Analogist: Out-of-the-box Visual In-Context Learning with Image Diffusion Model
2405.10316
0
0

Abstract
Visual In-Context Learning (ICL) has emerged as a promising research area due to its capability to accomplish various tasks with limited example pairs through analogical reasoning. However, training-based visual ICL has limitations in its ability to generalize to unseen tasks and requires the collection of a diverse task dataset. On the other hand, existing methods in the inference-based visual ICL category solely rely on textual prompts, which fail to capture fine-grained contextual information from given examples and can be time-consuming when converting from images to text prompts. To address these challenges, we propose Analogist, a novel inference-based visual ICL approach that exploits both visual and textual prompting techniques using a text-to-image diffusion model pretrained for image inpainting. For visual prompting, we propose a self-attention cloning (SAC) method to guide the fine-grained structural-level analogy between image examples. For textual prompting, we leverage GPT-4V's visual reasoning capability to efficiently generate text prompts and introduce a cross-attention masking (CAM) operation to enhance the accuracy of semantic-level analogy guided by text prompts. Our method is out-of-the-box and does not require fine-tuning or optimization. It is also generic and flexible, enabling a wide range of visual tasks to be performed in an in-context manner. Extensive experiments demonstrate the superiority of our method over existing approaches, both qualitatively and quantitatively.
Create account to get full access
Overview
- This paper introduces "Analogist," a novel approach for visual in-context learning using image diffusion models.
- The key idea is to leverage the powerful generative capabilities of diffusion models to perform out-of-the-box visual-to-visual translation without the need for task-specific finetuning.
- Analogist enables a range of visual in-context learning tasks, such as inter-class analogical augmentation and context-aware image generation.
- The authors demonstrate that Analogist can achieve strong performance on these tasks without requiring any additional training beyond the pre-trained diffusion model.
Plain English Explanation
The paper introduces a new approach called "Analogist" that uses powerful diffusion models to enable various types of "visual in-context learning." This means the system can perform interesting image transformations and generation tasks just by providing a reference image, without needing any additional specialized training.
For example, Analogist can take an image of a dog and generate a new image that looks like a cat in a similar pose and setting. Or it can take a portrait and generate a version of that person in a different artistic style. The key is that Analogist leverages the general knowledge and capabilities of the pre-trained diffusion model, rather than requiring the model to be further trained on each specific task.
This makes Analogist very flexible and easy to use "out-of-the-box" - you don't need to spend time and resources fine-tuning the model for each new application. The authors show Analogist achieving strong performance on a range of visual in-context learning benchmarks, demonstrating the potential of this approach to streamline and democratize advanced visual AI capabilities.
Technical Explanation
The core technical innovation of Analogist is its ability to perform visual-to-visual translation tasks using a pre-trained image diffusion model, without any additional task-specific finetuning.
Diffusion models are a powerful class of generative AI models that can synthesize highly realistic images by learning to reverse a process of gradually adding noise to training images. Analogist leverages the rich visual knowledge encoded in these pre-trained diffusion models to enable a variety of in-context learning tasks, including:
-
Inter-class Analogical Augmentation: Given a reference image, Analogist can generate new images that maintain the same pose, background, and high-level semantics, while swapping out the object or entity with a different class (e.g. transforming a dog into a cat).
-
Context-aware Image Generation: Analogist can take a source image and a target context (e.g. a different background or style), and generate a new image that combines elements from both.
The authors demonstrate that Analogist achieves strong performance on these benchmarks, outperforming prior approaches that require task-specific finetuning. This highlights the power of leveraging general-purpose diffusion models for flexible, "out-of-the-box" visual in-context learning.
Critical Analysis
The Analogist paper presents a compelling approach for streamlining visual AI capabilities, but there are a few important caveats to consider:
-
Robustness Limitations: While Analogist shows impressive performance on the specific benchmarks explored, the authors note that context-learning does not always generalize robustly. Further research is needed to understand the limitations and failure modes of this approach.
-
Evaluation Scope: The paper focuses on a relatively narrow set of visual in-context learning tasks. It would be valuable to see how Analogist performs on a wider range of real-world applications and datasets.
-
Transparency & Interpretability: As with many powerful generative models, it can be challenging to fully interpret and explain the inner workings of Analogist. More research is needed to improve the transparency and interpretability of these types of systems.
Despite these caveats, the Analogist approach represents an exciting step forward in making advanced visual AI capabilities more accessible and flexible. Further research building on these ideas could lead to transformative applications across a wide range of domains.
Conclusion
The Analogist paper introduces a novel approach for enabling powerful "visual in-context learning" using pre-trained image diffusion models. By leveraging the rich visual knowledge encoded in these generative models, Analogist can perform a range of flexible image transformation tasks without the need for task-specific finetuning.
This "out-of-the-box" capability has the potential to streamline the development and deployment of advanced visual AI systems, democratizing access to sophisticated image generation and manipulation tools. While the current approach has some limitations, the core ideas presented in this paper represent an exciting step forward in the field of general-purpose visual intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
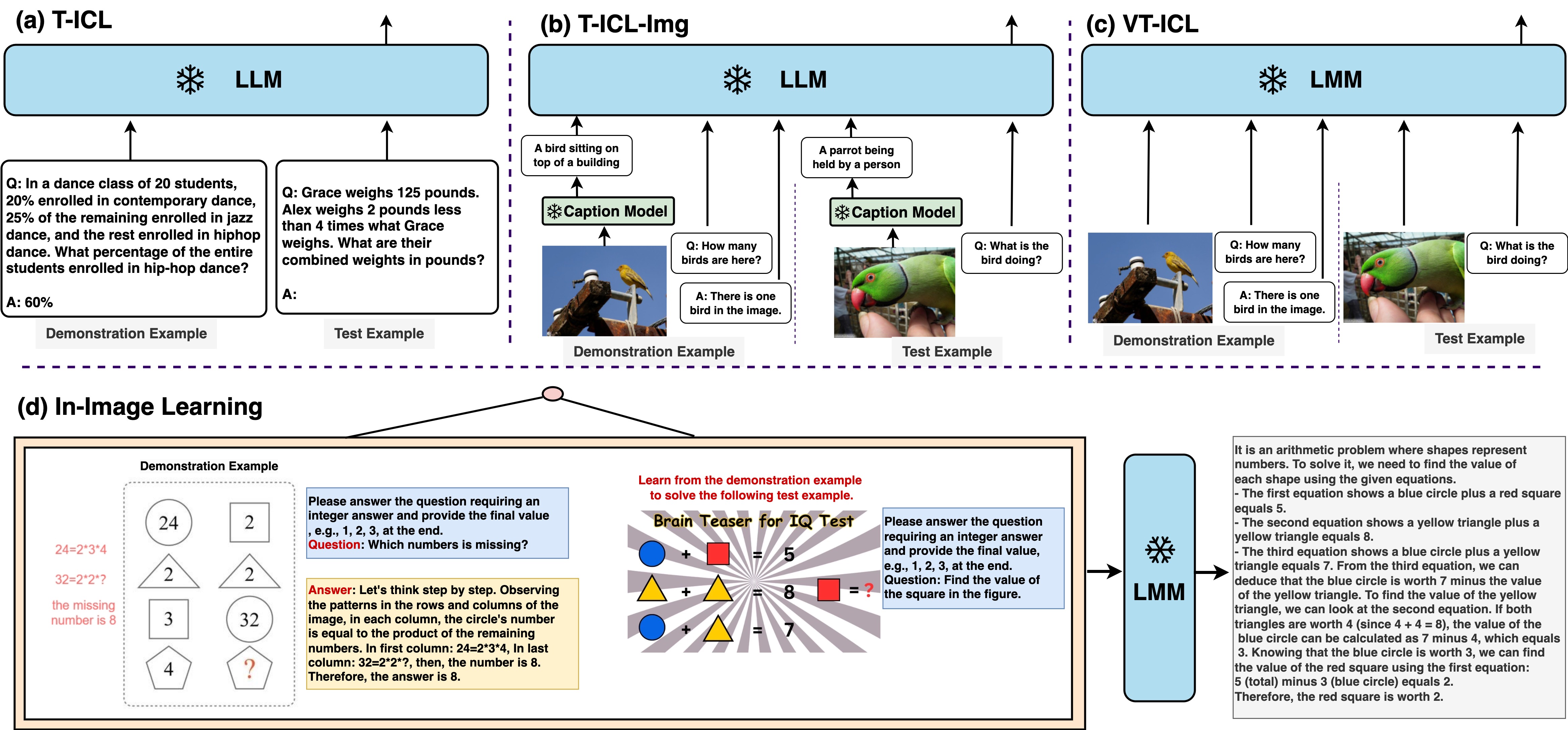
All in an Aggregated Image for In-Image Learning
Lei Wang, Wanyu Xu, Zhiqiang Hu, Yihuai Lan, Shan Dong, Hao Wang, Roy Ka-Wei Lee, Ee-Peng Lim
0
0
This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and chain-of-thought reasoning into an aggregated image to enhance the capabilities of Large Multimodal Models (e.g., GPT-4V) in multimodal reasoning tasks. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into an aggregated image and leverages image processing, understanding, and reasoning abilities. This has several advantages: it reduces inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, and avoids multiple input images and lengthy prompts. We also introduce I$^2$L-Hybrid, a method that combines the strengths of I$^2$L with other ICL methods. Specifically, it uses an automatic strategy to select the most suitable method (I$^2$L or another certain ICL method) for a specific task instance. We conduct extensive experiments to assess the effectiveness of I$^2$L and I$^2$L-Hybrid on MathVista, which covers a variety of complex multimodal reasoning tasks. Additionally, we investigate the influence of image resolution, the number of demonstration examples in a single image, and the positions of these demonstrations in the aggregated image on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
4/3/2024

ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Gabriel Sarch, Lawrence Jang, Michael J. Tarr, William W. Cohen, Kenneth Marino, Katerina Fragkiadaki
0
0
Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
6/24/2024
🌀
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
0
0
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
4/11/2024
👨🏫
Implicit In-context Learning
Zhuowei Li, Zihao Xu, Ligong Han, Yunhe Gao, Song Wen, Di Liu, Hao Wang, Dimitris N. Metaxas
0
0
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of task-ids, enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.
5/24/2024