research demonstrates the potential of AI-powered grading systems to provide students with more detailed and informative feedback. By combining language understanding, scoring, and explanation capabilities, the model can give students a clearer sense of their strengths and weaknesses.
While further work is needed to improve the accuracy and reliability of such systems, this paper represents an important step towards automating the grading of short-text answers in a way that enhances learning and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
I understand why I got this grade: Automatic Short Answer Grading with Feedback
Dishank Aggarwal, Pushpak Bhattacharyya, Bhaskaran Raman
The demand for efficient and accurate assessment methods has intensified as education systems transition to digital platforms. Providing feedback is essential in educational settings and goes beyond simply conveying marks as it justifies the assigned marks. In this context, we present a significant advancement in automated grading by introducing Engineering Short Answer Feedback (EngSAF) -- a dataset of 5.8k student answers accompanied by reference answers and questions for the Automatic Short Answer Grading (ASAG) task. The EngSAF dataset is meticulously curated to cover a diverse range of subjects, questions, and answer patterns from multiple engineering domains. We leverage state-of-the-art large language models' (LLMs) generative capabilities with our Label-Aware Synthetic Feedback Generation (LASFG) strategy to include feedback in our dataset. This paper underscores the importance of enhanced feedback in practical educational settings, outlines dataset annotation and feedback generation processes, conducts a thorough EngSAF analysis, and provides different LLMs-based zero-shot and finetuned baselines for future comparison. Additionally, we demonstrate the efficiency and effectiveness of the ASAG system through its deployment in a real-world end-semester exam at the Indian Institute of Technology Bombay (IITB), showcasing its practical viability and potential for broader implementation in educational institutions.
Read more7/19/2024

0
Beyond human subjectivity and error: a novel AI grading system
Alexandra Gobrecht, Felix Tuma, Moritz Moller, Thomas Zoller, Mark Zakhvatkin, Alexandra Wuttig, Holger Sommerfeldt, Sven Schutt
The grading of open-ended questions is a high-effort, high-impact task in education. Automating this task promises a significant reduction in workload for education professionals, as well as more consistent grading outcomes for students, by circumventing human subjectivity and error. While recent breakthroughs in AI technology might facilitate such automation, this has not been demonstrated at scale. It this paper, we introduce a novel automatic short answer grading (ASAG) system. The system is based on a fine-tuned open-source transformer model which we trained on large set of exam data from university courses across a large range of disciplines. We evaluated the trained model's performance against held-out test data in a first experiment and found high accuracy levels across a broad spectrum of unseen questions, even in unseen courses. We further compared the performance of our model with that of certified human domain experts in a second experiment: we first assembled another test dataset from real historical exams - the historic grades contained in that data were awarded to students in a regulated, legally binding examination process; we therefore considered them as ground truth for our experiment. We then asked certified human domain experts and our model to grade the historic student answers again without disclosing the historic grades. Finally, we compared the hence obtained grades with the historic grades (our ground truth). We found that for the courses examined, the model deviated less from the official historic grades than the human re-graders - the model's median absolute error was 44 % smaller than the human re-graders', implying that the model is more consistent than humans in grading. These results suggest that leveraging AI enhanced grading can reduce human subjectivity, improve consistency and thus ultimately increase fairness.
Read more5/8/2024
🌿
0
Towards LLM-based Autograding for Short Textual Answers
Johannes Schneider, Bernd Schenk, Christina Niklaus
Grading exams is an important, labor-intensive, subjective, repetitive, and frequently challenging task. The feasibility of autograding textual responses has greatly increased thanks to the availability of large language models (LLMs) such as ChatGPT and the substantial influx of data brought about by digitalization. However, entrusting AI models with decision-making roles raises ethical considerations, mainly stemming from potential biases and issues related to generating false information. Thus, in this manuscript, we provide an evaluation of a large language model for the purpose of autograding, while also highlighting how LLMs can support educators in validating their grading procedures. Our evaluation is targeted towards automatic short textual answers grading (ASAG), spanning various languages and examinations from two distinct courses. Our findings suggest that while out-of-the-box LLMs provide a valuable tool to provide a complementary perspective, their readiness for independent automated grading remains a work in progress, necessitating human oversight.
Read more7/9/2024
0
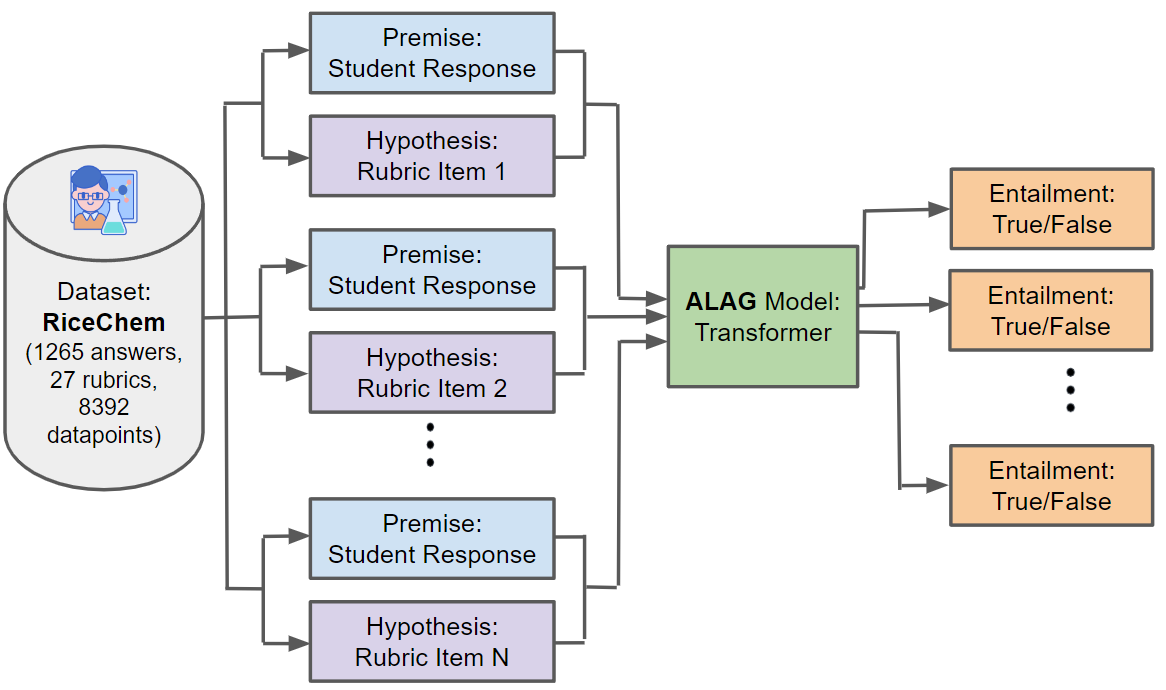
Automated Long Answer Grading with RiceChem Dataset
Shashank Sonkar, Kangqi Ni, Lesa Tran Lu, Kristi Kincaid, John S. Hutchinson, Richard G. Baraniuk
We introduce a new area of study in the field of educational Natural Language Processing: Automated Long Answer Grading (ALAG). Distinguishing itself from Automated Short Answer Grading (ASAG) and Automated Essay Grading (AEG), ALAG presents unique challenges due to the complexity and multifaceted nature of fact-based long answers. To study ALAG, we introduce RiceChem, a dataset derived from a college chemistry course, featuring real student responses to long-answer questions with an average word count notably higher than typical ASAG datasets. We propose a novel approach to ALAG by formulating it as a rubric entailment problem, employing natural language inference models to verify whether each criterion, represented by a rubric item, is addressed in the student's response. This formulation enables the effective use of MNLI for transfer learning, significantly improving the performance of models on the RiceChem dataset. We demonstrate the importance of rubric-based formulation in ALAG, showcasing its superiority over traditional score-based approaches in capturing the nuances of student responses. We also investigate the performance of models in cold start scenarios, providing valuable insights into the practical deployment considerations in educational settings. Lastly, we benchmark state-of-the-art open-sourced Large Language Models (LLMs) on RiceChem and compare their results to GPT models, highlighting the increased complexity of ALAG compared to ASAG. Despite leveraging the benefits of a rubric-based approach and transfer learning from MNLI, the lower performance of LLMs on RiceChem underscores the significant difficulty posed by the ALAG task. With this work, we offer a fresh perspective on grading long, fact-based answers and introduce a new dataset to stimulate further research in this important area. Code: url{https://github.com/luffycodes/Automated-Long-Answer-Grading}.
Read more4/23/2024