Image Score: Learning and Evaluating Human Preferences for Mercari Search

0

Sign in to get full access
Overview
- The paper presents a method called "Image Score" for learning and evaluating human preferences for product search on the Mercari platform.
- It describes an approach to train machine learning models to predict user preferences for product search results based on images and other metadata.
- The method is evaluated on real-world user data from the Mercari marketplace.
Plain English Explanation
The researchers developed a system called "Image Score" that aims to better understand human preferences for product search. This is an important problem for e-commerce platforms like Mercari that need to surface the most relevant products for each user's search.
The core idea is to train machine learning models to predict how much a user will like a given product based on the product's image and other metadata. The researchers collected real-world data from Mercari users about which search results they preferred. They then used this data to train models that could learn the patterns in user preferences.
The goal is for these "Image Score" models to be able to accurately forecast which search results a user will find most appealing, allowing the platform to rank and display products in an optimal way. This could lead to a better overall shopping experience and more successful transactions.
Technical Explanation
The paper first reviews related work on modeling user preferences and evaluating fairness in large language models used for e-commerce applications.
The core "Image Score" approach involves:
- Collecting user preference data by showing Mercari users search results and having them indicate which ones they like best.
- Training machine learning models to predict these user preferences based on the product images and other metadata like title, price, etc.
- Evaluating the trained models on held-out preference data to measure how accurately they can forecast user preferences.
The researchers experiment with different model architectures and training approaches, including using large language models to encode the product information.
Key findings include that the "Image Score" models are able to substantially outperform baseline methods at predicting user preferences, indicating the value of this approach for improving product search relevance.
Critical Analysis
The paper provides a rigorous evaluation of the "Image Score" approach, including discussion of limitations and avenues for future work. One potential concern is the reliance on self-reported user preferences, which may not fully capture actual user behavior and engagement.
Additionally, the research is focused on a single e-commerce platform (Mercari), so further validation on other marketplaces would help establish the generalizability of the findings. Exploring how "Image Score" models could be kept up-to-date as product catalogs evolve is another interesting direction.
Overall, the work represents an innovative approach to modeling and predicting user preferences for product search, with promising implications for improving e-commerce experiences.
Conclusion
This paper presents a novel "Image Score" method for learning and evaluating human preferences for product search results. By training machine learning models to predict user preferences based on product images and metadata, the approach aims to enhance search relevance and the overall shopping experience on e-commerce platforms like Mercari.
The technical evaluation demonstrates the effectiveness of this approach, suggesting it could be a valuable tool for e-commerce companies seeking to better understand and cater to their customers' needs. Further research to expand the applicability and robustness of "Image Score" models could yield important insights for the field of AI-powered e-commerce.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Image Score: Learning and Evaluating Human Preferences for Mercari Search
Chingis Oinar, Miao Cao, Shanshan Fu
Mercari is the largest C2C e-commerce marketplace in Japan, having more than 20 million active monthly users. Search being the fundamental way to discover desired items, we have always had a substantial amount of data with implicit feedback. Although we actively take advantage of that to provide the best service for our users, the correlation of implicit feedback for such tasks as image quality assessment is not trivial. Many traditional lines of research in Machine Learning (ML) are similarly motivated by the insatiable appetite of Deep Learning (DL) models for well-labelled training data. Weak supervision is about leveraging higher-level and/or noisier supervision over unlabeled data. Large Language Models (LLMs) are being actively studied and used for data labelling tasks. We present how we leverage a Chain-of-Thought (CoT) to enable LLM to produce image aesthetics labels that correlate well with human behavior in e-commerce settings. Leveraging LLMs is more cost-effective compared to explicit human judgment, while significantly improving the explainability of deep image quality evaluation which is highly important for customer journey optimization at Mercari. We propose a cost-efficient LLM-driven approach for assessing and predicting image quality in e-commerce settings, which is very convenient for proof-of-concept testing. We show that our LLM-produced labels correlate with user behavior on Mercari. Finally, we show our results from an online experimentation, where we achieved a significant growth in sales on the web platform.
Read more8/22/2024
👀
0
Investigating LLM Applications in E-Commerce
Chester Palen-Michel, Ruixiang Wang, Yipeng Zhang, David Yu, Canran Xu, Zhe Wu
The emergence of Large Language Models (LLMs) has revolutionized natural language processing in various applications especially in e-commerce. One crucial step before the application of such LLMs in these fields is to understand and compare the performance in different use cases in such tasks. This paper explored the efficacy of LLMs in the e-commerce domain, focusing on instruction-tuning an open source LLM model with public e-commerce datasets of varying sizes and comparing the performance with the conventional models prevalent in industrial applications. We conducted a comprehensive comparison between LLMs and traditional pre-trained language models across specific tasks intrinsic to the e-commerce domain, namely classification, generation, summarization, and named entity recognition (NER). Furthermore, we examined the effectiveness of the current niche industrial application of very large LLM, using in-context learning, in e-commerce specific tasks. Our findings indicate that few-shot inference with very large LLMs often does not outperform fine-tuning smaller pre-trained models, underscoring the importance of task-specific model optimization.Additionally, we investigated different training methodologies such as single-task training, mixed-task training, and LoRA merging both within domain/tasks and between different tasks. Through rigorous experimentation and analysis, this paper offers valuable insights into the potential effectiveness of LLMs to advance natural language processing capabilities within the e-commerce industry.
Read more8/26/2024
💬
0
A survey on fairness of large language models in e-commerce: progress, application, and challenge
Qingyang Ren, Zilin Jiang, Jinghan Cao, Sijia Li, Chiqu Li, Yiyang Liu, Shuning Huo, Tiange He, Yuan Chen
This survey explores the fairness of large language models (LLMs) in e-commerce, examining their progress, applications, and the challenges they face. LLMs have become pivotal in the e-commerce domain, offering innovative solutions and enhancing customer experiences. This work presents a comprehensive survey on the applications and challenges of LLMs in e-commerce. The paper begins by introducing the key principles underlying the use of LLMs in e-commerce, detailing the processes of pretraining, fine-tuning, and prompting that tailor these models to specific needs. It then explores the varied applications of LLMs in e-commerce, including product reviews, where they synthesize and analyze customer feedback; product recommendations, where they leverage consumer data to suggest relevant items; product information translation, enhancing global accessibility; and product question and answer sections, where they automate customer support. The paper critically addresses the fairness challenges in e-commerce, highlighting how biases in training data and algorithms can lead to unfair outcomes, such as reinforcing stereotypes or discriminating against certain groups. These issues not only undermine consumer trust, but also raise ethical and legal concerns. Finally, the work outlines future research directions, emphasizing the need for more equitable and transparent LLMs in e-commerce. It advocates for ongoing efforts to mitigate biases and improve the fairness of these systems, ensuring they serve diverse global markets effectively and ethically. Through this comprehensive analysis, the survey provides a holistic view of the current landscape of LLMs in e-commerce, offering insights into their potential and limitations, and guiding future endeavors in creating fairer and more inclusive e-commerce environments.
Read more6/26/2024
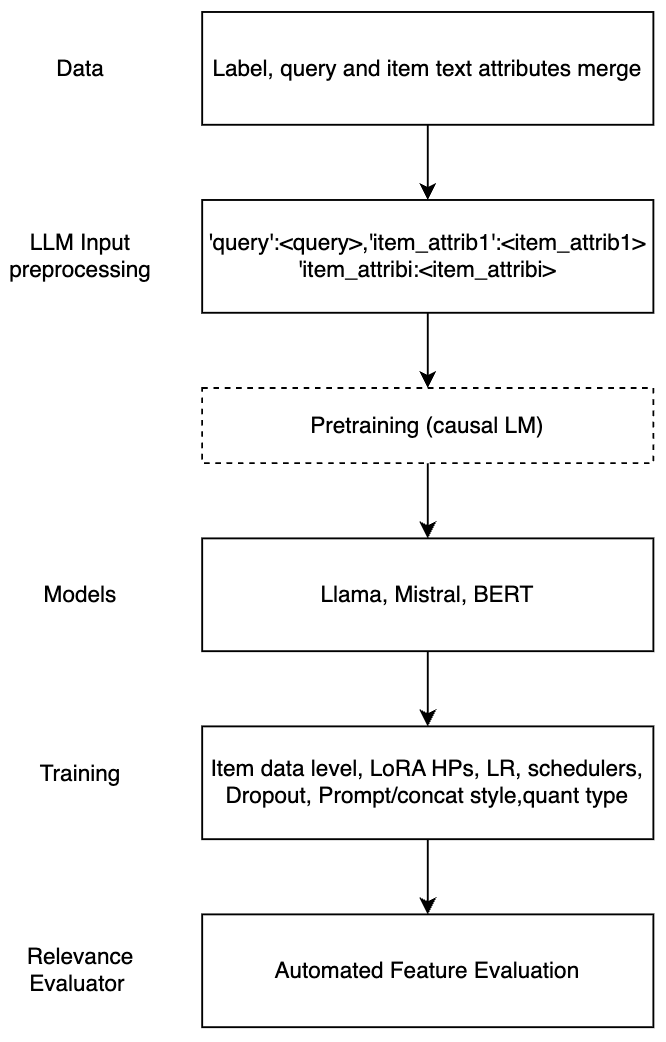
0
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
Read more7/18/2024