I2CANSAY:Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning
2404.13576
0
0

Abstract
Online task-free continual learning (OTFCL) is a more challenging variant of continual learning which emphasizes the gradual shift of task boundaries and learns in an online mode. Existing methods rely on a memory buffer composed of old samples to prevent forgetting. However,the use of memory buffers not only raises privacy concerns but also hinders the efficient learning of new samples. To address this problem, we propose a novel framework called I2CANSAY that gets rid of the dependence on memory buffers and efficiently learns the knowledge of new data from one-shot samples. Concretely, our framework comprises two main modules. Firstly, the Inter-Class Analogical Augmentation (ICAN) module generates diverse pseudo-features for old classes based on the inter-class analogy of feature distributions for different new classes, serving as a substitute for the memory buffer. Secondly, the Intra-Class Significance Analysis (ISAY) module analyzes the significance of attributes for each class via its distribution standard deviation, and generates the importance vector as a correction bias for the linear classifier, thereby enhancing the capability of learning from new samples. We run our experiments on four popular image classification datasets: CoRe50, CIFAR-10, CIFAR-100, and CUB-200, our approach outperforms the prior state-of-the-art by a large margin.
Create account to get full access
Overview
- This paper proposes a novel continual learning approach called I²CANSAY (Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning).
- The key ideas are: 1) using inter-class analogical augmentation to generate new training examples, and 2) performing intra-class significance analysis to identify important features within each class.
- The approach aims to enable continual learning without storing past task examples, which is a common limitation in many existing continual learning methods.
Plain English Explanation
The paper tackles the challenge of continual learning, which is the ability for an AI system to continuously learn new information without forgetting what it has learned before. Many existing continual learning methods require storing examples from past tasks, which can be impractical or even impossible in some real-world scenarios.
The proposed I²CANSAY approach has two main components. The first is inter-class analogical augmentation, which generates new training examples by finding similarities between different classes. This helps the model learn more efficiently without needing to store past examples. The second component is intra-class significance analysis, which identifies the most important features within each class. This allows the model to focus on the key characteristics of each class, rather than trying to memorize all the details.
By using these techniques, the I²CANSAY approach is able to perform continual learning without relying on stored past examples. This makes it more practical for real-world applications where data storage may be limited. The paper demonstrates the effectiveness of I²CANSAY through experiments on several benchmark datasets.
Technical Explanation
The paper proposes the I²CANSAY (Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning) approach to address the limitations of existing continual learning methods that require storing past task examples.
The key components of I²CANSAY are:
-
Inter-Class Analogical Augmentation: The method uses analogical reasoning to generate new training examples by finding similarities between different classes. This helps the model learn more effectively without needing to store past examples.
-
Intra-Class Significance Analysis: The approach analyzes the importance of different features within each class, allowing the model to focus on the most relevant characteristics rather than trying to memorize all the details.
The authors evaluate I²CANSAY on several benchmark continual learning datasets, including CIFAR-100, iCIFAR-100, and miniImageNet. The results demonstrate that I²CANSAY outperforms existing continual learning methods in terms of accuracy and efficiency, without requiring the storage of past task examples.
Critical Analysis
The paper presents a novel and promising approach to continual learning that addresses the common limitation of storing past task examples. The use of inter-class analogical augmentation and intra-class significance analysis are both interesting and well-motivated ideas.
However, the paper does not discuss potential limitations or caveats of the I²CANSAY approach. For example, it would be useful to understand how the method performs on more complex or diverse datasets, or how it might handle cases where the task distribution shifts significantly over time.
Additionally, the authors could have explored the trade-offs between the computational overhead of the augmentation and significance analysis components, and the benefits in terms of improved continual learning performance.
Overall, the paper makes a valuable contribution to the field of continual learning, but further research is needed to fully understand the strengths, weaknesses, and broader applicability of the I²CANSAY approach.
Conclusion
The I²CANSAY approach presented in this paper offers a novel solution to the problem of continual learning without the need to store past task examples. By leveraging inter-class analogical augmentation and intra-class significance analysis, the method is able to achieve strong performance on benchmark datasets while avoiding the storage limitations of many existing continual learning techniques.
The key ideas behind I²CANSAY, if further developed and refined, have the potential to significantly advance the state of the art in continual learning and enable more practical real-world applications of this important AI capability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Analogist: Out-of-the-box Visual In-Context Learning with Image Diffusion Model
Zheng Gu, Shiyuan Yang, Jing Liao, Jing Huo, Yang Gao
0
0
Visual In-Context Learning (ICL) has emerged as a promising research area due to its capability to accomplish various tasks with limited example pairs through analogical reasoning. However, training-based visual ICL has limitations in its ability to generalize to unseen tasks and requires the collection of a diverse task dataset. On the other hand, existing methods in the inference-based visual ICL category solely rely on textual prompts, which fail to capture fine-grained contextual information from given examples and can be time-consuming when converting from images to text prompts. To address these challenges, we propose Analogist, a novel inference-based visual ICL approach that exploits both visual and textual prompting techniques using a text-to-image diffusion model pretrained for image inpainting. For visual prompting, we propose a self-attention cloning (SAC) method to guide the fine-grained structural-level analogy between image examples. For textual prompting, we leverage GPT-4V's visual reasoning capability to efficiently generate text prompts and introduce a cross-attention masking (CAM) operation to enhance the accuracy of semantic-level analogy guided by text prompts. Our method is out-of-the-box and does not require fine-tuning or optimization. It is also generic and flexible, enabling a wide range of visual tasks to be performed in an in-context manner. Extensive experiments demonstrate the superiority of our method over existing approaches, both qualitatively and quantitatively.
5/17/2024
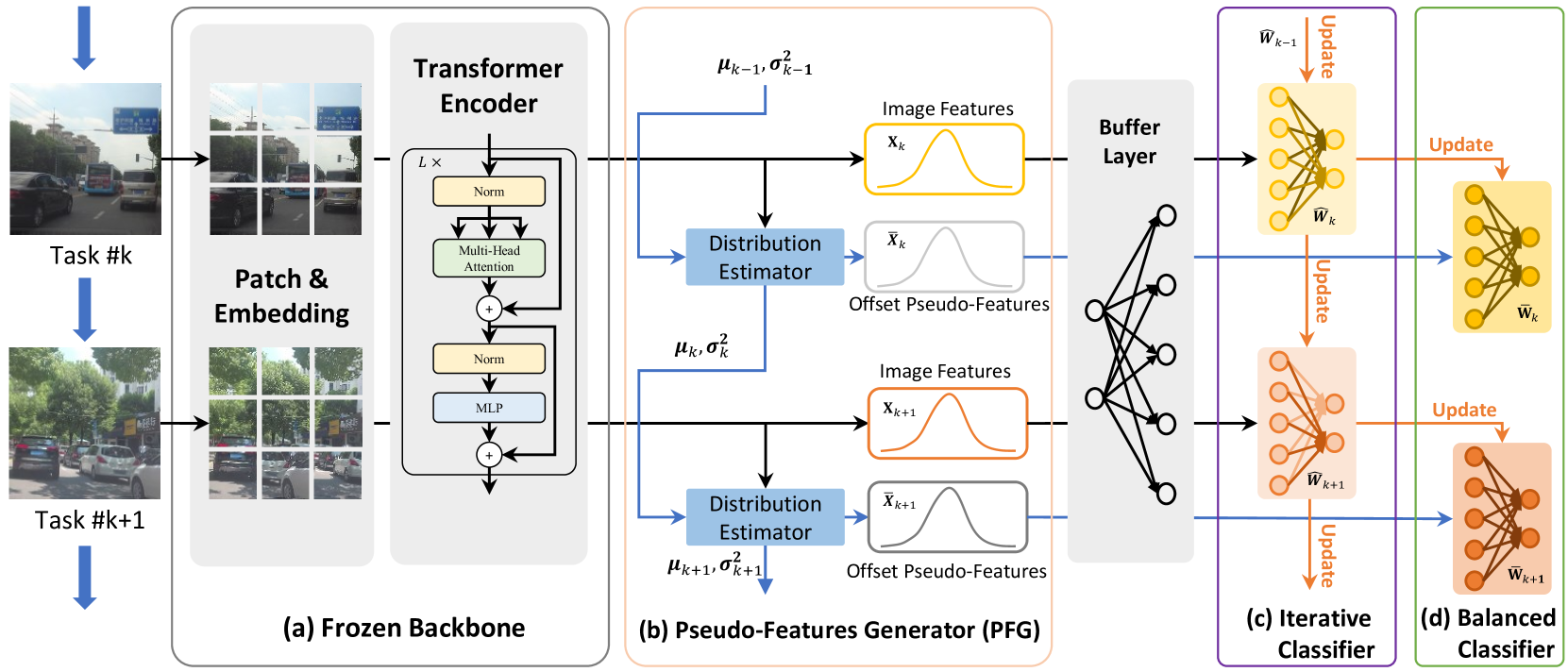
Online Analytic Exemplar-Free Continual Learning with Large Models for Imbalanced Autonomous Driving Task
Huiping Zhuang, Di Fang, Kai Tong, Yuchen Liu, Ziqian Zeng, Xu Zhou, Cen Chen
0
0
In the field of autonomous driving, even a meticulously trained model can encounter failures when faced with unfamiliar sceanrios. One of these scenarios can be formulated as an online continual learning (OCL) problem. That is, data come in an online fashion, and models are updated according to these streaming data. Two major OCL challenges are catastrophic forgetting and data imbalance. To address these challenges, in this paper, we propose an Analytic Exemplar-Free Online Continual Learning (AEF-OCL). The AEF-OCL leverages analytic continual learning principles and employs ridge regression as a classifier for features extracted by a large backbone network. It solves the OCL problem by recursively calculating the analytical solution, ensuring an equalization between the continual learning and its joint-learning counterpart, and works without the need to save any used samples (i.e., exemplar-free). Additionally, we introduce a Pseudo-Features Generator (PFG) module that recursively estimates the deviation of real features. The PFG generates offset pseudo-features following a normal distribution, thereby addressing the data imbalance issue. Experimental results demonstrate that despite being an exemplar-free strategy, our method outperforms various methods on the autonomous driving SODA10M dataset. Source code is available at https://github.com/ZHUANGHP/Analytic-continual-learning.
5/29/2024

G-ACIL: Analytic Learning for Exemplar-Free Generalized Class Incremental Learning
Huiping Zhuang, Yizhu Chen, Di Fang, Run He, Kai Tong, Hongxin Wei, Ziqian Zeng, Cen Chen
0
0
Class incremental learning (CIL) trains a network on sequential tasks with separated categories but suffers from catastrophic forgetting, where models quickly lose previously learned knowledge when acquiring new tasks. The generalized CIL (GCIL) aims to address the CIL problem in a more real-world scenario, where incoming data have mixed data categories and unknown sample size distribution, leading to intensified forgetting. Existing attempts for the GCIL either have poor performance, or invade data privacy by saving historical exemplars. To address this, in this paper, we propose an exemplar-free generalized analytic class incremental learning (G-ACIL). The G-ACIL adopts analytic learning (a gradient-free training technique), and delivers an analytical solution (i.e., closed-form) to the GCIL scenario. This solution is derived via decomposing the incoming data into exposed and unexposed classes, allowing an equivalence between the incremental learning and its joint training, i.e., the weight-invariant property. Such an equivalence is theoretically validated through matrix analysis tools, and hence contributes interpretability in GCIL. It is also empirically evidenced by experiments on various datasets and settings of GCIL. The results show that the G-ACIL exhibits leading performance with high robustness compared with existing competitive GCIL methods. Codes will be ready at url{https://github.com/ZHUANGHP/Analytic-continual-learning}.
4/16/2024
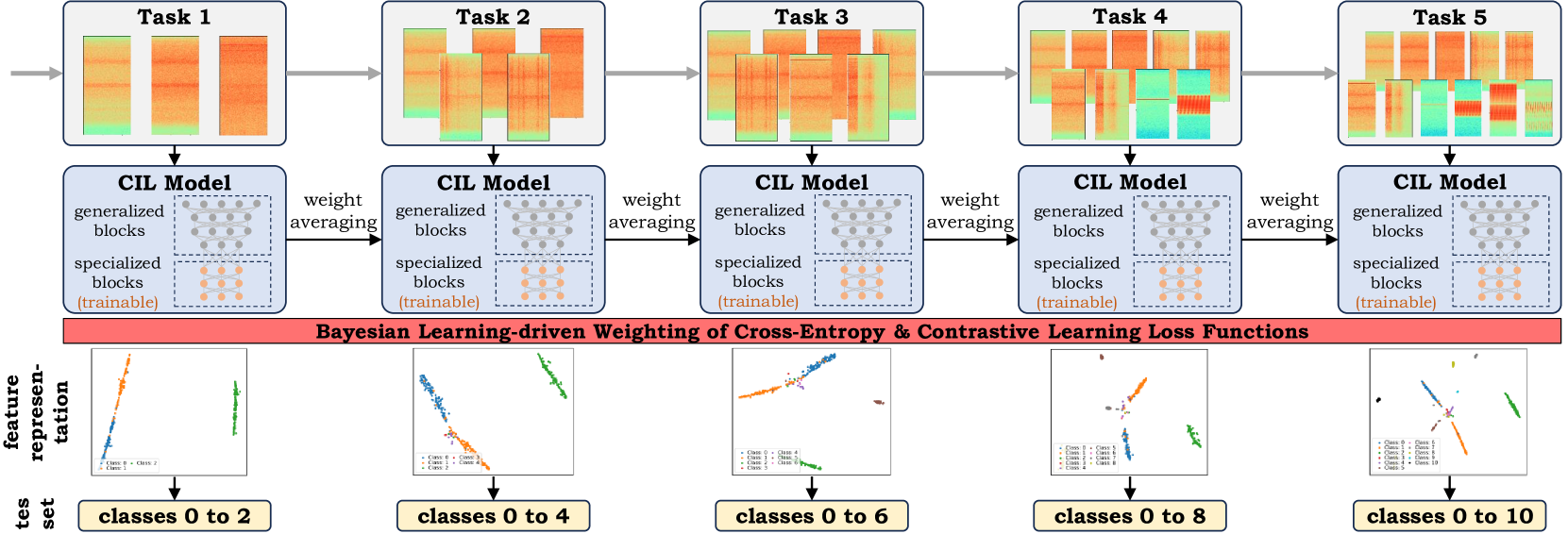
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
0
0
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
5/21/2024