SGV3D:Towards Scenario Generalization for Vision-based Roadside 3D Object Detection
2401.16110
0
1

Abstract
Roadside perception can greatly increase the safety of autonomous vehicles by extending their perception ability beyond the visual range and addressing blind spots. However, current state-of-the-art vision-based roadside detection methods possess high accuracy on labeled scenes but have inferior performance on new scenes. This is because roadside cameras remain stationary after installation and can only collect data from a single scene, resulting in the algorithm overfitting these roadside backgrounds and camera poses. To address this issue, in this paper, we propose an innovative Scenario Generalization Framework for Vision-based Roadside 3D Object Detection, dubbed SGV3D. Specifically, we employ a Background-suppressed Module (BSM) to mitigate background overfitting in vision-centric pipelines by attenuating background features during the 2D to bird's-eye-view projection. Furthermore, by introducing the Semi-supervised Data Generation Pipeline (SSDG) using unlabeled images from new scenes, diverse instance foregrounds with varying camera poses are generated, addressing the risk of overfitting specific camera poses. We evaluate our method on two large-scale roadside benchmarks. Our method surpasses all previous methods by a significant margin in new scenes, including +42.57% for vehicle, +5.87% for pedestrian, and +14.89% for cyclist compared to BEVHeight on the DAIR-V2X-I heterologous benchmark. On the larger-scale Rope3D heterologous benchmark, we achieve notable gains of 14.48% for car and 12.41% for large vehicle. We aspire to contribute insights on the exploration of roadside perception techniques, emphasizing their capability for scenario generalization. The code will be available at https://github.com/yanglei18/SGV3D
Create account to get full access
Overview
- This paper proposes a method to improve the generalization of vision-based 3D object detection models for roadside scenarios.
- The researchers aim to address the challenge of detecting 3D objects, such as vehicles and pedestrians, from monocular camera images in diverse real-world settings.
- The proposed approach leverages synthetic data generation and data augmentation techniques to enhance the model's ability to handle a wider range of environmental conditions and object variations.
Plain English Explanation
The paper focuses on improving the performance of 3D object detection systems that use a single camera to perceive the world around a vehicle. These systems are essential for autonomous driving and advanced driver assistance features, as they allow the vehicle to understand and respond to its environment.
However, real-world driving scenarios can be highly variable, with changing weather, lighting conditions, and diverse objects on the road. This makes it challenging for 3D object detection models to generalize and perform well in all situations.
To address this, the researchers have developed a method that combines synthetic data generation and data augmentation techniques. By creating realistic virtual driving scenarios and applying various transformations to the training data, the model can learn to recognize a wider range of objects and environmental conditions.
This approach aims to make the 3D object detection system more robust and versatile, allowing it to perform well in a variety of real-world settings, rather than being limited to a specific set of conditions.
Technical Explanation
The paper presents a multi-pronged approach to improve the scenario generalization of vision-based 3D object detection models for roadside environments.
-
Synthetic Data Generation: The researchers leverage the VERSATILE framework to generate synthetic driving scenes with a diverse range of object types, weather conditions, and lighting variations. This synthetic data is used to supplement the training of the 3D object detection model.
-
Data Augmentation: In addition to the synthetic data, the authors apply various data augmentation techniques, such as MOSE-Boosting and Rendering-Enhanced Automatic Image-to-Point Cloud, to further increase the diversity of the training data.
-
Monocular 3D Detection: The core of the object detection system is a monocular 3D detection model, which takes a single camera image as input and outputs the 3D bounding boxes and locations of objects in the scene. The authors build upon existing monocular 3D detection approaches and label-efficient techniques to improve the overall performance.
The combination of synthetic data generation, data augmentation, and the monocular 3D detection model aims to enable the system to generalize well to a wide range of real-world roadside scenarios, even those not explicitly seen during training.
Critical Analysis
The paper presents a comprehensive approach to improve the scenario generalization of 3D object detection models, which is a significant challenge in real-world autonomous driving applications. The authors acknowledge that their method still has limitations, such as the potential for domain shift between the synthetic and real-world data, and the need for further improvements in the monocular 3D detection model itself.
Additionally, the paper does not provide a detailed analysis of the computational costs and inference time of the proposed system, which are important factors for real-time deployment in autonomous vehicles. Further research could also explore the integration of this approach with other techniques, such as simultaneous localization and mapping (SLAM) or sensor fusion, to enhance the overall robustness and reliability of the 3D object detection system.
Conclusion
This paper presents a promising approach to address the challenge of scenario generalization in vision-based 3D object detection for roadside environments. By leveraging synthetic data generation and advanced data augmentation techniques, the researchers have developed a system that aims to perform well across a diverse range of real-world driving conditions.
The proposed method represents an important step towards more robust and reliable 3D object detection systems, which are crucial for the advancement of autonomous driving and intelligent transportation technologies. Further research and development in this area could lead to significant improvements in the safety and performance of autonomous vehicles, ultimately benefiting both users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Xiahan Chen, Mingjian Chen, Sanli Tang, Yi Niu, Jiang Zhu
0
0
3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.
4/9/2024
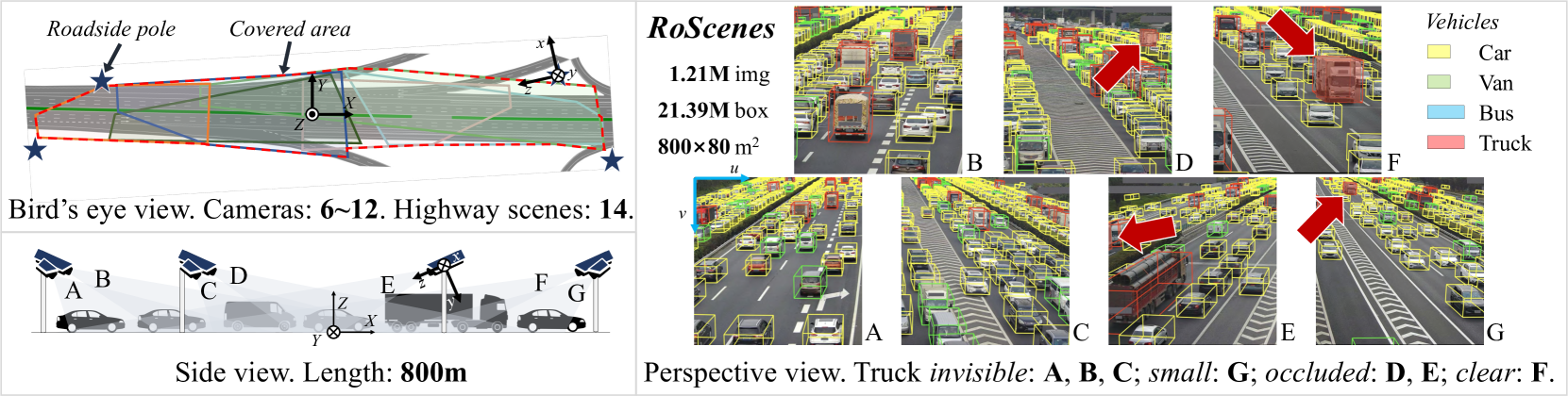
RoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception
Xiaosu Zhu, Hualian Sheng, Sijia Cai, Bing Deng, Shaopeng Yang, Qiao Liang, Ken Chen, Lianli Gao, Jingkuan Song, Jieping Ye
0
0
We introduce RoScenes, the largest multi-view roadside perception dataset, which aims to shed light on the development of vision-centric Bird's Eye View (BEV) approaches for more challenging traffic scenes. The highlights of RoScenes include significantly large perception area, full scene coverage and crowded traffic. More specifically, our dataset achieves surprising 21.13M 3D annotations within 64,000 $m^2$. To relieve the expensive costs of roadside 3D labeling, we present a novel BEV-to-3D joint annotation pipeline to efficiently collect such a large volume of data. After that, we organize a comprehensive study for current BEV methods on RoScenes in terms of effectiveness and efficiency. Tested methods suffer from the vast perception area and variation of sensor layout across scenes, resulting in performance levels falling below expectations. To this end, we propose RoBEV that incorporates feature-guided position embedding for effective 2D-3D feature assignment. With its help, our method outperforms state-of-the-art by a large margin without extra computational overhead on validation set. Our dataset and devkit will be made available at https://github.com/xiaosu-zhu/RoScenes.
5/21/2024
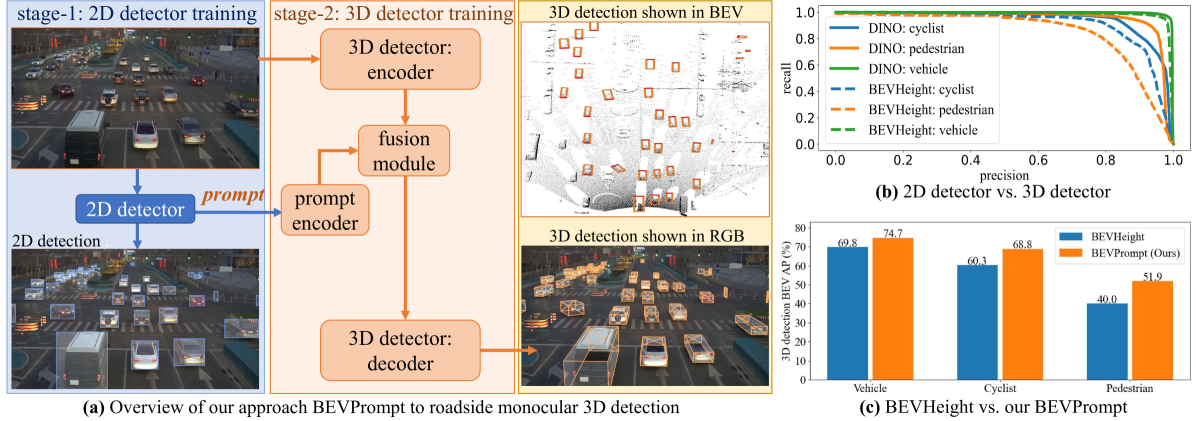
Roadside Monocular 3D Detection via 2D Detection Prompting
Yechi Ma, Shuoquan Wei, Churun Zhang, Wei Hua, Yanan Li, Shu Kong
0
0
The problem of roadside monocular 3D detection requires detecting objects of interested classes in a 2D RGB frame and predicting their 3D information such as locations in bird's-eye-view (BEV). It has broad applications in traffic control, vehicle-vehicle communication, and vehicle-infrastructure cooperative perception. To approach this problem, we present a novel and simple method by prompting the 3D detector using 2D detections. Our method builds on a key insight that, compared with 3D detectors, a 2D detector is much easier to train and performs significantly better w.r.t detections on the 2D image plane. That said, one can exploit 2D detections of a well-trained 2D detector as prompts to a 3D detector, being trained in a way of inflating such 2D detections to 3D towards 3D detection. To construct better prompts using the 2D detector, we explore three techniques: (a) concatenating both 2D and 3D detectors' features, (b) attentively fusing 2D and 3D detectors' features, and (c) encoding predicted 2D boxes x, y, width, height, label and attentively fusing such with the 3D detector's features. Surprisingly, the third performs the best. Moreover, we present a yaw tuning tactic and a class-grouping strategy that merges classes based on their functionality; these techniques improve 3D detection performance further. Comprehensive ablation studies and extensive experiments demonstrate that our method resoundingly outperforms prior works, achieving the state-of-the-art on two large-scale roadside 3D detection benchmarks.
4/5/2024

VDG: Vision-Only Dynamic Gaussian for Driving Simulation
Hao Li, Jingfeng Li, Dingwen Zhang, Chenming Wu, Jieqi Shi, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, Junwei Han
0
0
Dynamic Gaussian splatting has led to impressive scene reconstruction and image synthesis advances in novel views. Existing methods, however, heavily rely on pre-computed poses and Gaussian initialization by Structure from Motion (SfM) algorithms or expensive sensors. For the first time, this paper addresses this issue by integrating self-supervised VO into our pose-free dynamic Gaussian method (VDG) to boost pose and depth initialization and static-dynamic decomposition. Moreover, VDG can work with only RGB image input and construct dynamic scenes at a faster speed and larger scenes compared with the pose-free dynamic view-synthesis method. We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods. Additional video and source code will be posted on our project page at https://3d-aigc.github.io/VDG.
6/27/2024