I2AM: Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps

0

Sign in to get full access
Overview
- This paper introduces I2AM, a method for interpreting image-to-image diffusion models by generating attribution maps.
- The authors propose a technique to visualize which parts of the input image are most influential in the generation process.
- The method is evaluated on various image-to-image tasks, including image translation, super-resolution, and conditional generation.
- The results show that I2AM can provide valuable insights into the inner workings of these complex models.
Plain English Explanation
The paper discusses a new way to understand how image-to-image diffusion models work. Diffusion models are a type of AI system that can generate new images based on an input image. However, it's often hard to know what parts of the input image are most important for the model when it's generating the output.
The researchers developed a technique called I2AM that can create "attribution maps" to show which regions of the input image had the biggest influence on the final generated image. This allows people to see what the model is focusing on and understand its reasoning better.
The researchers tested I2AM on different tasks like image translation, super-resolution, and conditional generation. The results showed that I2AM can provide useful insights into how these complex AI systems work under the hood.
Technical Explanation
The paper introduces a method called I2AM (Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps) for visualizing the attribution maps of image-to-image diffusion models. The key idea is to backpropagate gradients through the diffusion process to identify the most influential regions of the input image that contributed to the final generated output.
Specifically, the authors propose a gradient-based attribution technique that computes the gradients of the output image with respect to the input image. These gradients are then used to generate an attribution map that highlights the salient regions of the input that had the greatest impact on the generation. The authors evaluate I2AM on a variety of image-to-image tasks, including image translation, super-resolution, and conditional generation.
The results demonstrate that I2AM can provide valuable interpretability insights into the inner workings of these complex diffusion models. The attribution maps generated by I2AM help reveal which parts of the input image were most influential in producing the final output, shedding light on the model's decision-making process.
Critical Analysis
The paper presents a thorough and well-designed study on interpreting image-to-image diffusion models. The authors provide a principled gradient-based attribution technique that can be applied to a variety of diffusion-based tasks. The evaluations on different applications, such as image translation, super-resolution, and conditional generation, demonstrate the versatility and effectiveness of the I2AM approach.
However, the paper does not address some potential limitations of the method. For example, it's unclear how well I2AM would perform on more complex or abstract image generation tasks, where the relationship between the input and output may be less straightforward. Additionally, the paper does not explore how the attribution maps could be used to improve the models themselves, such as by guiding the model architecture or training process.
Future research could investigate ways to further enhance the interpretability of diffusion models, perhaps by combining I2AM with other interpretability techniques like GenZIQA or by exploring how the attribution maps can be used to debug and refine the models. Overall, this paper represents a valuable contribution to the growing field of interpreting complex AI systems.
Conclusion
The I2AM method presented in this paper offers a powerful way to interpret the inner workings of image-to-image diffusion models. By generating attribution maps that highlight the most influential regions of the input image, I2AM provides valuable insights into how these models make decisions and generate their outputs.
The evaluations on a range of tasks demonstrate the versatility and effectiveness of the I2AM approach. While the paper does not address all potential limitations, it represents an important step forward in the quest to make complex AI systems more interpretable and transparent.
As the field of AI continues to advance, techniques like I2AM will become increasingly important for helping researchers, developers, and end-users understand and trust the models they are working with. This paper lays the groundwork for further advancements in interpretable AI, and its findings are likely to have a significant impact on the future development of image-to-image diffusion models and other AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
I2AM: Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps
Junseo Park, Hyeryung Jang
Large-scale diffusion models have made significant advancements in the field of image generation, especially through the use of cross-attention mechanisms that guide image formation based on textual descriptions. While the analysis of text-guided cross-attention in diffusion models has been extensively studied in recent years, its application in image-to-image diffusion models remains underexplored. This paper introduces the Image-to-Image Attribution Maps I2AM method, which aggregates patch-level cross-attention scores to enhance the interpretability of latent diffusion models across time steps, heads, and attention layers. I2AM facilitates detailed image-to-image attribution analysis, enabling observation of how diffusion models prioritize key features over time and head during the image generation process from reference images. Through extensive experiments, we first visualize the attribution maps of both generated and reference images, verifying that critical information from the reference image is effectively incorporated into the generated image, and vice versa. To further assess our understanding, we introduce a new evaluation metric tailored for reference-based image inpainting tasks. This metric, measuring the consistency between the attribution maps of generated and reference images, shows a strong correlation with established performance metrics for inpainting tasks, validating the potential use of I2AM in future research endeavors.
Read more7/18/2024
0
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
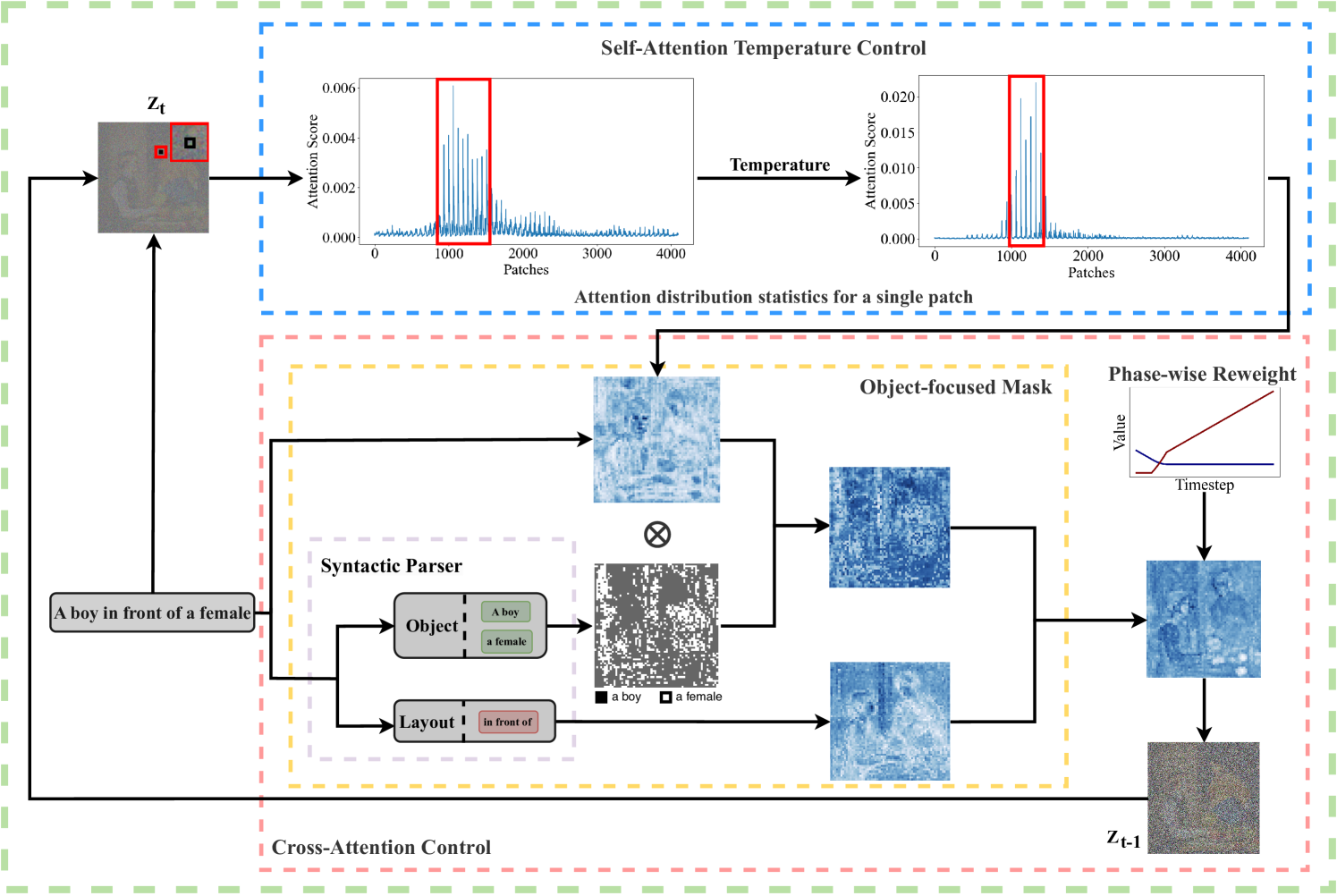
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
Read more4/23/2024

0
Training-Free Sketch-Guided Diffusion with Latent Optimization
Sandra Zhang Ding, Jiafeng Mao, Kiyoharu Aizawa
Based on recent advanced diffusion models, Text-to-image (T2I) generation models have demonstrated their capabilities in generating diverse and high-quality images. However, leveraging their potential for real-world content creation, particularly in providing users with precise control over the image generation result, poses a significant challenge. In this paper, we propose an innovative training-free pipeline that extends existing text-to-image generation models to incorporate a sketch as an additional condition. To generate new images with a layout and structure closely resembling the input sketch, we find that these core features of a sketch can be tracked with the cross-attention maps of diffusion models. We introduce latent optimization, a method that refines the noisy latent at each intermediate step of the generation process using cross-attention maps to ensure that the generated images closely adhere to the desired structure outlined in the reference sketch. Through latent optimization, our method enhances the fidelity and accuracy of image generation, offering users greater control and customization options in content creation.
Read more9/4/2024
🧠
0
Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
Jingyao Xu, Yuetong Lu, Yandong Li, Siyang Lu, Dongdong Wang, Xiang Wei
Diffusion models (DMs) embark a new era of generative modeling and offer more opportunities for efficient generating high-quality and realistic data samples. However, their widespread use has also brought forth new challenges in model security, which motivates the creation of more effective adversarial attackers on DMs to understand its vulnerability. We propose CAAT, a simple but generic and efficient approach that does not require costly training to effectively fool latent diffusion models (LDMs). The approach is based on the observation that cross-attention layers exhibits higher sensitivity to gradient change, allowing for leveraging subtle perturbations on published images to significantly corrupt the generated images. We show that a subtle perturbation on an image can significantly impact the cross-attention layers, thus changing the mapping between text and image during the fine-tuning of customized diffusion models. Extensive experiments demonstrate that CAAT is compatible with diverse diffusion models and outperforms baseline attack methods in a more effective (more noise) and efficient (twice as fast as Anti-DreamBooth and Mist) manner.
Read more6/17/2024