Image-of-Thought Prompting for Visual Reasoning Refinement in Multimodal Large Language Models
2405.13872
0
0
💬
Abstract
Recent advancements in Chain-of-Thought (CoT) and related rationale-based works have significantly improved the performance of Large Language Models (LLMs) in complex reasoning tasks. With the evolution of Multimodal Large Language Models (MLLMs), enhancing their capability to tackle complex multimodal reasoning problems is a crucial frontier. However, incorporating multimodal rationales in CoT has yet to be thoroughly investigated. We propose the Image-of-Thought (IoT) prompting method, which helps MLLMs to extract visual rationales step-by-step. Specifically, IoT prompting can automatically design critical visual information extraction operations based on the input images and questions. Each step of visual information refinement identifies specific visual rationales that support answers to complex visual reasoning questions. Beyond the textual CoT, IoT simultaneously utilizes visual and textual rationales to help MLLMs understand complex multimodal information. IoT prompting has improved zero-shot visual reasoning performance across various visual understanding tasks in different MLLMs. Moreover, the step-by-step visual feature explanations generated by IoT prompting elucidate the visual reasoning process, aiding in analyzing the cognitive processes of large multimodal models
Create account to get full access
Overview
- Recent advancements in Chain-of-Thought (CoT) and related rationale-based works have significantly improved the performance of Large Language Models (LLMs) in complex reasoning tasks.
- The evolution of Multimodal Large Language Models (MLLMs) brings the need to enhance their capability to tackle complex multimodal reasoning problems.
- Incorporating multimodal rationales in CoT has yet to be thoroughly investigated.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can process and generate human-like text. Recent improvements in techniques like Chain-of-Thought (CoT) and related methods have significantly boosted the ability of LLMs to tackle complex reasoning tasks.
As these language models have become more sophisticated, researchers are now focused on developing
However, the researchers note that incorporating multimodal "rationales" (the reasoning and justifications behind answers) into the CoT process has not been thoroughly explored yet. To address this, they propose a new method called "Image-of-Thought" (IoT) prompting.
Technical Explanation
The IoT prompting method aims to help MLLMs extract visual rationales step-by-step when tackling complex multimodal reasoning problems. Specifically, IoT prompting can automatically design critical visual information extraction operations based on the input images and questions.
Each step of visual information refinement identifies specific visual rationales that support answers to complex visual reasoning questions. Beyond just using textual CoT, IoT simultaneously utilizes visual and textual rationales to help MLLMs better understand the complex multimodal information.
The researchers show that IoT prompting improves zero-shot visual reasoning performance across various visual understanding tasks in different MLLM models. Additionally, the step-by-step visual feature explanations generated by IoT prompting help elucidate the visual reasoning process, aiding in analyzing the cognitive processes of large multimodal models.
Critical Analysis
The paper presents a promising approach to enhancing the multimodal reasoning capabilities of large language models. By incorporating visual rationales alongside textual ones, the IoT prompting method appears to help MLLMs tackle complex visual reasoning problems more effectively.
However, the paper does not delve into potential limitations or caveats of the proposed technique. For example, it would be valuable to understand the computational and memory overhead of the step-by-step visual feature extraction, and how this might scale as the complexity of the inputs and reasoning tasks increases.
Additionally, the paper focuses on zero-shot performance, but it would be helpful to understand how IoT prompting compares to other multimodal reasoning approaches in terms of sample efficiency and fine-tuning performance. Exploring the generalizability of the method to a wider range of datasets and task domains would also strengthen the conclusions.
Conclusion
This research represents an important step forward in advancing the state-of-the-art in multimodal chain-of-thought reasoning with large language models. By incorporating visual rationales alongside textual ones, the proposed IoT prompting method helps MLLMs better understand and reason about complex multimodal information.
The improved zero-shot visual reasoning performance and the interpretable step-by-step visual feature explanations are promising developments that could have significant implications for a wide range of applications, from visual question answering to spatial reasoning and beyond. Further research to address the potential limitations and expand the capabilities of this approach could lead to even more powerful multimodal chain-of-thought reasoning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024
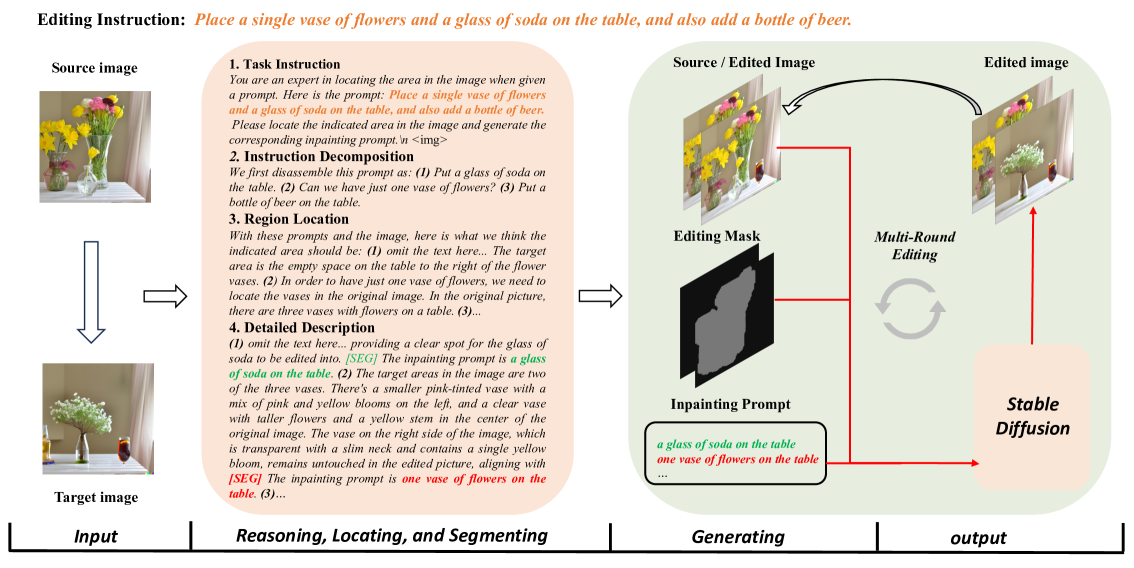
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
0
0
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
5/28/2024
💬
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, Furu Wei
0
0
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as the Mind's Eye, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (VoT) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate mental images to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.
5/27/2024

Compositional Chain-of-Thought Prompting for Large Multimodal Models
Chancharik Mitra, Brandon Huang, Trevor Darrell, Roei Herzig
0
0
The combination of strong visual backbones and Large Language Model (LLM) reasoning has led to Large Multimodal Models (LMMs) becoming the current standard for a wide range of vision and language (VL) tasks. However, recent research has shown that even the most advanced LMMs still struggle to capture aspects of compositional visual reasoning, such as attributes and relationships between objects. One solution is to utilize scene graphs (SGs)--a formalization of objects and their relations and attributes that has been extensively used as a bridge between the visual and textual domains. Yet, scene graph data requires scene graph annotations, which are expensive to collect and thus not easily scalable. Moreover, finetuning an LMM based on SG data can lead to catastrophic forgetting of the pretraining objective. To overcome this, inspired by chain-of-thought methods, we propose Compositional Chain-of-Thought (CCoT), a novel zero-shot Chain-of-Thought prompting method that utilizes SG representations in order to extract compositional knowledge from an LMM. Specifically, we first generate an SG using the LMM, and then use that SG in the prompt to produce a response. Through extensive experiments, we find that the proposed CCoT approach not only improves LMM performance on several vision and language VL compositional benchmarks but also improves the performance of several popular LMMs on general multimodal benchmarks, without the need for fine-tuning or annotated ground-truth SGs. Code: https://github.com/chancharikmitra/CCoT
4/1/2024