Imitating Cost-Constrained Behaviors in Reinforcement Learning
2403.17456
0
0
Abstract
Complex planning and scheduling problems have long been solved using various optimization or heuristic approaches. In recent years, imitation learning that aims to learn from expert demonstrations has been proposed as a viable alternative to solving these problems. Generally speaking, imitation learning is designed to learn either the reward (or preference) model or directly the behavioral policy by observing the behavior of an expert. Existing work in imitation learning and inverse reinforcement learning has focused on imitation primarily in unconstrained settings (e.g., no limit on fuel consumed by the vehicle). However, in many real-world domains, the behavior of an expert is governed not only by reward (or preference) but also by constraints. For instance, decisions on self-driving delivery vehicles are dependent not only on the route preferences/rewards (depending on past demand data) but also on the fuel in the vehicle and the time available. In such problems, imitation learning is challenging as decisions are not only dictated by the reward model but are also dependent on a cost-constrained model. In this paper, we provide multiple methods that match expert distributions in the presence of trajectory cost constraints through (a) Lagrangian-based method; (b) Meta-gradients to find a good trade-off between expected return and minimizing constraint violation; and (c) Cost-violation-based alternating gradient. We empirically show that leading imitation learning approaches imitate cost-constrained behaviors poorly and our meta-gradient-based approach achieves the best performance.
Create account to get full access
Overview
- This paper explores a reinforcement learning (RL) approach to imitating cost-constrained behaviors observed in demonstrations.
- The researchers propose a method to learn policies that match the cost-constrained behaviors in the demonstrations while also optimizing for reward.
- The method involves jointly learning the cost function and policy from the demonstrations, allowing the agent to balance reward maximization with cost minimization.
Plain English Explanation
In this research, the scientists looked at a way for AI systems to learn how to behave by imitating examples they're shown, but with an added twist. The examples didn't just show the best way to achieve a goal, but also had constraints on the "cost" of the actions taken - things like time, energy, or resources used.
The researchers developed a method that allows the AI to learn both the overall goal it should try to achieve, as well as the specific constraints it needs to follow to get there. This lets the AI system balance maximizing the reward (or achieving the goal) with minimizing the costs involved.
For example, imagine teaching a robot to navigate a room and pick up an object. The demonstrations might not only show the optimal path, but also constraints like avoiding bumping into walls or using the least amount of power. The AI system would then learn both the goal of picking up the object, as well as the cost-saving strategies from the examples.
This approach is useful because in the real world, we often have to consider tradeoffs and constraints when deciding how to act, not just the end result we want. By incorporating these constraints into the learning process, the AI can generate behaviors that are not only effective, but also efficient and aligned with the demonstrated examples.
Technical Explanation
The key innovation in this paper is a method for Imitating Cost-Constrained Behaviors in Reinforcement Learning. The researchers propose a framework that jointly learns the cost function and policy from demonstration data, allowing the agent to optimize for both reward and cost-constrained behavior.
The approach is based on the Constrained Markov Decision Process (CMDP) formulation, which extends the standard MDP by introducing a cost function in addition to the reward function. The agent's objective is to maximize the expected cumulative reward while satisfying constraints on the expected cumulative cost.
To solve this problem, the authors develop an Imitation Learning approach that leverages Conservative World Models to learn cost-constrained policies that match the demonstrated behaviors. This involves jointly optimizing the cost function and policy parameters using an adversarial training procedure.
The proposed method is evaluated on several continuous control tasks, where the agent must learn to imitate the demonstrated behaviors while satisfying cost constraints. The results show that the approach can successfully learn cost-constrained policies that closely match the demonstrated behaviors, outperforming baselines that do not account for the cost constraints.
Critical Analysis
The paper presents a novel and promising approach for imitating cost-constrained behaviors in reinforcement learning. By jointly learning the cost function and policy, the method can effectively balance reward maximization with cost minimization, leading to more practical and realistic behaviors.
One potential limitation is the reliance on access to demonstration data that includes information about the cost constraints. In many real-world scenarios, such detailed demonstrations may not be available, and the method may need to be adapted to work with more limited supervision.
Additionally, the paper does not explore the scalability of the approach to more complex environments or higher-dimensional state and action spaces. Further research may be needed to understand how the method performs in more challenging settings.
Finally, the authors acknowledge that their approach assumes the cost function is stationary and known during training. In dynamic or uncertain environments, the cost function may need to be learned online or adapted over time, which could introduce additional challenges.
Despite these caveats, the Imitating Cost-Constrained Behaviors in Reinforcement Learning paper represents an important step forward in developing more realistic and practical reinforcement learning agents. The ability to imitate cost-constrained behaviors has numerous applications, from robotics and autonomous vehicles to resource-constrained decision-making in various domains.
Conclusion
This research explores a novel approach for Imitating Cost-Constrained Behaviors in Reinforcement Learning. By jointly learning the cost function and policy from demonstration data, the method enables reinforcement learning agents to balance reward maximization with cost minimization, leading to more realistic and practical behaviors.
The proposed framework builds on the Constrained Markov Decision Process (CMDP) formulation and leverages Imitation Learning techniques, including Conservative World Models, to effectively learn cost-constrained policies.
The approach has the potential to significantly advance the field of reinforcement learning by enabling agents to generate behaviors that are not only effective in achieving their goals, but also efficient and aligned with demonstrated examples. This could have far-reaching implications for a wide range of applications, from robotics and autonomous systems to resource-constrained decision-making in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Hybrid Inverse Reinforcement Learning
Juntao Ren, Gokul Swamy, Zhiwei Steven Wu, J. Andrew Bagnell, Sanjiban Choudhury
0
0
The inverse reinforcement learning approach to imitation learning is a double-edged sword. On the one hand, it can enable learning from a smaller number of expert demonstrations with more robustness to error compounding than behavioral cloning approaches. On the other hand, it requires that the learner repeatedly solve a computationally expensive reinforcement learning (RL) problem. Often, much of this computation is wasted searching over policies very dissimilar to the expert's. In this work, we propose using hybrid RL -- training on a mixture of online and expert data -- to curtail unnecessary exploration. Intuitively, the expert data focuses the learner on good states during training, which reduces the amount of exploration required to compute a strong policy. Notably, such an approach doesn't need the ability to reset the learner to arbitrary states in the environment, a requirement of prior work in efficient inverse RL. More formally, we derive a reduction from inverse RL to expert-competitive RL (rather than globally optimal RL) that allows us to dramatically reduce interaction during the inner policy search loop while maintaining the benefits of the IRL approach. This allows us to derive both model-free and model-based hybrid inverse RL algorithms with strong policy performance guarantees. Empirically, we find that our approaches are significantly more sample efficient than standard inverse RL and several other baselines on a suite of continuous control tasks.
6/6/2024
🌀
Efficient Imitation Learning with Conservative World Models
Victor Kolev, Rafael Rafailov, Kyle Hatch, Jiajun Wu, Chelsea Finn
0
0
We tackle the problem of policy learning from expert demonstrations without a reward function. A central challenge in this space is that these policies fail upon deployment due to issues of distributional shift, environment stochasticity, or compounding errors. Adversarial imitation learning alleviates this issue but requires additional on-policy training samples for stability, which presents a challenge in realistic domains due to inefficient learning and high sample complexity. One approach to this issue is to learn a world model of the environment, and use synthetic data for policy training. While successful in prior works, we argue that this is sub-optimal due to additional distribution shifts between the learned model and the real environment. Instead, we re-frame imitation learning as a fine-tuning problem, rather than a pure reinforcement learning one. Drawing theoretical connections to offline RL and fine-tuning algorithms, we argue that standard online world model algorithms are not well suited to the imitation learning problem. We derive a principled conservative optimization bound and demonstrate empirically that it leads to improved performance on two very challenging manipulation environments from high-dimensional raw pixel observations. We set a new state-of-the-art performance on the Franka Kitchen environment from images, requiring only 10 demos on no reward labels, as well as solving a complex dexterity manipulation task.
5/24/2024
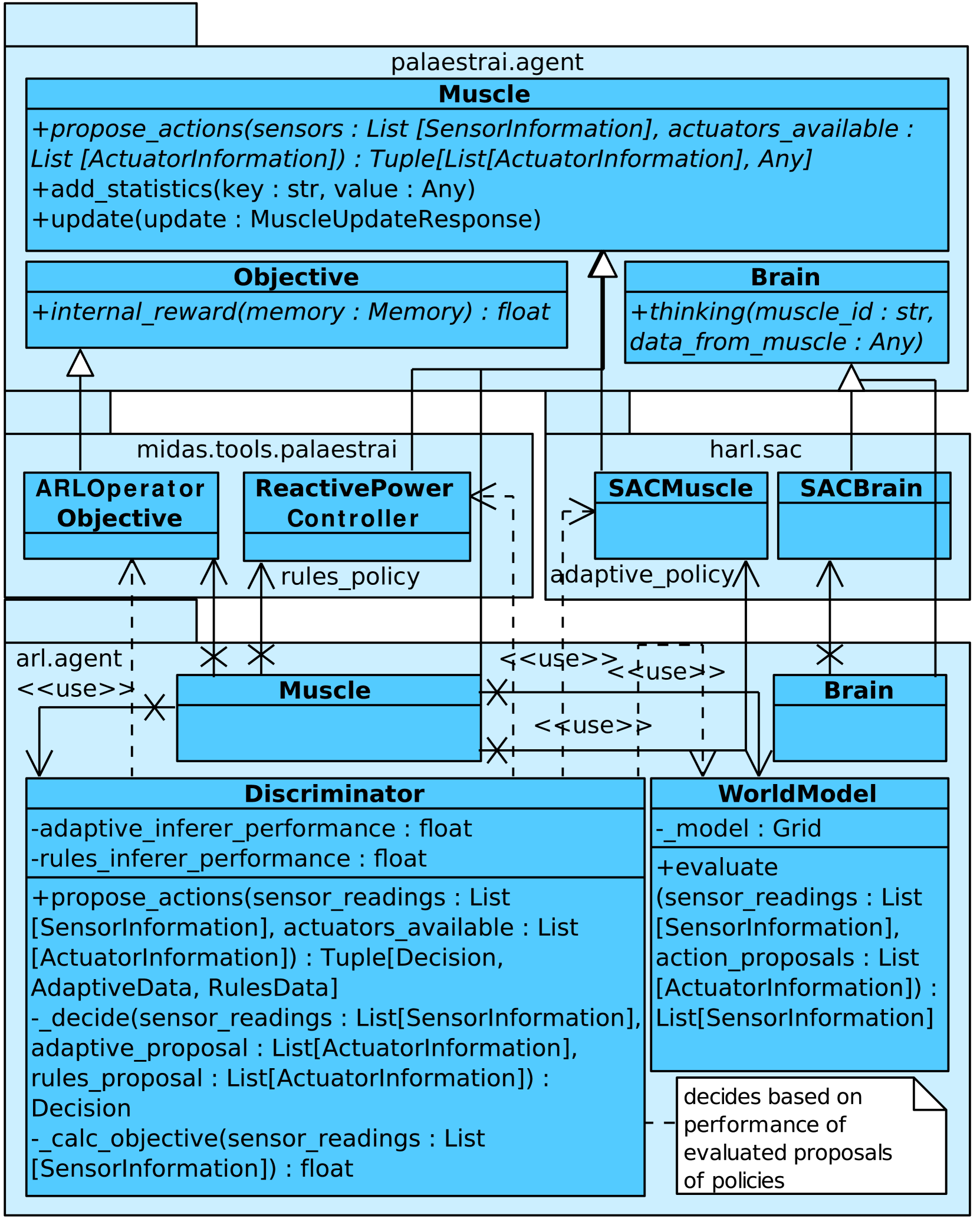
Imitation Game: A Model-based and Imitation Learning Deep Reinforcement Learning Hybrid
Eric MSP Veith, Torben Logemann, Aleksandr Berezin, Arlena Well{ss}ow, Stephan Balduin
0
0
Autonomous and learning systems based on Deep Reinforcement Learning have firmly established themselves as a foundation for approaches to creating resilient and efficient Cyber-Physical Energy Systems. However, most current approaches suffer from two distinct problems: Modern model-free algorithms such as Soft Actor Critic need a high number of samples to learn a meaningful policy, as well as a fallback to ward against concept drifts (e. g., catastrophic forgetting). In this paper, we present the work in progress towards a hybrid agent architecture that combines model-based Deep Reinforcement Learning with imitation learning to overcome both problems.
4/3/2024

Towards Imitation Learning in Real World Unstructured Social Mini-Games in Pedestrian Crowds
Rohan Chandra, Haresh Karnan, Negar Mehr, Peter Stone, Joydeep Biswas
0
0
Imitation Learning (IL) strategies are used to generate policies for robot motion planning and navigation by learning from human trajectories. Recently, there has been a lot of excitement in applying IL in social interactions arising in urban environments such as university campuses, restaurants, grocery stores, and hospitals. However, obtaining numerous expert demonstrations in social settings might be expensive, risky, or even impossible. Current approaches therefore, focus only on simulated social interaction scenarios. This raises the question: textit{How can a robot learn to imitate an expert demonstrator from real world multi-agent social interaction scenarios}? It remains unknown which, if any, IL methods perform well and what assumptions they require. We benchmark representative IL methods in real world social interaction scenarios on a motion planning task, using a novel pedestrian intersection dataset collected at the University of Texas at Austin campus. Our evaluation reveals two key findings: first, learning multi-agent cost functions is required for learning the diverse behavior modes of agents in tightly coupled interactions and second, conditioning the training of IL methods on partial state information or providing global information in simulation can improve imitation learning, especially in real world social interaction scenarios.
5/28/2024