Automated Long Answer Grading with RiceChem Dataset

0
Sign in to get full access
Overview
- This paper presents a new dataset called RiceChem for automated long answer grading (ALAG)
- The dataset contains long-form chemistry answers that have been manually graded
- The authors propose several neural network models for ALAG using the RiceChem dataset
- The models aim to automatically grade long-form chemistry answers with high accuracy
Plain English Explanation
The researchers created a new dataset called RiceChem that contains long, written answers to chemistry questions. These answers have been carefully graded by human experts. The researchers then developed several machine learning models that can automatically grade these long answers, without human intervention.
The goal is to create AI systems that can accurately evaluate lengthy, open-ended responses, similar to how a human teacher would grade an essay or short-answer question. This could be useful for improved medical reasoning or generating multilingual question-answering datasets. The researchers tested different neural network architectures to see which ones work best for this task of automated long answer grading.
Technical Explanation
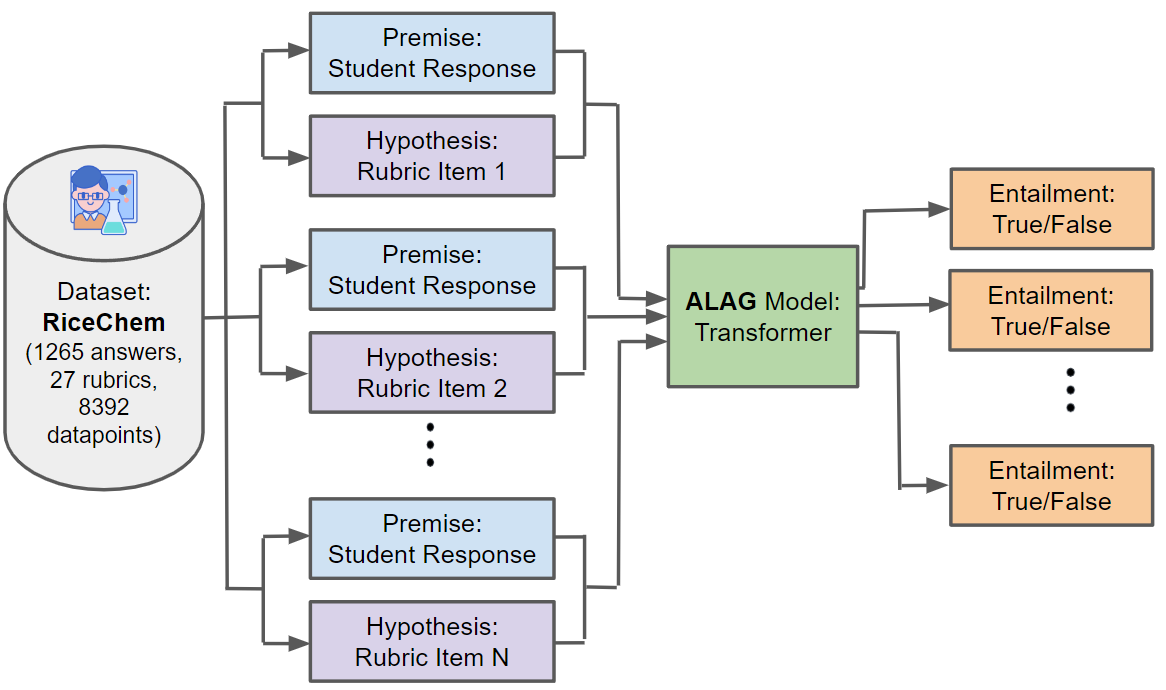
The paper introduces the RiceChem dataset, which contains over 5,000 long-form answers to chemistry questions. Each answer has been manually graded by experts on a scale from 0-5. The authors formulate the task as a regression problem, where the goal is to predict the grading score given the text of the answer.
They experiment with several neural network models, including a BERT-based approach, a BiLSTM with attention, and a Transformer-based model. The models take the text of the answer as input and output a predicted score. The authors evaluate the models using metrics like mean squared error and Pearson correlation.
Their results show that the Transformer-based model achieves the best performance, outperforming the other architectures. They also find that explicitly modeling the cohesive structure of the answers can further improve accuracy.
Critical Analysis
The paper makes a valuable contribution by introducing a new dataset and exploring neural network approaches for automated long answer grading. The RiceChem dataset fills an important gap, as most prior work has focused on shorter, more constrained answer formats.
However, the authors acknowledge several limitations. The dataset is relatively small, with only a few thousand examples, which may limit the models' ability to generalize. Additionally, the grading scheme is relatively coarse-grained, using a 0-5 scale, which may oversimplify the nuances of evaluating lengthy responses.
Further research could explore ways to expand the dataset, either by collecting more examples or by incorporating additional metadata or features. Investigating more advanced natural language processing techniques, such as retrieval-augmented generation, could also lead to improvements in model performance.
Additionally, the paper does not delve into the interpretability or explainability of the models. Understanding why the models make the predictions they do could be valuable for building trust in these automated grading systems, particularly in high-stakes educational or professional settings.
Conclusion
This paper presents a new dataset and models for the task of automated long answer grading in chemistry. The RiceChem dataset and the proposed neural network approaches represent an important step forward in developing AI systems that can accurately evaluate open-ended, lengthy responses.
While the current results are promising, there is still room for improvement, both in terms of dataset size and model capabilities. Further research in this area could lead to advancements in automated prediction of item difficulty and help to make educational and professional assessment more efficient and scalable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automated Long Answer Grading with RiceChem Dataset
Shashank Sonkar, Kangqi Ni, Lesa Tran Lu, Kristi Kincaid, John S. Hutchinson, Richard G. Baraniuk
We introduce a new area of study in the field of educational Natural Language Processing: Automated Long Answer Grading (ALAG). Distinguishing itself from Automated Short Answer Grading (ASAG) and Automated Essay Grading (AEG), ALAG presents unique challenges due to the complexity and multifaceted nature of fact-based long answers. To study ALAG, we introduce RiceChem, a dataset derived from a college chemistry course, featuring real student responses to long-answer questions with an average word count notably higher than typical ASAG datasets. We propose a novel approach to ALAG by formulating it as a rubric entailment problem, employing natural language inference models to verify whether each criterion, represented by a rubric item, is addressed in the student's response. This formulation enables the effective use of MNLI for transfer learning, significantly improving the performance of models on the RiceChem dataset. We demonstrate the importance of rubric-based formulation in ALAG, showcasing its superiority over traditional score-based approaches in capturing the nuances of student responses. We also investigate the performance of models in cold start scenarios, providing valuable insights into the practical deployment considerations in educational settings. Lastly, we benchmark state-of-the-art open-sourced Large Language Models (LLMs) on RiceChem and compare their results to GPT models, highlighting the increased complexity of ALAG compared to ASAG. Despite leveraging the benefits of a rubric-based approach and transfer learning from MNLI, the lower performance of LLMs on RiceChem underscores the significant difficulty posed by the ALAG task. With this work, we offer a fresh perspective on grading long, fact-based answers and introduce a new dataset to stimulate further research in this important area. Code: url{https://github.com/luffycodes/Automated-Long-Answer-Grading}.
Read more4/23/2024
🌿
0
Towards LLM-based Autograding for Short Textual Answers
Johannes Schneider, Bernd Schenk, Christina Niklaus
Grading exams is an important, labor-intensive, subjective, repetitive, and frequently challenging task. The feasibility of autograding textual responses has greatly increased thanks to the availability of large language models (LLMs) such as ChatGPT and the substantial influx of data brought about by digitalization. However, entrusting AI models with decision-making roles raises ethical considerations, mainly stemming from potential biases and issues related to generating false information. Thus, in this manuscript, we provide an evaluation of a large language model for the purpose of autograding, while also highlighting how LLMs can support educators in validating their grading procedures. Our evaluation is targeted towards automatic short textual answers grading (ASAG), spanning various languages and examinations from two distinct courses. Our findings suggest that while out-of-the-box LLMs provide a valuable tool to provide a complementary perspective, their readiness for independent automated grading remains a work in progress, necessitating human oversight.
Read more7/9/2024

0
I understand why I got this grade: Automatic Short Answer Grading with Feedback
Dishank Aggarwal, Pushpak Bhattacharyya, Bhaskaran Raman
The demand for efficient and accurate assessment methods has intensified as education systems transition to digital platforms. Providing feedback is essential in educational settings and goes beyond simply conveying marks as it justifies the assigned marks. In this context, we present a significant advancement in automated grading by introducing Engineering Short Answer Feedback (EngSAF) -- a dataset of 5.8k student answers accompanied by reference answers and questions for the Automatic Short Answer Grading (ASAG) task. The EngSAF dataset is meticulously curated to cover a diverse range of subjects, questions, and answer patterns from multiple engineering domains. We leverage state-of-the-art large language models' (LLMs) generative capabilities with our Label-Aware Synthetic Feedback Generation (LASFG) strategy to include feedback in our dataset. This paper underscores the importance of enhanced feedback in practical educational settings, outlines dataset annotation and feedback generation processes, conducts a thorough EngSAF analysis, and provides different LLMs-based zero-shot and finetuned baselines for future comparison. Additionally, we demonstrate the efficiency and effectiveness of the ASAG system through its deployment in a real-world end-semester exam at the Indian Institute of Technology Bombay (IITB), showcasing its practical viability and potential for broader implementation in educational institutions.
Read more7/19/2024
💬
0
Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation
Gauthier Guinet, Behrooz Omidvar-Tehrani, Anoop Deoras, Laurent Callot
We propose a new method to measure the task-specific accuracy of Retrieval-Augmented Large Language Models (RAG). Evaluation is performed by scoring the RAG on an automatically-generated synthetic exam composed of multiple choice questions based on the corpus of documents associated with the task. Our method is an automated, cost-efficient, interpretable, and robust strategy to select the optimal components for a RAG system. We leverage Item Response Theory (IRT) to estimate the quality of an exam and its informativeness on task-specific accuracy. IRT also provides a natural way to iteratively improve the exam by eliminating the exam questions that are not sufficiently informative about a model's ability. We demonstrate our approach on four new open-ended Question-Answering tasks based on Arxiv abstracts, StackExchange questions, AWS DevOps troubleshooting guides, and SEC filings. In addition, our experiments reveal more general insights into factors impacting RAG performance like size, retrieval mechanism, prompting and fine-tuning. Most notably, our findings show that choosing the right retrieval algorithms often leads to bigger performance gains than simply using a larger language model.
Read more5/24/2024