Image Clustering Algorithm Based on Self-Supervised Pretrained Models and Latent Feature Distribution Optimization

0

Sign in to get full access
Overview
- This paper presents a novel image clustering algorithm that leverages self-supervised pretrained models and latent feature distribution optimization.
- The approach aims to capture more discriminative features by aligning the latent feature distribution of similar images.
- Experiments on benchmark datasets show the proposed method outperforms state-of-the-art clustering algorithms.
Plain English Explanation
The paper introduces a new way to group similar images together, called an image clustering algorithm. This algorithm uses self-supervised pretrained models, which are AI systems that have been trained on large amounts of data to learn general visual features, without being given specific labels.
The key idea is to optimize the distribution of the hidden, or "latent", features extracted by these pretrained models. By ensuring the latent features of similar images have a similar distribution, the algorithm can better capture the distinctive characteristics of each image group.
This latent feature distribution optimization allows the algorithm to discover more informative and discriminative features, leading to improved clustering performance compared to existing methods. The researchers evaluated their approach on standard benchmark datasets and found it outperformed other state-of-the-art clustering techniques.
Technical Explanation
The paper proposes an image clustering algorithm that leverages self-supervised pretrained models and latent feature distribution optimization.
The authors first use a self-supervised pretrained model, such as BYOL or SimCLR, to extract latent features from the input images. These latent features capture useful visual information in a compact representation.
To improve the clustering performance, the algorithm optimizes the distribution of the latent features for similar images. By aligning the latent feature distributions, the method can better capture the discriminative characteristics of each image cluster.
The authors evaluate their approach on several benchmark image clustering datasets and show that it outperforms state-of-the-art methods in terms of clustering accuracy and other metrics.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed image clustering algorithm. The authors acknowledge that the performance gains come at the cost of increased computational complexity compared to simpler clustering methods.
One potential limitation is the reliance on self-supervised pretrained models, which may not be available or feasible for all types of image data. The researchers could explore ways to make the method more generalizable or investigate the impact of different pretrained model architectures on clustering performance.
Additionally, the paper does not delve into the interpretability of the learned clusters or provide insights into the types of visual features that are being emphasized by the latent feature distribution optimization. Investigating these aspects could lead to a better understanding of the algorithm's behavior and potential biases.
Conclusion
This paper presents a novel image clustering algorithm that leverages self-supervised pretrained models and latent feature distribution optimization. By aligning the distribution of latent features for similar images, the method can capture more discriminative visual characteristics, leading to improved clustering performance on benchmark datasets.
While the approach introduces additional computational complexity, it demonstrates the benefits of leveraging self-supervised learning and sophisticated feature engineering techniques for challenging image clustering tasks. Further research could explore ways to make the method more generalizable and provide deeper insights into the learned cluster representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Image Clustering Algorithm Based on Self-Supervised Pretrained Models and Latent Feature Distribution Optimization
Qiuyu Zhu, Liheng Hu, Sijin Wang
In the face of complex natural images, existing deep clustering algorithms fall significantly short in terms of clustering accuracy when compared to supervised classification methods, making them less practical. This paper introduces an image clustering algorithm based on self-supervised pretrained models and latent feature distribution optimization, substantially enhancing clustering performance. It is found that: (1) For complex natural images, we effectively enhance the discriminative power of latent features by leveraging self-supervised pretrained models and their fine-tuning, resulting in improved clustering performance. (2) In the latent feature space, by searching for k-nearest neighbor images for each training sample and shortening the distance between the training sample and its nearest neighbor, the discriminative power of latent features can be further enhanced, and clustering performance can be improved. (3) In the latent feature space, reducing the distance between sample features and the nearest predefined cluster centroids can optimize the distribution of latent features, therefore further improving clustering performance. Through experiments on multiple datasets, our approach outperforms the latest clustering algorithms and achieves state-of-the-art clustering results. When the number of categories in the datasets is small, such as CIFAR-10 and STL-10, and there are significant differences between categories, our clustering algorithm has similar accuracy to supervised methods without using pretrained models, slightly lower than supervised methods using pre-trained models. The code linked algorithm is https://github.com/LihengHu/semi.
Read more8/13/2024
🖼️
0
Image Clustering via the Principle of Rate Reduction in the Age of Pretrained Models
Tianzhe Chu, Shengbang Tong, Tianjiao Ding, Xili Dai, Benjamin David Haeffele, Ren'e Vidal, Yi Ma
The advent of large pre-trained models has brought about a paradigm shift in both visual representation learning and natural language processing. However, clustering unlabeled images, as a fundamental and classic machine learning problem, still lacks an effective solution, particularly for large-scale datasets. In this paper, we propose a novel image clustering pipeline that leverages the powerful feature representation of large pre-trained models such as CLIP and cluster images effectively and efficiently at scale. We first developed a novel algorithm to estimate the number of clusters in a given dataset. We then show that the pre-trained features are significantly more structured by further optimizing the rate reduction objective. The resulting features may significantly improve the clustering accuracy, e.g., from 57% to 66% on ImageNet-1k. Furthermore, by leveraging CLIP's multimodality bridge between image and text, we develop a simple yet effective self-labeling algorithm that produces meaningful captions for the clusters. Through extensive experiments, we show that our pipeline works well on standard datasets such as CIFAR-10, CIFAR-100, and ImageNet-1k. It also extends to datasets that are not curated for clustering, such as LAION-Aesthetics and WikiArts. We released the code in https://github.com/LeslieTrue/CPP.
Read more4/29/2024
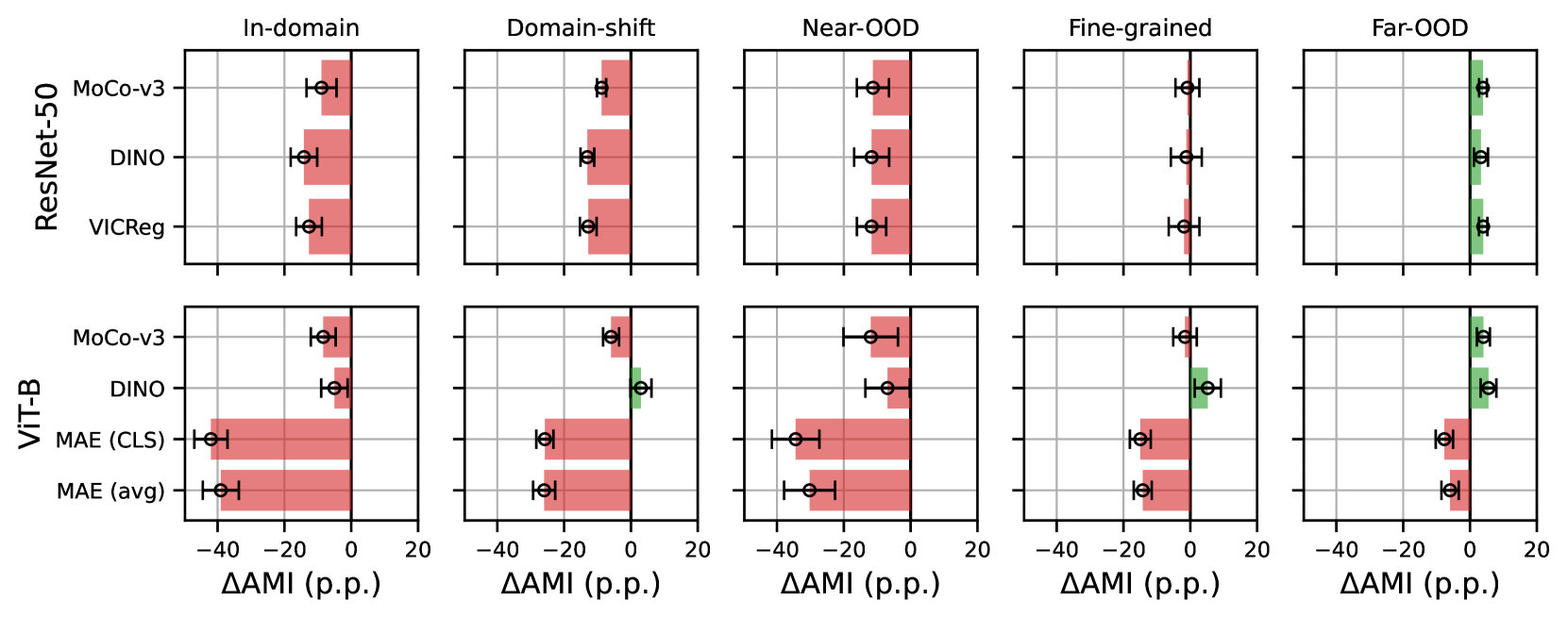
0
An Empirical Study into Clustering of Unseen Datasets with Self-Supervised Encoders
Scott C. Lowe, Joakim Bruslund Haurum, Sageev Oore, Thomas B. Moeslund, Graham W. Taylor
Can pretrained models generalize to new datasets without any retraining? We deploy pretrained image models on datasets they were not trained for, and investigate whether their embeddings form meaningful clusters. Our suite of benchmarking experiments use encoders pretrained solely on ImageNet-1k with either supervised or self-supervised training techniques, deployed on image datasets that were not seen during training, and clustered with conventional clustering algorithms. This evaluation provides new insights into the embeddings of self-supervised models, which prioritize different features to supervised models. Supervised encoders typically offer more utility than SSL encoders within the training domain, and vice-versa far outside of it, however, fine-tuned encoders demonstrate the opposite trend. Clustering provides a way to evaluate the utility of self-supervised learned representations orthogonal to existing methods such as kNN. Additionally, we find the silhouette score when measured in a UMAP-reduced space is highly correlated with clustering performance, and can therefore be used as a proxy for clustering performance on data with no ground truth labels. Our code implementation is available at url{https://github.com/scottclowe/zs-ssl-clustering/}.
Read more6/5/2024

0
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
Huy V. Vo, Vasil Khalidov, Timoth'ee Darcet, Th'eo Moutakanni, Nikita Smetanin, Marc Szafraniec, Hugo Touvron, Camille Couprie, Maxime Oquab, Armand Joulin, Herv'e J'egou, Patrick Labatut, Piotr Bojanowski
Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort. This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training. We posit that such datasets should be large, diverse and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of $k$-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data. Code is available at https://github.com/facebookresearch/ssl-data-curation.
Read more7/1/2024