I'd Like to Have an Argument, Please: Argumentative Reasoning in Large Language Models
2309.16938
0
0

Abstract
We evaluate two large language models (LLMs) ability to perform argumentative reasoning. We experiment with argument mining (AM) and argument pair extraction (APE), and evaluate the LLMs' ability to recognize arguments under progressively more abstract input and output (I/O) representations (e.g., arbitrary label sets, graphs, etc.). Unlike the well-known evaluation of prompt phrasings, abstraction evaluation retains the prompt's phrasing but tests reasoning capabilities. We find that scoring-wise the LLMs match or surpass the SOTA in AM and APE, and under certain I/O abstractions LLMs perform well, even beating chain-of-thought--we call this symbolic prompting. However, statistical analysis on the LLMs outputs when subject to small, yet still human-readable, alterations in the I/O representations (e.g., asking for BIO tags as opposed to line numbers) showed that the models are not performing reasoning. This suggests that LLM applications to some tasks, such as data labelling and paper reviewing, must be done with care.
Create account to get full access
Overview
- This research paper investigates the ability of large language models (LLMs) to engage in argumentative reasoning and how that can enhance their performance.
- The paper explores techniques for imbuing LLMs with formal argumentative reasoning capabilities and evaluates the impacts on their decision-making, explainability, and contestability.
- It also examines the reasoning behaviors of LLMs beyond just accuracy, looking at their ability to draw interventional inferences and make persuasive arguments.
Plain English Explanation
Large language models (LLMs) are powerful AI systems trained on vast amounts of text data that can generate human-like language. However, it's not always clear how these models arrive at their outputs or whether they are truly engaging in meaningful reasoning.
This research explores ways to enhance LLMs with the ability to reason using formal argumentation. Formal argumentative reasoning is a structured approach to making claims, providing evidence, and addressing counter-arguments. The researchers investigate whether equipping LLMs with this kind of reasoning capability can improve their decision-making, make their thought processes more explainable and contestable, and enhance other aspects of their performance beyond just accuracy.
The paper also looks at the reasoning behaviors of LLMs more broadly, examining their ability to draw interventional inferences and make persuasive arguments, rather than just their surface-level accuracy.
By understanding the reasoning capabilities of LLMs, the researchers hope to develop more transparent, trustworthy, and beneficial AI systems that can engage in thoughtful deliberation and justify their decisions.
Technical Explanation
The researchers used a combination of techniques to imbue LLMs with formal argumentative reasoning capabilities. They first trained the models on a large corpus of argumentative text data to expose them to the structure and conventions of argumentation. They then fine-tuned the models using an argument mining approach, which involves explicitly identifying the claims, evidence, and counterarguments within the text.
To evaluate the impacts of this approach, the researchers tested the LLMs on a variety of tasks that require reasoning and decision-making. This included assessing the models' ability to make explainable and contestable decisions, draw interventional inferences, and construct persuasive arguments.
The findings indicate that equipping LLMs with formal argumentative reasoning can indeed enhance their performance on these tasks, leading to more explainable and contestable decisions, better interventional reasoning, and more persuasive arguments. The researchers also found that the models' reasoning behaviors went beyond just accuracy, demonstrating more sophisticated logical and causal thinking.
Critical Analysis
The researchers acknowledge several caveats and limitations of their work. For instance, the performance improvements observed may be specific to the particular tasks and datasets used in the study, and further research is needed to determine the generalizability of the findings.
Additionally, the paper does not fully address the potential challenges and risks of imbuing LLMs with argumentative reasoning capabilities. There may be concerns about the models' ability to generate persuasive but misleading arguments or about the potential for these systems to be used for malicious purposes, such as spreading disinformation.
Further research is also needed to understand the underlying mechanisms by which formal argumentative reasoning enhances LLM performance and to explore alternative approaches to improving the reasoning capabilities of these models.
Conclusion
This research represents an important step towards developing more transparent, trustworthy, and beneficial AI systems. By equipping LLMs with formal argumentative reasoning, the researchers have shown that these models can make more explainable and contestable decisions, draw better interventional inferences, and construct more persuasive arguments.
These findings have significant implications for the development of AI systems that can engage in thoughtful deliberation, justify their decisions, and be held accountable. While further research is needed to address the limitations and potential risks, this work demonstrates the value of imbuing LLMs with sophisticated reasoning capabilities beyond just accuracy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Can formal argumentative reasoning enhance LLMs performances?
Federico Castagna, Isabel Sassoon, Simon Parsons
0
0
Recent years witnessed significant performance advancements in deep-learning-driven natural language models, with a strong focus on the development and release of Large Language Models (LLMs). These improvements resulted in better quality AI-generated output but rely on resource-expensive training and upgrading of models. Although different studies have proposed a range of techniques to enhance LLMs without retraining, none have considered computational argumentation as an option. This is a missed opportunity since computational argumentation is an intuitive mechanism that formally captures agents' interactions and the information conflict that may arise during such interplays, and so it seems well-suited for boosting the reasoning and conversational abilities of LLMs in a seamless manner. In this paper, we present a pipeline (MQArgEng) and preliminary study to evaluate the effect of introducing computational argumentation semantics on the performance of LLMs. Our experiment's goal was to provide a proof-of-concept and a feasibility analysis in order to foster (or deter) future research towards a fully-fledged argumentation engine plugin for LLMs. Exploratory results using the MT-Bench indicate that MQArgEng provides a moderate performance gain in most of the examined topical categories and, as such, show promise and warrant further research.
5/24/2024
💬
Argumentative Large Language Models for Explainable and Contestable Decision-Making
Gabriel Freedman, Adam Dejl, Deniz Gorur, Xiang Yin, Antonio Rago, Francesca Toni
0
0
The diversity of knowledge encoded in large language models (LLMs) and their ability to apply this knowledge zero-shot in a range of settings makes them a promising candidate for use in decision-making. However, they are currently limited by their inability to reliably provide outputs which are explainable and contestable. In this paper, we attempt to reconcile these strengths and weaknesses by introducing a method for supplementing LLMs with argumentative reasoning. Concretely, we introduce argumentative LLMs, a method utilising LLMs to construct argumentation frameworks, which then serve as the basis for formal reasoning in decision-making. The interpretable nature of these argumentation frameworks and formal reasoning means that any decision made by the supplemented LLM may be naturally explained to, and contested by, humans. We demonstrate the effectiveness of argumentative LLMs experimentally in the decision-making task of claim verification. We obtain results that are competitive with, and in some cases surpass, comparable state-of-the-art techniques.
5/6/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
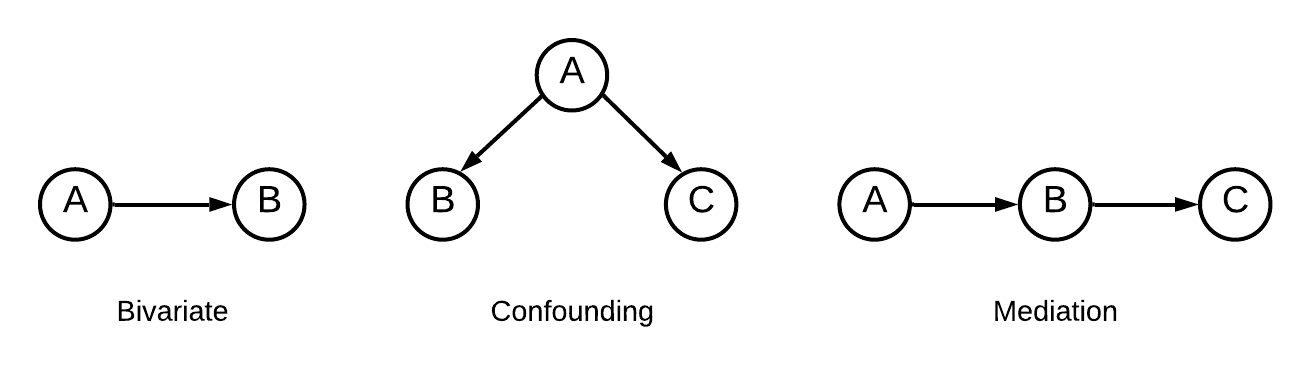
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024